詳細分析DataX源碼,剖析流程結構
DataX類圖
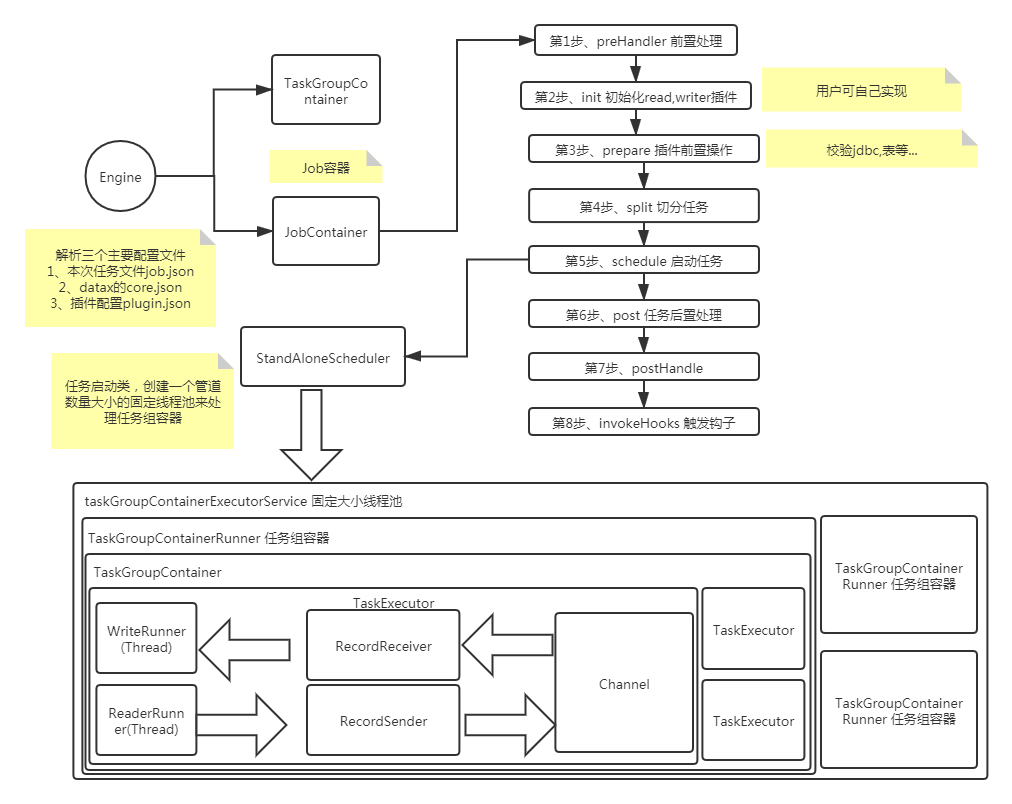
整個流程大致如下
先看下官方的介紹,了解下功能和結構。再進行源碼的剖析
DataX 是一個異構數據源離線同步工具,致力于實現包括關系型數據庫(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各種異構數據源之間穩定高效的數據同步功能
DataX本身作為離線數據同步框架,采用Framework + plugin架構構建。將數據源讀取和寫入抽象成為Reader/Writer插件,納入到整個同步框架中。
Reader:Reader為數據采集模塊,負責采集數據源的數據,將數據發送給Framework。
Writer: Writer為數據寫入模塊,負責不斷向Framework取數據,并將數據寫入到目的端。
Framework:Framework用于連接reader和writer,作為兩者的數據傳輸通道,并處理緩沖,流控,并發,數據轉換等核心技術問題。
DataX3.0核心架構
DataX 3.0 開源版本支持單機多線程模式完成同步作業運行,按一個DataX作業生命周期的時序圖,從整體架構設計非常簡要說明DataX各個模塊相互關系
核心模塊
DataX完成單個數據同步的作業,我們稱之為Job,DataX接受到一個Job之后,將啟動一個進程來完成整個作業同步過程。DataX Job模塊是單個作業的中樞管理節點,承擔了數據清理、子任務切分(將單一作業計算轉化為多個子Task)、TaskGroup管理等功能。
DataXJob啟動后,會根據不同的源端切分策略,將Job切分成多個小的Task(子任務),以便于并發執行。Task便是DataX作業的最小單元,每一個Task都會負責一部分數據的同步工作。
切分多個Task之后,DataX Job會調用Scheduler模塊,根據配置的并發數據量,將拆分成的Task重新組合,組裝成TaskGroup(任務組)。每一個TaskGroup負責以一定的并發運行完畢分配好的所有Task,默認單個任務組的并發數量為5。
每一個Task都由TaskGroup負責啟動,Task啟動后,會固定啟動Reader—>Channel—>Writer的線程來完成任務同步工作。
DataX作業運行起來之后, Job監控并等待多個TaskGroup模塊任務完成,等待所有TaskGroup任務完成后Job成功退出。否則,異常退出,進程退出值非0
DataX任務切分
例如用戶提交了一個DataX作業,并且配置了10個并發,目的是將一個100張分表的mysql數據同步到目標庫。 任務切分過程:
DataXJob根據分庫分表切分成了100個Task。
根據10個并發,每個TaskGroup默認執行5個task(TaskGroup執行task數量可以設置)DataX計算共需要分配2個TaskGroup。
2個TaskGroup平分切分好的100個Task,每一個TaskGroup負責以5個并發共計運行50個Task
源碼剖析
任務執行的入口類為Engine
public static void main(String[] args) throws Exception {
/**
* 入參參數
* -mode standalone
* -jobid -1
* -job E:\\workspace\\datax\\job\\job1.json
*/
String[] param = {"-mode", "standalone", "-jobid", "-1", "-job", "E:\\workspace\\datax\\job\\job1.json"};
System.setProperty("datax.home", "E:\\workspace\\DataX-master\\core\\src\\main");
args = param;
int exitCode = 0;
try {
Engine.entry(args);
} catch (Throwable e) {
}
}
Job的核心配置主要包括三個配置
core.json DataX核心配置
job.json 本次任務配置
plugin.json 本次任務使用到read , write 插件配置
Engine#entry
1、解析命令行參數 -mode -jobid -job 獲取jobid, 和job配置文件路徑,執行模式(standalone, local, Distrubuted)
2、解析本次任務配置,創建新的Engine,執行start()方法
public static void entry(final String[] args) throws Throwable {
Options options = new Options();
options.addOption("job", true, "Job config.");
options.addOption("jobid", true, "Job unique id.");
options.addOption("mode", true, "Job runtime mode.");
BasicParser parser = new BasicParser();
CommandLine cl = parser.parse(options, args); //解析命令參數
String jobPath = cl.getOptionValue("job");
// 如果用戶沒有明確指定jobid, 則 datax.py 會指定 jobid 默認值為-1
String jobIdString = cl.getOptionValue("jobid");
RUNTIME_MODE = cl.getOptionValue("mode");
/**
* 解析本次job配置
* Configuration 包括3部分
* 1、job.json 任務配置
* 2. core.json DataX配置
* 3. plugin.json 插件配置,例如插件類路徑...
