用 Python 入門數據科學
使用 Python 開展數據科學為你提供了無限的潛力,使你能夠以有意義和啟發性的方式解析、解釋和組織數據。
數據科學是計算領域一個令人興奮的新領域,它圍繞分析、可視化和關聯以解釋我們的計算機收集的有關世界的無限信息而建立。當然,稱其為“新”領域有點不誠實,因為該學科是統計學、數據分析和普通而古老的科學觀察派生而來的。
但是數據科學是這些學科的形式化分支,擁有自己的流程和工具,并且可以廣泛應用于以前從未產生過大量不可管理數據的學科(例如視覺效果)。數據科學是一個新的機會,可以重新審視海洋學、氣象學、地理學、制圖學、生物學、醫學和健康以及娛樂行業的數據,并更好地了解其中的模式、影響和因果關系。
像其他看似包羅萬象的大型領域一樣,知道從哪里開始探索數據科學可能會令人生畏。有很多資源可以幫助數據科學家使用自己喜歡的編程語言來實現其目標,其中包括最流行的編程語言之一:Python。使用 Pandas 、 Matplotlib 和 Seaborn 這些庫,你可以學習數據科學的基本工具集。
如果你對 Python 的基本用法不是很熟悉,請在繼續之前先閱讀我的 Python 介紹 。
創建 Python 虛擬環境
程序員有時會忘記在開發計算機上安裝了哪些庫,這可能導致他們提供了在自己計算機上可以運行,但由于缺少庫而無法在所有其它電腦上運行的代碼。Python 有一個系統旨在避免這種令人不快的意外:虛擬環境。虛擬環境會故意忽略你已安裝的所有 Python 庫,從而有效地迫使你一開始使用通常的 Python 進行開發。
為了用 venv **虛擬環境, 為你的環境取個名字 (我會用 example ) 并且用下面的指令創建它:
$ python3 -m venv example
導入source 該環境的 bin 目錄里的 activate 文件以**它:
$ source ./example/bin/activate (example) $
你現在“位于”你的虛擬環境中。這是一個干凈的狀態,你可以在其中構建針對該問題的自定義解決方案,但是額外增加了需要有意識地安裝依賴庫的負擔。
安裝 Pandas 和 NumPy
你必須在新環境中首先安裝的庫是 Pandas 和 NumPy。這些庫在數據科學中很常見,因此你肯定要時不時安裝它們。它們也不是你在數據科學中唯一需要的庫,但是它們是一個好的開始。
Pandas 是使用 BSD 許可證的開源庫,可輕松處理數據結構以進行分析。它依賴于 NumPy,這是一個提供多維數組、線性代數和傅立葉變換等等的科學庫。使用 pip3 安裝兩者:
(example) $ pip3 install pandas
安裝 Pandas 還會安裝 NumPy,因此你無需同時指定兩者。一旦將它們安裝到虛擬環境中,安裝包就會被緩存,這樣,當你再次安裝它們時,就不必從互聯網上下載它們。
這些是你現在僅需的庫。接下來,你需要一些樣本數據。
生成樣本數據集
數據科學都是關于數據的,幸運的是,科學、計算和政府組織可以提供許多免費和開放的數據集。雖然這些數據集是用于教育的重要資源,但它們具有比這個簡單示例所需的數據更多的數據。你可以使用 Python 快速創建示例和可管理的數據集:
#!/usr/bin/env python3
import random
def rgb():
NUMBER=random.randint(0,255)/255
return NUMBER
FILE = open('sample.csv','w')
FILE.write('"red","green","blue"')
for COUNT in range(10):
FILE.write('\n{:0.2f},{:0.2f},{:0.2f}'.format(rgb(),rgb(),rgb()))
這將生成一個名為 sample.csv 的文件,該文件由隨機生成的浮點數組成,這些浮點數在本示例中表示 RGB 值(在視覺效果中通常是數百個跟蹤值)。你可以將 CSV 文件用作 Pandas 的數據源。
使用 Pandas 提取數據
Pandas 的基本功能之一是可以提取數據和處理數據,而無需程序員編寫僅用于解析輸入的新函數。如果你習慣于自動執行此操作的應用程序,那么這似乎不是很特別,但請想象一下在 LibreOffice 中打開 CSV 并且必須編寫公式以在每個逗號處拆分值。Pandas 可以讓你免受此類低級操作的影響。以下是一些簡單的代碼,可用于提取和打印以逗號分隔的值的文件:
#!/usr/bin/env python3
from pandas import read_csv, DataFrame
import pandas as pd
FILE = open('sample.csv','r')
DATAFRAME = pd.read_csv(FILE)
print(DATAFRAME)
Python學習qq群:10667510,送全套爬蟲學習資料與教程~一開始的幾行導入 Pandas 庫的組件。Pandas 庫功能豐富,因此在尋找除本文中基本功能以外的功能時,你會經常參考它的文檔。
接下來,通過打開你創建的 sample.csv 文件創建變量 FILE 。Pandas 模塊 read_csv (在第二行中導入)使用該變量來創建 數據幀dataframe 。在 Pandas 中,數據幀是二維數組,通常可以認為是表格。數據放入數據幀中后,你可以按列和行進行操作,查詢其范圍,然后執行更多操作。目前,示例代碼僅將該數據幀輸出到終端。
運行代碼。你的輸出會和下面的輸出有些許不同,因為這些數字都是隨機生成的,但是格式都是一樣的。
(example) $ python3 ./parse.py
red green blue
0 0.31 0.96 0.47
1 0.95 0.17 0.64
2 0.00 0.23 0.59
3 0.22 0.16 0.42
4 0.53 0.52 0.18
5 0.76 0.80 0.28
6 0.68 0.69 0.46
7 0.75 0.52 0.27
8 0.53 0.76 0.96
9 0.01 0.81 0.79
假設你只需要數據集中的紅色值( red ),你可以通過聲明數據幀的列名稱并有選擇地僅打印你感興趣的列來做到這一點:
from pandas import read_csv, DataFrame
