Scrapy 入門學習筆記(1) -- Scrapy 項目搭建與架構介紹
最近學習用 Scrapy 框架寫爬蟲,簡單來說爬蟲就是從網上抓取網頁,解析網頁,然后進行數據的存儲與分析,將從網頁的解析到數據的轉換存儲。將學習過程中用到的解析技術,Scrapy 的各個模塊使用與進階到分布式爬蟲學到的知識點、遇到的問題以及解決方法記錄于此,以作總結與備忘,也希望對需要的同學有所幫助。
本篇文章作為開篇,主要介紹 Scrapy 項目以及爬蟲的創建,也簡要概述了 Scrapy 項目各個部分的作用以及大致的執行流程。
一. Scrapy 項目創建與介紹
首先是 Scrapy 的安裝,這里直接使用 pip 進行安裝即可
pip install scrapy安裝完成后就可以使用 scrapy 命令來創建項目了,如下:
scrapy startproject FirstSpider上面的命令只是生成了一個 Scrapy 項目,之后還需要創建爬蟲才能爬取,創建爬蟲的命令如下:
scrapy genspider stack http://stackoverflow.com/使用 scrapy genspider 來創建一個爬蟲,并且指定名稱為 stack, 起始爬取路徑為 http://stackoverflow.com/
創建完成后的項目目錄結構如下:
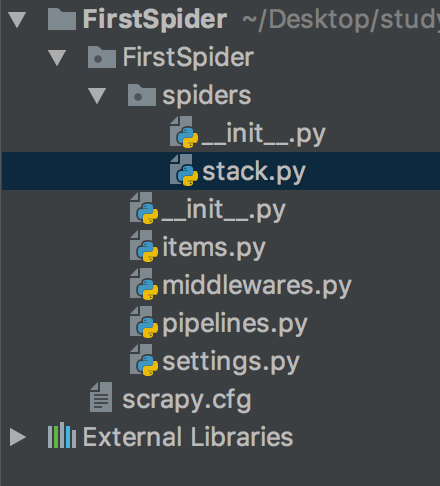
可以看到在項目目錄下會有一個與項目名同名的 FirstSpider 包,里面是我們 Scrapy 項目的各個模塊。下面對項目的每個部分做簡要解釋:
- spiders/
顧名思義就是爬蟲的 package。我們創建的爬蟲文件都會自動生成在該 package 下, 可以看到之前創建的 stack 已經在這里了。
- items.py
用來存放 Item 類的文件,Item 類可以理解為數據的中轉類,我們爬取網頁后需要將進行解析,并將解析后的數據進行存儲分析。為了便于數據的遷移存儲,我們可以將數據封裝為一個 Item 類,然后在對 Item 類進行操作,這樣可以避免很多不必要的錯誤。
- middlewares.py
中間層文件, Scrapy 自帶的 middleware 可以分為 spider middleware 和 downloader middleware 兩類, 我們也可以自定義 middleware 類。我們爬取網頁的網絡請求和響應都會經過 middleware 進行處理, 因此可以在這里做一些個性化的操作,比如設置用戶代理,設置代理 IP 等。
- piplines.py
用來處理保存數據的模塊,我們爬取網頁后解析生成的 Item 類會被傳遞到這里進行存儲解析等操作。 Scrapy 提供了許多有用的 Pipeline 類來處理數據,我們也可以自定義 Pipeline 類進行處理。
- settings
Scrapy 項目的配置文件,對整個項目進行設置。比如設置請求和響應的中間層,指定操作數據的 Pipeline 類等。
介紹完了各個模塊之后讓我們在看一下剛才創建的爬蟲文件,其源代碼如下:
import scrapy
class StackSpider(scrapy.Spider):
name = "stack"
allowed_domains = ["http://stackoverflow.com/"]
start_urls = ['https://www.baidu.com/']
# 默認的解析方法,可以自己定義其他解析方法解析對應的請求
def parse(self, response):
html = response.text
print(html)
pass
# 指定起始請求,生成一個 scrapy.Request() 請求對象
def start_requests(self):
yield scrapy.Request(url='http://stackoverflow.com/', callback=self.parse)可以看到我們指定的爬蟲名和起始 url 都在里面。默認生成的代碼是沒有 start_requests 方法的,我們在命令中添加的起始網址會被聲明為 start_urls 中的元素。Scrapy 將 start_urls 中的 url 作為起始路徑進行爬取。除此之外我們可以重寫 Scrapy 提供的 start_requests() 方法來發送 scrapy.Request 請求自行設定。
如代碼中所示,我們自定義了 start_requests 方法生成了一個 scrapy.Request 請求,并指定了請求 url 和回調函數,callback 默認值是調用 parse 方法,我們也可以自定義其他解析方法來針對不同的網頁爬取請求做解析。
之后就是執行爬蟲進行爬取了,其命令 為 scrapy crawl + 爬蟲名,如下:
scrapy crawl stack
爬取成功后會將 response 對象傳遞到我們指定的解析方法中進行解析,這樣一個爬蟲就創建運行成功了。如代碼所示,我們獲取了 response.text 屬性,會返回其頁面的 HTML 代碼。
通過網頁解析的技術我們可以獲取頁面中任何我們需要的數據,關于解析的技術將在下一篇文章中講解,現在簡要講解下 Scrapy 的架構以及執行流程,結合前面各個模塊的講解幫助大家對 Scrapy 有個宏觀的印象,便于后面的學習。
二. Scrapy 爬蟲執行流程概述
Scrapy 架構圖如下:
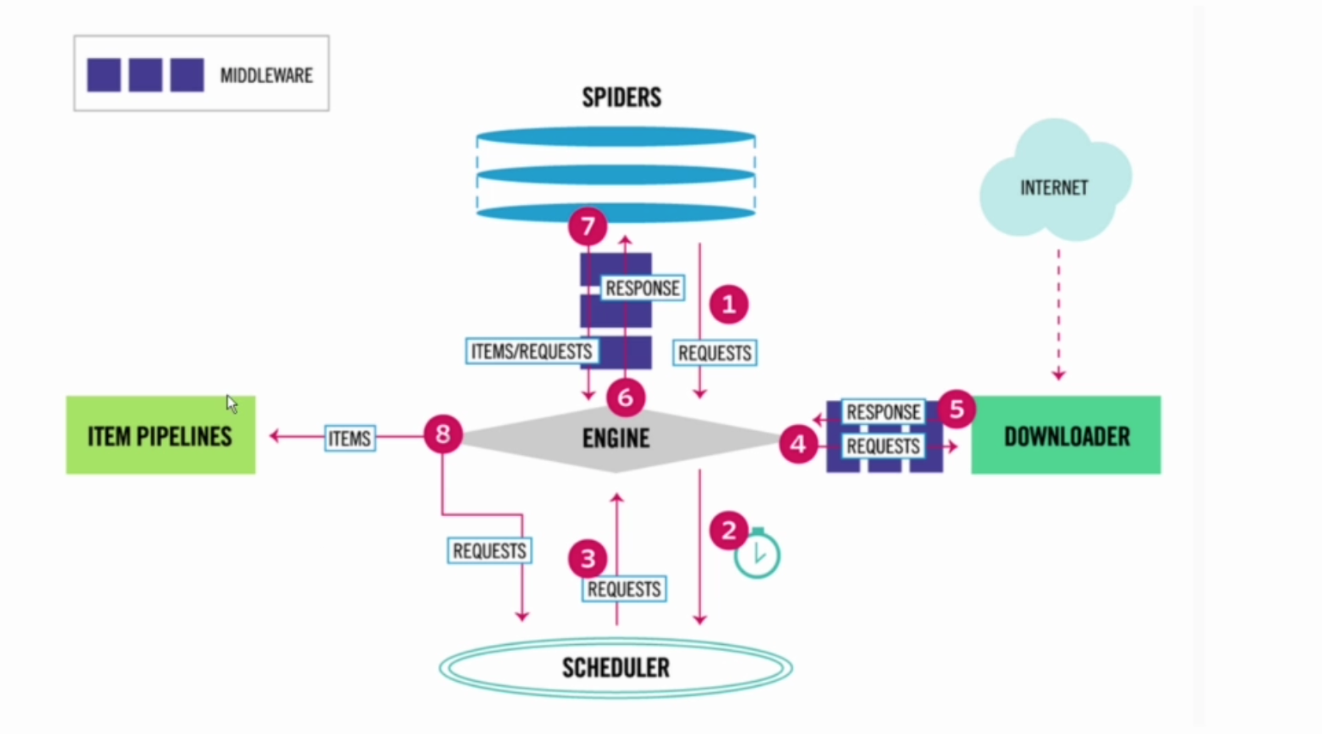
從上面的架構圖中可以看到我們熟悉的幾個模塊,包括 Spiders、Item、middleware、pipeline 模塊。另外還多了 ENGIN 引擎、SCHEDULER 和 DOWNLOADER 下載模塊。
下面結合圖中的各個流程做簡要講解:
- Spider 爬蟲部分發送請求,通過 spidermiddleware 中間層處理后發送給 ENGINE 引擎模塊
- 引擎模塊將請求發送給 SCHEDULER 模塊進行調度
- SCHEDULER 模塊將可以執行的請求調度給引擎模塊
- 引擎模塊將請求發送給 DOWNLOADER 下載模塊進行下載,期間會經過 download middleware 進行處理
- 下載模塊將爬取好的網頁響應經過 downloadermiddleware 中間層處理后傳遞給引擎模塊
- 引擎模塊將響應傳遞給 Spider 爬蟲模塊
- 在爬蟲模塊我們自定義解析方式對響應解析完成后生成 Item 對象或者新的 Request對象,經過 spiddermiddleware 發送給引擎模塊
- 如果是 Item 對象傳遞給 item 和 pipeline 來進行對應的處理; 如果是 Request 對象則繼續調度下載,重復之前的步驟。
上面就是整個 Scrapy 的執行流程了,了解了大致的流程后,后面就是對各個流程中的知識點進行學習了,包括網頁的解析,請求響應的中間層處理,item 與 pipeline 對數據的處理以及可能遇到的問題以及解決方案,將在后面的文章中逐個講解,梳理內容,鞏固所學,也希望對需要的同學有所幫助。
智能推薦