*/
Configuration configuration = ConfigParser.parse(jobPath);
long jobId;
if (!"-1".equalsIgnoreCase(jobIdString)) {
jobId = Long.parseLong(jobIdString);
} else {
// only for dsc & ds & datax 3 update
String dscJobUrlPatternString = "/instance/(\\d{1,})/config.xml";
String dsJobUrlPatternString = "/inner/job/(\\d{1,})/config";
String dsTaskGroupUrlPatternString = "/inner/job/(\\d{1,})/taskGroup/";
List<String> patternStringList = Arrays.asList(dscJobUrlPatternString,
dsJobUrlPatternString, dsTaskGroupUrlPatternString);
jobId = parseJobIdFromUrl(patternStringList, jobPath);
}
boolean isStandAloneMode = "standalone".equalsIgnoreCase(RUNTIME_MODE);
if (!isStandAloneMode && jobId == -1) {
// 如果不是 standalone 模式,那么 jobId 一定不能為-1
throw DataXException.asDataXException(FrameworkErrorCode.CONFIG_ERROR, "非 standalone 模式必須在 URL 中提供有效的 jobId.");
}
configuration.set(CoreConstant.DATAX_CORE_CONTAINER_JOB_ID, jobId);
//打印vmInfo
VMInfo vmInfo = VMInfo.getVmInfo();
if (vmInfo != null) {
LOG.info(vmInfo.toString());
}
LOG.info("\n" + Engine.filterJobConfiguration(configuration) + "\n");
LOG.debug(configuration.toJSON());
ConfigurationValidate.doValidate(configuration);
Engine engine = new Engine();
//通過配置創建一個JobContainer對象.執行start方法
engine.start(configuration);
}
Engine#start
1、首先綁定下列轉換信息,比如時間格式,時區,編碼等,在core.json中的common.column配置項
2、設置插件配置
3、創建JobContainer ,并且啟動
public void start(Configuration allConf) {
// 綁定column轉換信息 時間格式,時區,編碼等,在core.json中的common.column配置項
ColumnCast.bind(allConf);
//初始化PluginLoader,可以獲取各種插件配置
LoadUtil.bind(allConf);
//core.container.model 容器模式,默認是job
boolean isJob = !("taskGroup".equalsIgnoreCase(allConf
.getString(CoreConstant.DATAX_CORE_CONTAINER_MODEL)));
//JobContainer會在schedule后再行進行設置和調整值
int channelNumber =0;
AbstractContainer container;
long instanceId;
int taskGroupId = -1;
if (isJob) {
allConf.set(CoreConstant.DATAX_CORE_CONTAINER_JOB_MODE, RUNTIME_MODE);
container = new JobContainer(allConf);
instanceId = allConf.getLong(
CoreConstant.DATAX_CORE_CONTAINER_JOB_ID, 0);
?
} else {
container = new TaskGroupContainer(allConf);
instanceId = allConf.getLong(
CoreConstant.DATAX_CORE_CONTAINER_JOB_ID);
taskGroupId = allConf.getInt(
CoreConstant.DATAX_CORE_CONTAINER_TASKGROUP_ID);
channelNumber = allConf.getInt(
CoreConstant.DATAX_CORE_CONTAINER_TASKGROUP_CHANNEL);
}
//缺省打開perfTrace
boolean traceEnable = allConf.getBool(CoreConstant.DATAX_CORE_CONTAINER_TRACE_ENABLE, true);
boolean perfReportEnable = allConf.getBool(CoreConstant.DATAX_CORE_REPORT_DATAX_PERFLOG, true);
//standlone模式的datax shell任務不進行匯報
if(instanceId == -1){
perfReportEnable = false;
}
int priority = 0;
try {
priority = Integer.parseInt(System.getenv("SKYNET_PRIORITY"));
}catch (NumberFormatException e){
LOG.warn("prioriy set to 0, because NumberFormatException, the value is: "+System.getProperty("PROIORY"));
}
Configuration jobInfoConfig = allConf.getConfiguration(CoreConstant.DATAX_JOB_JOBINFO);
//初始化PerfTrace
PerfTrace perfTrace = PerfTrace.getInstance(isJob, instanceId, taskGroupId, priority, traceEnable);
perfTrace.setJobInfo(jobInfoConfig,perfReportEnable,channelNumber);
/**
* JobContainer.start方法是整個框架核心,
* 依次執行job的#preHandler,#init,#prepare,#split,#schedule,#post,#postHandler方法
* 最重要的是#init,#split,#schedule
*/
container.start();
}
JobContainer#start
任務容器啟動器
preHandler 前置操作,加載job插件等 . (未使用到)
init 初始化read , write 插件。 這個過程會對數據源,表,列進行校驗
initJobWriter
private void init() {
//..省略部分代碼
//必須先Reader ,后Writer
this.jobReader = this.initJobReader(jobPluginCollector);
this.jobWriter = this.initJobWriter(jobPluginCollector);
}
initJobReader、initJobWriter 初始化插件中,使用了URLCloassLoader對插件類進行加載。解決了類沖突的問題。因此用戶可以使用自己的類/jar包自定義插件。
jobReader.init()
private Reader.Job initJobReader(
JobPluginCollector jobPluginCollector) {
//獲取讀插件名稱
this.readerPluginName = this.configuration.getString(
CoreConstant.DATAX_JOB_CONTENT_READER_NAME); //job.content[0].reader.name
//根據讀插件類名稱,加載插件的lib包加載到jvm中
classLoaderSwapper.setCurrentThreadClassLoader(LoadUtil.getJarLoader(
PluginType.READER, this.readerPluginName)); //重置插件jar classLoader
//創建一個讀對象
Reader.Job jobReader = (Reader.Job) LoadUtil.loadJobPlugin(
PluginType.READER, this.readerPluginName);
// 設置reader的jobConfig
jobReader.setPluginJobConf(this.configuration.getConfiguration(
CoreConstant.DATAX_JOB_CONTENT_READER_PARAMETER));
// 設置reader的readerConfig
jobReader.setPeerPluginJobConf(this.configuration.getConfiguration(
CoreConstant.DATAX_JOB_CONTENT_WRITER_PARAMETER));
jobReader.setJobPluginCollector(jobPluginCollector);
jobReader.init(); //讀插件初始化(可以見具體讀插件實現類,例如MysqlReader)
//重置回歸原classLoader
classLoaderSwapper.restoreCurrentThreadClassLoader();
return jobReader;
}
?
以MysqlReader為例jobReader#init
public static class Job extends Reader.Job {
///...省略其他代碼
@Override
public void init() {
this.originalConfig = super.getPluginJobConf(); //Job配置
Integer userConfigedFetchSize = this.originalConfig.getInt(Constant.FETCH_SIZE);
if (userConfigedFetchSize != null) {
LOG.warn("對 mysqlreader 不需要配置 fetchSize, mysqlreader 將會忽略這項配置. 如果您不想再看到此警告,請去除fetchSize 配置.");
}
this.originalConfig.set(Constant.FETCH_SIZE, Integer.MIN_VALUE);
this.commonRdbmsReaderJob = new CommonRdbmsReader.Job(DATABASE_TYPE);
this.commonRdbmsReaderJob.init(this.originalConfig);
}
///...省略其他代碼
}
以MysqlWriter為例
jobWriter.init();
private Writer.Job initJobWriter(
JobPluginCollector jobPluginCollector) {
this.writerPluginName = this.configuration.getString(
CoreConstant.DATAX_JOB_CONTENT_WRITER_NAME);
classLoaderSwapper.setCurrentThreadClassLoader(LoadUtil.getJarLoader(
PluginType.WRITER, this.writerPluginName));
Writer.Job jobWriter = (Writer.Job) LoadUtil.loadJobPlugin(
PluginType.WRITER, this.writerPluginName);
//...省略部分代碼
jobWriter.init();
classLoaderSwapper.restoreCurrentThreadClassLoader();
return jobWriter;
}
jobWriter#init
public static class Job extends Writer.Job {
//...省略部分代碼
@Override
public void init() {
this.originalConfig = super.getPluginJobConf();
this.commonRdbmsWriterJob = new CommonRdbmsWriter.Job(DATABASE_TYPE);
this.commonRdbmsWriterJob.init(this.originalConfig);
}
}
prepare read, write插件做一些前置操作
實現為具體插件類的prepare方法
split 任務拆分
schedule 首先完成的工作是把上一步reader和writer split的結果整合到具體taskGroupContainer中,同時不同的執行模式調用不同的調度策略,將所有任務調度起來
/**
* 執行reader和writer最細粒度的切分,需要注意的是,writer的切分結果要參照reader的切分結果,
* 達到切分后數目相等,才能滿足1:1的通道模型,所以這里可以將reader和writer的配置整合到一起,
* 然后,為避免順序給讀寫端帶來長尾影響,將整合的結果shuffler掉
*/
private int split() {
//設置channel數量
this.adjustChannelNumber();
if (this.needChannelNumber <= 0) {
this.needChannelNumber = 1;
}
List<Configuration> readerTaskConfigs = this
.doReaderSplit(this.needChannelNumber);
int taskNumber = readerTaskConfigs.size();
List<Configuration> writerTaskConfigs = this
.doWriterSplit(taskNumber);
//job.content[0].transformer
List<Configuration> transformerList = this.configuration.getListConfiguration(CoreConstant.DATAX_JOB_CONTENT_TRANSFORMER);
//合并讀任務配置、寫任務配置、transformer配置
//輸入是reader和writer的parameter list,輸出是content下面元素的list
List<Configuration> contentConfig = mergeReaderAndWriterTaskConfigs(
readerTaskConfigs, writerTaskConfigs, transformerList);
//job.content 合并后的總配置
this.configuration.set(CoreConstant.DATAX_JOB_CONTENT, contentConfig);
return contentConfig.size();
}
設置管道數量 adjustChannelNumber()
1、配置 job.setting.speed.byte (jobByte), 則必須設置 core.transport.channel.speed.byte (coreByte) ,channelNumber = coreByte / jobByte > 0 ? coreByte / jobByte : 1
2、配置job.setting.speed.record (jobRecord) , 則必須配置core.transport.channel.speed.record(coreRecord)
channelNumber = coreRecord/ jobRecord> 0 ? coreRecord/ jobRecord: 1
如果上面2個任意配置了一個或2個,取較小值為channelNumber ,如果沒有配置。則必須要配置job.setting.speed.channel 作為管道數量
下面切分讀任務和寫任務,最后把讀寫任務配置合并
#doReaderSplit 讀切分任務是read插件實現的
我這里使用的是mysqlreader 插件,最后還是引用的框架的split實現
public List<Configuration> split(int adviceNumber) {
return this.commonRdbmsReaderJob.split(this.originalConfig, adviceNumber);
}
#doWriterSplit寫切分任務
寫切分任務數量是根據讀切分后的數量而來,寫任務必須與讀任務數一致
private List<Configuration> doWriterSplit(int readerTaskNumber) {
classLoaderSwapper.setCurrentThreadClassLoader(LoadUtil.getJarLoader(
PluginType.WRITER, this.writerPluginName));
?
List<Configuration> writerSlicesConfigs = this.jobWriter
.split(readerTaskNumber);
if (writerSlicesConfigs == null || writerSlicesConfigs.size() <= 0) {
throw DataXException.asDataXException(
FrameworkErrorCode.PLUGIN_SPLIT_ERROR,
"writer切分的task不能小于等于0");
}
classLoaderSwapper.restoreCurrentThreadClassLoader();
return writerSlicesConfigs;
}
public List<Configuration> split(int mandatoryNumber) {
return this.commonRdbmsWriterJob.split(this.originalConfig, mandatoryNumber);
}
切分讀任務:
1、table模式 :當沒有配置splitPk時,任務數量與table數量一樣.比如table配置了2個(user_info, user_info_1) 則生成2任務個配置
2、table模式 :配置splitPk時,配合channel一起使用。任務數 = (向上取整)(channel/table數量) ,當任務數 > 1 .會重新切分任務
最終任務數 = 任務數 * 5 + 1 。 (這里程序實際根據job配置的splitPk請求了數據庫,并且把查詢出的pk范圍分別加入到每個任務的pk條件中去)。 例如user_info表pk為user_id. 最終的sql會加上 and user_id > 下限 and user_id < 上限.