Scrapy
1. scrapy的概念 Scrapy是一個為了爬取網站數據,提取結構性數據而編寫的應用框架,我們只需要實現少量的代碼,就能夠快速的抓取。 Scrapy 使用了Twisted['tw?st?d]異步網絡框架,可以加快我們的下載速度。 Scrapy文檔地址:http://scrapy-chs.readthedocs.io/zh_CN/1.0/intro/overview.html 2. scrapy...
scrapy
基礎 1.scrapy安裝與環境依賴 2.創建項目 3.項目目錄介紹 說明: 4.scrapy框架介紹: 5大核心組件與數據流向 5.使用scrapy框架爬取糗百 要先在settings中開啟pipline 6.scrapy爬取校花網人名與圖片下載鏈接 詳情 1.scrapy 多頁爬取 2.scrapy爬取詳情頁 3.scrapy發送post請求 4.scrapy中間件 5.下載中間件實現UA池 ...
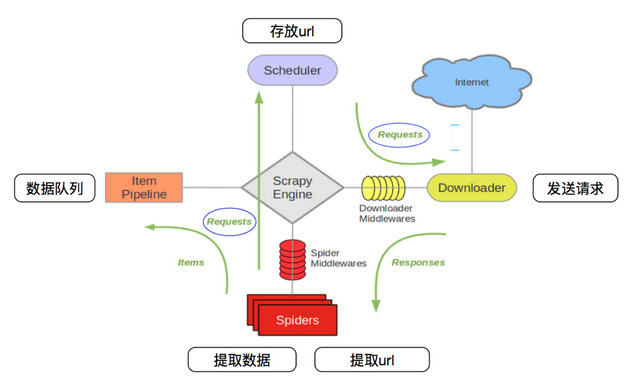
scrapy
1、scrapy的工作流程 其流程可以描述如下: 調度器把requests-->引擎-->下載中間件--->下載器 下載器發送請求,獲取響應---->下載中間件---->引擎--->爬蟲中間件--->爬蟲 爬蟲提取url地址,組裝成request對象---->爬蟲中間件--->引擎--->調度器 爬蟲提取數據--->引擎--->...