3、querySql模式 :有幾條querySql , 生成相同數量的任務配置
切分寫任務
1、寫單表的時,生成tabel表數量的任務 或者 querySql數量相等的任務
2、多表時,生成和表數量相同的任務
schedule執行任務
1、首先拿到任務組執行任務數量配置,再結合切分后任務數量對任務進行分組
int channelsPerTaskGroup = this.configuration.getInt(
CoreConstant.DATAX_CORE_CONTAINER_TASKGROUP_CHANNEL, 5);
int taskNumber = this.configuration.getList(
CoreConstant.DATAX_JOB_CONTENT).size();
this.needChannelNumber = Math.min(this.needChannelNumber, taskNumber);
//通過獲取配置信息得到每個taskGroup需要運行哪些tasks任務
List<Configuration> taskGroupConfigs = JobAssignUtil.assignFairly(this.configuration,
this.needChannelNumber, channelsPerTaskGroup);
2、創建任務執行器
AbstractScheduler scheduler = initStandaloneScheduler(this.configuration);
private AbstractScheduler initStandaloneScheduler(Configuration configuration) {
AbstractContainerCommunicator containerCommunicator = new StandAloneJobContainerCommunicator(configuration);
super.setContainerCommunicator(containerCommunicator);
?
return new StandAloneScheduler(containerCommunicator);
}
3、執行任務
scheduler.schedule(taskGroupConfigs); //schedule方法先獲取收集信息的屬性,比如說間隔多長時間匯報,休眠時間等
//然后開啟任務
startAllTaskGroup(configurations); //重點,這里開啟執行任務
//后面代碼是收集打印任務的匯報信息
4、創建線程池,提交任務
創建了一個與任務數量大小一致的固定線程池,滿足完成當前任務
public void startAllTaskGroup(List<Configuration> configurations) {
//創建一個任務數量大小的固定線程池
this.taskGroupContainerExecutorService = Executors
.newFixedThreadPool(configurations.size());
for (Configuration taskGroupConfiguration : configurations) {
TaskGroupContainerRunner taskGroupContainerRunner = newTaskGroupContainerRunner(taskGroupConfiguration);
this.taskGroupContainerExecutorService.execute(taskGroupContainerRunner);
}
this.taskGroupContainerExecutorService.shutdown();
}
5、容器組啟動
TaskGroupContainer類為執行任務的承載容器,重點關注
public class TaskGroupContainerRunner implements Runnable {
private TaskGroupContainer taskGroupContainer;
private State state;
public TaskGroupContainerRunner(TaskGroupContainer taskGroup) {
this.taskGroupContainer = taskGroup;
this.state = State.SUCCEEDED;
}
@Override
public void run() {
try {
Thread.currentThread().setName(
String.format("taskGroup-%d", this.taskGroupContainer.getTaskGroupId()));
this.taskGroupContainer.start(); //開始執行任務
this.state = State.SUCCEEDED;
} catch (Throwable e) {
this.state = State.FAILED;
throw DataXException.asDataXException(
FrameworkErrorCode.RUNTIME_ERROR, e);
}
}
//...
}
?
TaskGroupContainer
public class TaskGroupContainer extends AbstractContainer {
private static final Logger LOG = LoggerFactory
.getLogger(TaskGroupContainer.class);
//當前taskGroup所屬jobId
private long jobId;
//當前taskGroupId
private int taskGroupId;
//使用的channel類
private String channelClazz;
//task收集器使用的類
private String taskCollectorClass;
?
private TaskMonitor taskMonitor = TaskMonitor.getInstance();
?
public TaskGroupContainer(Configuration configuration) {
super(configuration);
initCommunicator(configuration); //初始化通信器
this.jobId = this.configuration.getLong(
CoreConstant.DATAX_CORE_CONTAINER_JOB_ID);
//core.container.taskGroup.id 任務組id
this.taskGroupId = this.configuration.getInt(
CoreConstant.DATAX_CORE_CONTAINER_TASKGROUP_ID);
//管道實現類 core.transport.channel.class
this.channelClazz = this.configuration.getString(
CoreConstant.DATAX_CORE_TRANSPORT_CHANNEL_CLASS);
//任務收集器 core.statistics.collector.plugin.taskClass
this.taskCollectorClass = this.configuration.getString(
CoreConstant.DATAX_CORE_STATISTICS_COLLECTOR_PLUGIN_TASKCLASS);
}
//...
@Override
public void start() {
try {
/**
* 狀態check時間間隔,較短,可以把任務及時分發到對應channel中
* core.container.taskGroup.sleepInterval
*/
int sleepIntervalInMillSec = this.configuration.getInt(
CoreConstant.DATAX_CORE_CONTAINER_TASKGROUP_SLEEPINTERVAL, 100);
/**
* 狀態匯報時間間隔,稍長,避免大量匯報
* core.container.taskGroup.reportInterval
*/
long reportIntervalInMillSec = this.configuration.getLong(
CoreConstant.DATAX_CORE_CONTAINER_TASKGROUP_REPORTINTERVAL,
10000);
/**
* 2分鐘匯報一次性能統計
*/
//core.container.taskGroup.channel
// 獲取channel數目
int channelNumber = this.configuration.getInt(
CoreConstant.DATAX_CORE_CONTAINER_TASKGROUP_CHANNEL);
//最大重試次數 core.container.task.failOver.maxRetryTimes 默認1次
int taskMaxRetryTimes = this.configuration.getInt(
CoreConstant.DATAX_CORE_CONTAINER_TASK_FAILOVER_MAXRETRYTIMES, 1);
//任務組重試間隔時間 core.container.task.failOver.retryIntervalInMsec
long taskRetryIntervalInMsec = this.configuration.getLong(
CoreConstant.DATAX_CORE_CONTAINER_TASK_FAILOVER_RETRYINTERVALINMSEC, 10000);
//core.container.task.failOver.maxWaitInMsec
long taskMaxWaitInMsec = this.configuration.getLong(CoreConstant.DATAX_CORE_CONTAINER_TASK_FAILOVER_MAXWAITINMSEC, 60000);
//獲取當前任務組所有任務配置
List<Configuration> taskConfigs = this.configuration
.getListConfiguration(CoreConstant.DATAX_JOB_CONTENT);
int taskCountInThisTaskGroup = taskConfigs.size();
LOG.info(String.format(
"taskGroupId=[%d] start [%d] channels for [%d] tasks.",
this.taskGroupId, channelNumber, taskCountInThisTaskGroup));
//任務組注冊通信器
this.containerCommunicator.registerCommunication(taskConfigs);
//taskId與task配置
Map<Integer, Configuration> taskConfigMap = buildTaskConfigMap(taskConfigs);
List<Configuration> taskQueue = buildRemainTasks(taskConfigs); //待運行task列表
Map<Integer, TaskExecutor> taskFailedExecutorMap = new HashMap<Integer, TaskExecutor>(); //taskId與上次失敗實例
List<TaskExecutor> runTasks = new ArrayList<TaskExecutor>(channelNumber); //正在運行task
Map<Integer, Long> taskStartTimeMap = new HashMap<Integer, Long>(); //任務開始時間
long lastReportTimeStamp = 0;
Communication lastTaskGroupContainerCommunication = new Communication();
//這里開始進入循環作業
while (true) {
//1.判斷task狀態
boolean failedOrKilled = false;
Map<Integer, Communication> communicationMap = containerCommunicator.getCommunicationMap(); //任務id對應通信器,用來收集任務作業情況
for(Map.Entry<Integer, Communication> entry : communicationMap.entrySet()){
Integer taskId = entry.getKey();
Communication taskCommunication = entry.getValue();
if(!taskCommunication.isFinished()){
continue; //當前任務未結束,繼續執行
}
//已經結束的任務,從正在運行的任務集合中移除
TaskExecutor taskExecutor = removeTask(runTasks, taskId);
//上面從runTasks里移除了,因此對應在monitor里移除
taskMonitor.removeTask(taskId);
//失敗,看task是否支持failover,重試次數未超過最大限制
if(taskCommunication.getState() == State.FAILED){
taskFailedExecutorMap.put(taskId, taskExecutor);
if(taskExecutor.supportFailOver() && taskExecutor.getAttemptCount() < taskMaxRetryTimes){
taskExecutor.shutdown(); //關閉老的executor
containerCommunicator.resetCommunication(taskId); //將task的狀態重置
Configuration taskConfig = taskConfigMap.get(taskId);
taskQueue.add(taskConfig); //重新加入任務列表
}else{
failedOrKilled = true;
break;
}
}else if(taskCommunication.getState() == State.KILLED){
failedOrKilled = true;
break;
}else if(taskCommunication.getState() == State.SUCCEEDED){
Long taskStartTime = taskStartTimeMap.get(taskId);
if(taskStartTime != null){
Long usedTime = System.currentTimeMillis() - taskStartTime;
LOG.info("taskGroup[{}] taskId[{}] is successed, used[{}]ms",
this.taskGroupId, taskId, usedTime);
//usedTime*1000*1000 轉換成PerfRecord記錄的ns,這里主要是簡單登記,進行最長任務的打印。因此增加特定靜態方法
PerfRecord.addPerfRecord(taskGroupId, taskId, PerfRecord.PHASE.TASK_TOTAL,taskStartTime, usedTime * 1000L * 1000L);
taskStartTimeMap.remove(taskId);
taskConfigMap.remove(taskId);
}
}
}
// 2.發現該taskGroup下taskExecutor的總狀態失敗則匯報錯誤
if (failedOrKilled) {
lastTaskGroupContainerCommunication = reportTaskGroupCommunication(
lastTaskGroupContainerCommunication, taskCountInThisTaskGroup);
?
throw DataXException.asDataXException(
FrameworkErrorCode.PLUGIN_RUNTIME_ERROR, lastTaskGroupContainerCommunication.getThrowable());
}
//3.有任務未執行,且正在運行的任務數小于最大通道限制
Iterator<Configuration> iterator = taskQueue.iterator();
while(iterator.hasNext() && runTasks.size() < channelNumber){
Configuration taskConfig = iterator.next();
Integer taskId = taskConfig.getInt(CoreConstant.TASK_ID);
int attemptCount = 1;
TaskExecutor lastExecutor = taskFailedExecutorMap.get(taskId);
if(lastExecutor!=null){
attemptCount = lastExecutor.getAttemptCount() + 1;
long now = System.currentTimeMillis();
long failedTime = lastExecutor.getTimeStamp();
if(now - failedTime < taskRetryIntervalInMsec){ //未到等待時間,繼續留在隊列
continue;
}
if(!lastExecutor.isShutdown()){ //上次失敗的task仍未結束
if(now - failedTime > taskMaxWaitInMsec){
markCommunicationFailed(taskId);
reportTaskGroupCommunication(lastTaskGroupContainerCommunication, taskCountInThisTaskGroup);
throw DataXException.asDataXException(CommonErrorCode.WAIT_TIME_EXCEED, "task failover等待超時");
}else{
lastExecutor.shutdown(); //再次嘗試關閉
continue;
}
}else{
LOG.info("taskGroup[{}] taskId[{}] attemptCount[{}] has already shutdown",
this.taskGroupId, taskId, lastExecutor.getAttemptCount());
}
}
Configuration taskConfigForRun = taskMaxRetryTimes > 1 ? taskConfig.clone() : taskConfig;
TaskExecutor taskExecutor = new TaskExecutor(taskConfigForRun, attemptCount);
taskStartTimeMap.put(taskId, System.currentTimeMillis());
taskExecutor.doStart();
?
iterator.remove();
runTasks.add(taskExecutor); //繼續添加到運行的任務集合
//上面,增加task到runTasks列表,因此在monitor里注冊。
taskMonitor.registerTask(taskId, this.containerCommunicator.getCommunication(taskId));
//剛剛已經添加了task,這里把任務id從失敗map移除
taskFailedExecutorMap.remove(taskId);
LOG.info("taskGroup[{}] taskId[{}] attemptCount[{}] is started",
this.taskGroupId, taskId, attemptCount);
}
?