猜你喜歡

freemarker + ItextRender 根據模板生成PDF文件
1. 制作模板 2. 獲取模板,并將所獲取的數據加載生成html文件 2. 生成PDF文件 其中由兩個地方需要注意,都是關于獲取文件路徑的問題,由于項目部署的時候是打包成jar包形式,所以在開發過程中時直接安照傳統的獲取方法沒有一點文件,但是當打包后部署,總是出錯。于是參考網上文章,先將文件讀出來到項目的臨時目錄下,然后再按正常方式加載該臨時文件; 還有一個問題至今沒有解決,就是關于生成PDF文件...
電腦空間不夠了?教你一個小秒招快速清理 Docker 占用的磁盤空間!
Docker 很占用空間,每當我們運行容器、拉取鏡像、部署應用、構建自己的鏡像時,我們的磁盤空間會被大量占用。 如果你也被這個問題所困擾,咱們就一起看一下 Docker 是如何使用磁盤空間的,以及如何回收。 docker 占用的空間可以通過下面的命令查看: TYPE 列出了docker 使用磁盤的 4 種類型: Images:所有鏡像占用的空間,包括拉取下來的鏡像,和本地構建的。 Con...

requests實現全自動PPT模板
http://www.1ppt.com/moban/ 可以免費的下載PPT模板,當然如果要人工一個個下,還是挺麻煩的,我們可以利用requests輕松下載 訪問這個主頁,我們可以看到下面的樣式 點每一個PPT模板的圖片,我們可以進入到詳細的信息頁面,翻到下面,我們可以看到對應的下載地址 點擊這個下載的按鈕,我們便可以下載對應的PPT壓縮包 那我們就開始做吧 首先,查看網頁的源代碼,我們可以看到每一...


Linux C系統編程-線程互斥鎖(四)
互斥鎖 互斥鎖也是屬于線程之間處理同步互斥方式,有上鎖/解鎖兩種狀態。 互斥鎖函數接口 1)初始化互斥鎖 pthread_mutex_init() man 3 pthread_mutex_init (找不到的情況下首先 sudo apt-get install glibc-doc sudo apt-get install manpages-posix-dev) 動態初始化 int pthread_...