//4.任務列表為空,executor已結束, 搜集狀態為success--->成功
if (taskQueue.isEmpty() && isAllTaskDone(runTasks) && containerCommunicator.collectState() == State.SUCCEEDED) {
// 成功的情況下,也需要匯報一次。否則在任務結束非常快的情況下,采集的信息將會不準確
lastTaskGroupContainerCommunication = reportTaskGroupCommunication(
lastTaskGroupContainerCommunication, taskCountInThisTaskGroup);
LOG.info("taskGroup[{}] completed it's tasks.", this.taskGroupId);
break;
}
// 5.如果當前時間已經超出匯報時間的interval,那么我們需要馬上匯報
long now = System.currentTimeMillis();
if (now - lastReportTimeStamp > reportIntervalInMillSec) {
lastTaskGroupContainerCommunication = reportTaskGroupCommunication(
lastTaskGroupContainerCommunication, taskCountInThisTaskGroup);
lastReportTimeStamp = now;
//taskMonitor對于正在運行的task,每reportIntervalInMillSec進行檢查
for(TaskExecutor taskExecutor:runTasks){ taskMonitor.report(taskExecutor.getTaskId(),this.containerCommunicator.getCommunication(taskExecutor.getTaskId()));
}
?
}
Thread.sleep(sleepIntervalInMillSec);
}
?
//6.最后還要匯報一次
reportTaskGroupCommunication(lastTaskGroupContainerCommunication, taskCountInThisTaskGroup);
} catch (Throwable e) {
Communication nowTaskGroupContainerCommunication = this.containerCommunicator.collect();
if (nowTaskGroupContainerCommunication.getThrowable() == null) {
nowTaskGroupContainerCommunication.setThrowable(e);
}
nowTaskGroupContainerCommunication.setState(State.FAILED);
this.containerCommunicator.report(nowTaskGroupContainerCommunication);
throw DataXException.asDataXException(
FrameworkErrorCode.RUNTIME_ERROR, e);
}finally {
if(!PerfTrace.getInstance().isJob()){
//最后打印cpu的平均消耗,GC的統計
VMInfo vmInfo = VMInfo.getVmInfo();
if (vmInfo != null) {
vmInfo.getDelta(false);
LOG.info(vmInfo.totalString());
}
LOG.info(PerfTrace.getInstance().summarizeNoException());
}
}
}
}
TaskExecute 具體執行類
開啟了2個線程,分別進行讀操作和寫操作。
數據處理:讀操作(ReaderRunner)把從數據庫中讀出來的每條數據封裝為一個個Record放入Channel中,當數據讀完時,寫入一個TerminateRecord標識結束
寫操作(WriterRunner)不斷從Channel中讀取Record,直到讀到TerminateRecord標識數據以取完
ReaderRunner分別執行#init, #prepare, #startRead, #post 并記錄每個階段的處理信息(數據量,數據大小…)
WriterRunner分別執行#init, #prepare, #start, #post 并記錄每個階段的處理信息(數據量,數據大小…)
class TaskExecutor {
private Configuration taskConfig; //當前任務配置項
private Channel channel; //管道 用于緩存讀出來的數據
private Thread readerThread; //讀線程
private Thread writerThread; //寫線程
private ReaderRunner readerRunner;
private WriterRunner writerRunner;
?
/**
* 該處的taskCommunication在多處用到:
* 1. channel
* 2. readerRunner和writerRunner
* 3. reader和writer的taskPluginCollector
*/
private Communication taskCommunication;
?
public TaskExecutor(Configuration taskConf, int attemptCount) {
// 獲取該taskExecutor的配置
this.taskConfig = taskConf;
//...
/**
* 由taskId得到該taskExecutor的Communication
* 要傳給readerRunner和writerRunner,同時要傳給channel作統計用
*/
this.taskCommunication = containerCommunicator
.getCommunication(taskId);
//實例化存儲讀數據的管道
this.channel = ClassUtil.instantiate(channelClazz,
Channel.class, configuration);
this.channel.setCommunication(this.taskCommunication);
/**
* 獲取transformer的參數
*/
List<TransformerExecution> transformerInfoExecs = TransformerUtil.buildTransformerInfo(taskConfig);
/**
* 生成writerThread
*/
writerRunner = (WriterRunner) generateRunner(PluginType.WRITER);
this.writerThread = new Thread(writerRunner,
String.format("%d-%d-%d-writer",
jobId, taskGroupId, this.taskId));
//通過設置thread的contextClassLoader,即可實現同步和主程序不通的加載器
this.writerThread.setContextClassLoader(LoadUtil.getJarLoader(
PluginType.WRITER, this.taskConfig.getString(
CoreConstant.JOB_WRITER_NAME)));
/**
* 生成readerThread
*/
readerRunner = (ReaderRunner) generateRunner(PluginType.READER,transformerInfoExecs);
this.readerThread = new Thread(readerRunner,
String.format("%d-%d-%d-reader",
jobId, taskGroupId, this.taskId));
/**
* 通過設置thread的contextClassLoader,即可實現同步和主程序不通的加載器
*/
this.readerThread.setContextClassLoader(LoadUtil.getJarLoader(
PluginType.READER, this.taskConfig.getString(
CoreConstant.JOB_READER_NAME)));
}
?
public void doStart() {
this.writerThread.start();
// reader沒有起來,writer不可能結束
if (!this.writerThread.isAlive() || this.taskCommunication.getState() == State.FAILED) {
throw DataXException.asDataXException(
FrameworkErrorCode.RUNTIME_ERROR,
this.taskCommunication.getThrowable());
}
this.readerThread.start();
// 這里reader可能很快結束
if (!this.readerThread.isAlive() && this.taskCommunication.getState() == State.FAILED) {
// 這里有可能出現Reader線上啟動即掛情況 對于這類情況 需要立刻拋出異常
throw DataXException.asDataXException(
FrameworkErrorCode.RUNTIME_ERROR,
this.taskCommunication.getThrowable());
}
?
}
}
以MySqlReader插件為例,ReaderRunner在執行#init, #prepare, #startRead, #post 時,實現在MysqlReader中
public static class Task extends Reader.Task {
public void startRead(RecordSender recordSender) {
int fetchSize = this.readerSliceConfig.getInt(Constant.FETCH_SIZE);
//mysqlReader調commonRdbmsReaderTask讀數據
this.commonRdbmsReaderTask.startRead(this.readerSliceConfig, recordSender,
super.getTaskPluginCollector(), fetchSize);
}
//...
}
public void startRead(Configuration readerSliceConfig,
RecordSender recordSender,
TaskPluginCollector taskPluginCollector, int fetchSize) {
//獲取job配置中的querySql
String querySql = readerSliceConfig.getString(Key.QUERY_SQL);
//獲取job配置中的tabelName querySql和table 不能并存,否則程序會提示配置錯誤
String table = readerSliceConfig.getString(Key.TABLE);
PerfTrace.getInstance().addTaskDetails(taskId, table + "," + basicMsg);
LOG.info("Begin to read record by Sql: [{}\n] {}.",
querySql, basicMsg);
PerfRecord queryPerfRecord = new PerfRecord(taskGroupId,taskId, PerfRecord.PHASE.SQL_QUERY);
queryPerfRecord.start();
//獲取數據庫連接
Connection conn = DBUtil.getConnection(this.dataBaseType, jdbcUrl,
username, password);
?
// session config .etc related
DBUtil.dealWithSessionConfig(conn, readerSliceConfig,
this.dataBaseType, basicMsg);
int columnNumber = 0;
ResultSet rs = null;
try {
rs = DBUtil.query(conn, querySql, fetchSize); //拿數據
queryPerfRecord.end();
//獲取表原信息
ResultSetMetaData metaData = rs.getMetaData();
columnNumber = metaData.getColumnCount();
//這個統計干凈的result_Next時間
PerfRecord allResultPerfRecord = new PerfRecord(taskGroupId, taskId, PerfRecord.PHASE.RESULT_NEXT_ALL);
allResultPerfRecord.start();
long rsNextUsedTime = 0;
long lastTime = System.nanoTime();
while (rs.next()) {
rsNextUsedTime += (System.nanoTime() - lastTime);
//將讀的數據放入recordSender對象的channel中
this.transportOneRecord(recordSender, rs,
metaData, columnNumber, mandatoryEncoding, taskPluginCollector);
lastTime = System.nanoTime();
}
allResultPerfRecord.end(rsNextUsedTime);
//目前大盤是依賴這個打印,而之前這個Finish read record是包含了sql查詢和result next的全部時間
LOG.info("Finished read record by Sql: [{}\n] {}.",
querySql, basicMsg);
}catch (Exception e) {
throw RdbmsException.asQueryException(this.dataBaseType, e, querySql, table, username);
} finally {
DBUtil.closeDBResources(null, conn);
}
}
protected Record transportOneRecord(RecordSender recordSender, ResultSet rs,
ResultSetMetaData metaData, int columnNumber, String mandatoryEncoding,
TaskPluginCollector taskPluginCollector) {
//每條數據組裝一個record
Record record = buildRecord(recordSender,rs,metaData,columnNumber,mandatoryEncoding,taskPluginCollector);
//record放入recordSender緩存
recordSender.sendToWriter(record);
return record;
}
flush
public void sendToWriter(Record record) {
//...
boolean isFull = (this.bufferIndex >= this.bufferSize || this.memoryBytes.get() + record.getMemorySize() > this.byteCapacity);
if (isFull) {
flush(); //這里會把buffer放入channel中
}
//放入集合列表
this.buffer.add(record);
this.bufferIndex++;
memoryBytes.addAndGet(record.getMemorySize());
}
?
public void flush() {
//...
this.channel.pushAll(this.buffer);
//...清空buffer
}
看完#flush可能會有個疑問,這里要進行判斷是否ifFull才把buffer放入channel。那最后一批不滿足ifFull條件的數據如何處理?
寫入
taskReader.startRead(recordSender); //讀插件開始讀
recordSender.terminate(); //把緩存中剩余數據寫如recordSender的channel中,并且寫入TerminateRecord打上結束標記
至此讀任務就結束了
接下來看寫任務
以MySqlWriter插件為例,WriterRunner分別執行#init, #prepare, #start, #post, 實現在MySqlWriter中
public static class Task extends Writer.Task {
//TODO 改用連接池,確保每次獲取的連接都是可用的(注意:連接可能需要每次都初始化其 session)
public void startWrite(RecordReceiver recordReceiver) {
this.commonRdbmsWriterTask.startWrite(recordReceiver, this.writerSliceConfig,
super.getTaskPluginCollector());
}
//...
}
public void startWrite(RecordReceiver recordReceiver,
Configuration writerSliceConfig,
TaskPluginCollector taskPluginCollector) {
Connection connection = DBUtil.getConnection(this.dataBaseType,
this.jdbcUrl, username, password);
DBUtil.dealWithSessionConfig(connection, writerSliceConfig,
this.dataBaseType, BASIC_MESSAGE);
startWriteWithConnection(recordReceiver, taskPluginCollector, connection); //開始寫
}
//…清空緩存,關閉資源
public void startWriteWithConnection(RecordReceiver recordReceiver, TaskPluginCollector taskPluginCollector, Connection connection) {
this.taskPluginCollector = taskPluginCollector;
// 用于寫入數據的時候的類型根據目的表字段類型轉換
this.resultSetMetaData = DBUtil.getColumnMetaData(connection,
this.table, StringUtils.join(this.columns, ","));
// 寫數據庫的SQL語句
calcWriteRecordSql();
List<Record> writeBuffer = new ArrayList<Record>(this.batchSize);
int bufferBytes = 0;
try {
Record record;
while ((record = recordReceiver.getFromReader()) != null) {
//...讀列與寫列數量不一致,會拋異常,這里省略
//寫緩存添加數據
writeBuffer.add(record);
bufferBytes += record.getMemorySize();
if (writeBuffer.size() >= batchSize || bufferBytes >= batchByteSize) {
doBatchInsert(connection, writeBuffer); //開始批量寫
writeBuffer.clear();
bufferBytes = 0;
}
}
if (!writeBuffer.isEmpty()) {
doBatchInsert(connection, writeBuffer);
writeBuffer.clear();
bufferBytes = 0;
}
} catch (Exception e) {
//...
} finally {
//...清空緩存,關閉資源
}
}
寫任務是批量操作,值得注意的是,當批量寫操作出現錯誤時,程序會爭取再執行一次寫操作,對每條數據分別進行寫操作
在#doOneInsert中
protected void doBatchInsert(Connection connection, List<Record> buffer)
throws SQLException {
PreparedStatement preparedStatement = null;
try {
connection.setAutoCommit(false);
preparedStatement = connection
.prepareStatement(this.writeRecordSql);
for (Record record : buffer) {
preparedStatement = fillPreparedStatement(
preparedStatement, record);
preparedStatement.addBatch(); //批量提交
}
preparedStatement.executeBatch(); //批量執行
connection.commit();
} catch (SQLException e) {
LOG.warn("回滾此次寫入, 采用每次寫入一行方式提交. 因為:" + e.getMessage());
connection.rollback();
doOneInsert(connection, buffer);
} catch (Exception e) {
throw DataXException.asDataXException(
DBUtilErrorCode.WRITE_DATA_ERROR, e);
} finally {
DBUtil.closeDBResources(preparedStatement, null);
}
}
?
protected void doOneInsert(Connection connection, List<Record> buffer) {
PreparedStatement preparedStatement = null;
try {
connection.setAutoCommit(true);
preparedStatement = connection
.prepareStatement(this.writeRecordSql);
for (Record record : buffer) {
try {
preparedStatement = fillPreparedStatement(
preparedStatement, record);
preparedStatement.execute();
} catch (SQLException e) {
LOG.debug(e.toString());
this.taskPluginCollector.collectDirtyRecord(record, e);
} finally {
// 最后不要忘了關閉 preparedStatement
preparedStatement.clearParameters();
}
}
} catch (Exception e) {
//...拋異常
} finally {
//...關閉資源
}
}
至此寫操作完畢
總結
整個應用,采用framework + read plugin + write plugin方式。對于核心配置文件core.json ,任務配置文件 job.json, 插件配置文件plugin.json 程序已經處理。并且結合Communication收集處理數據指標。我們只需要實現
Reader , Reader.Job , Reader.Task
Writer , Writer.Job , Writer.Task
根據項目的需求進行處理即可
智能推薦
Lifecycle詳細分析
Lifecycle源碼分析 目錄介紹 01.Lifecycle的作用是什么 02.Lifecycle的簡單使用 03.Lifecycle的使用場景 04.如何實現生命周期感知 05.注解方法如何被調用 06.addObserver調用分析 07.知識點梳理和總結一下 00.使用AAC實現bus事件總線 利用LiveData實現事件總線,替代EventBus。充分利用了生命周期感知功能,可以在act...

ConcurrentHashmap 詳細分析
詳盡的分析 JDK8 后的ConcurrentHashmap,思路分析輔以源碼走讀,徹底讀懂 ConcurrentHashmap。 簡介 放入數據 容器元素總數更新 容器擴容 協助擴容 遍歷 簡介 在從 JDK8 開始,為了提高并發度,ConcurrentHashMap的源碼進行了很大的調整。在 JDK7 中,采用的是分段鎖的思路。簡單的說,就是ConcurrentHashMap是由多個HashM...
ION詳細分析
參考: http://blog.csdn.net/armwind/article/details/53454251?locationNum=2&fps=1 代碼路徑 驅動代碼: kernel-3.18/drivers/staging/android/ion Native lib代碼: system\core\libion & vendor/mediatek/proprietary/...
CMA 詳細分析
關于CMA的config @LINUX/android/kernel/arch/arm/configs/msm8909_defconfig CONFIG_CMA=y 已經打開 # CONFIG_CMA_DEBUG is not set # # Default contiguous memory area size: # CONFIG_CMA_SIZE_MBYTES=8 //兩個配對定義 CONFI...
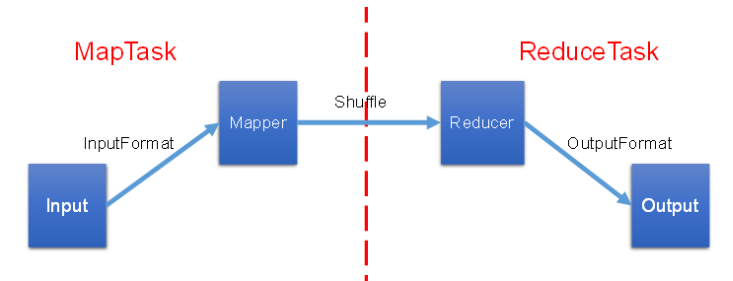
MapReduce詳細分析
一、MapReduce概述 1、定義 MapReduce核心功能是將用戶編寫的業務邏輯代碼和自帶默認組件整合成一個完整的分布式運算程序,并發運行在一個Hadoop集群 上。 2、MR進程 一個完整的MapR educe程序在分布式運行時有三類實例進程: **Mr AppMaster:**負責整個程序的過程調度及狀態協調。 MapTask:負責Map階段的整個數據處理流程。 ReduceTask:負...
猜你喜歡


freemarker + ItextRender 根據模板生成PDF文件
1. 制作模板 2. 獲取模板,并將所獲取的數據加載生成html文件 2. 生成PDF文件 其中由兩個地方需要注意,都是關于獲取文件路徑的問題,由于項目部署的時候是打包成jar包形式,所以在開發過程中時直接安照傳統的獲取方法沒有一點文件,但是當打包后部署,總是出錯。于是參考網上文章,先將文件讀出來到項目的臨時目錄下,然后再按正常方式加載該臨時文件; 還有一個問題至今沒有解決,就是關于生成PDF文件...
電腦空間不夠了?教你一個小秒招快速清理 Docker 占用的磁盤空間!
Docker 很占用空間,每當我們運行容器、拉取鏡像、部署應用、構建自己的鏡像時,我們的磁盤空間會被大量占用。 如果你也被這個問題所困擾,咱們就一起看一下 Docker 是如何使用磁盤空間的,以及如何回收。 docker 占用的空間可以通過下面的命令查看: TYPE 列出了docker 使用磁盤的 4 種類型: Images:所有鏡像占用的空間,包括拉取下來的鏡像,和本地構建的。 Con...

requests實現全自動PPT模板
http://www.1ppt.com/moban/ 可以免費的下載PPT模板,當然如果要人工一個個下,還是挺麻煩的,我們可以利用requests輕松下載 訪問這個主頁,我們可以看到下面的樣式 點每一個PPT模板的圖片,我們可以進入到詳細的信息頁面,翻到下面,我們可以看到對應的下載地址 點擊這個下載的按鈕,我們便可以下載對應的PPT壓縮包 那我們就開始做吧 首先,查看網頁的源代碼,我們可以看到每一...