import pandas as pd
FILE = open('sample.csv','r')
DATAFRAME = pd.read_csv(FILE)
# define columns
DATAFRAME.columns = [ 'red','green','blue' ]
print(DATAFRAME['red'])
Python學習qq群:10667510,送全套爬蟲學習資料與教程~現在運行代碼,你只會得到紅色列:
(example) $ python3 ./parse.py 0 0.31 1 0.95 2 0.00 3 0.22 4 0.53 5 0.76 6 0.68 7 0.75 8 0.53 9 0.01 Name: red, dtype: float64
處理數據表是經常使用 Pandas 解析數據的好方法。從數據幀中選擇數據的方法有很多,你嘗試的次數越多就越習慣。
可視化你的數據
很多人偏愛可視化信息已不是什么秘密,這是圖表和圖形成為與高層管理人員開會的主要內容的原因,也是“信息圖”在新聞界如此流行的原因。數據科學家的工作之一是幫助其他人理解大量數據樣本,并且有一些庫可以幫助你完成這項任務。將 Pandas 與可視化庫結合使用可以對數據進行可視化解釋。一個流行的可視化開源庫是 Seaborn ,它基于開源的 Matplotlib 。
安裝 Seaborn 和 Matplotlib
你的 Python 虛擬環境還沒有 Seaborn 和 Matplotlib,所以用 pip3 安裝它們。安裝 Seaborn 的時候,也會安裝 Matplotlib 和很多其它的庫。
(example) $ pip3 install seaborn
為了使 Matplotlib 顯示圖形,你還必須安裝 PyGObject 和 Pycairo 。這涉及到編譯代碼,只要你安裝了必需的頭文件和庫, pip3 便可以為你執行此操作。你的 Python 虛擬環境不了解這些依賴庫,因此你可以在環境內部或外部執行安裝命令。
在 Fedora 和 CentOS 上:
(example) $ sudo dnf install -y gcc zlib-devel bzip2 bzip2-devel readline-devel \
sqlite sqlite-devel openssl-devel tk-devel git python3-cairo-devel \
cairo-gobject-devel gobject-introspection-devel
Python學習qq群:10667510,送全套爬蟲學習資料與教程~在 Ubuntu 和 Debian 上:
(example) $ sudo apt install -y libgirepository1.0-dev build-essential \
libbz2-dev libreadline-dev libssl-dev zlib1g-dev libsqlite3-dev wget \
curl llvm libncurses5-dev libncursesw5-dev xz-utils tk-dev libcairo2-dev
Python學習qq群:10667510,送全套爬蟲學習資料與教程~一旦它們安裝好了,你可以安裝 Matplotlib 需要的 GUI 組件。
(example) $ pip3 install PyGObject pycairo
用 Seaborn 和 Matplotlib 顯示圖形
在你最喜歡的文本編輯器新建一個叫 vizualize.py 的文件。要創建數據的線形圖可視化,首先,你必須導入必要的 Python 模塊 —— 先前代碼示例中使用的 Pandas 模塊:
#!/usr/bin/env python3 from pandas import read_csv, DataFrame import pandas as pd
接下來,導入 Seaborn、Matplotlib 和 Matplotlib 的幾個組件,以便你可以配置生成的圖形:
import seaborn as sns
import matplotlib
import matplotlib.pyplot as plt
from matplotlib import rcParams
Python學習qq群:10667510,送全套爬蟲學習資料與教程~Matplotlib 可以將其輸出導出為多種格式,包括 PDF、SVG 和桌面上的 GUI 窗口。對于此示例,將輸出發送到桌面很有意義,因此必須將 Matplotlib 后端設置為 GTK3Agg 。如果你不使用 Linux,則可能需要使用 TkAgg 后端。
設置完 GUI 窗口以后,設置窗口大小和 Seaborn 預設樣式:
matplotlib.use('GTK3Agg')
rcParams['figure.figsize'] = 11,8
sns.set_style('darkgrid')
現在,你的顯示已配置完畢,代碼已經很熟悉了。使用 Pandas 導入 sample.csv 文件,并定義數據幀的列:
FILE = open('sample.csv','r')
DATAFRAME = pd.read_csv(FILE)
DATAFRAME.columns = [ 'red','green','blue' ]
有了適當格式的數據,你可以將其繪制在圖形中。將每一列用作繪圖的輸入,然后使用 plt.show() 在 GUI 窗口中繪制圖形。 plt.legend() 參數將列標題與圖形上的每一行關聯( loc 參數將圖例放置在圖表之外而不是在圖表上方):
for i in DATAFRAME.columns:
DATAFRAME[i].plot()
plt.legend(bbox_to_anchor=(1, 1), loc=2, borderaxespad=1)
plt.show()
運行代碼以獲得結果。
你的圖形可以準確顯示 CSV 文件中包含的所有信息:值在 Y 軸上,索引號在 X 軸上,并且圖形中的線也被標識出來了,以便你知道它們代表什么。然而,由于此代碼正在跟蹤顏色值(至少是假裝),所以線條的顏色不僅不直觀,而且違反直覺。如果你永遠不需要分析顏色數據,則可能永遠不會遇到此問題,但是你一定會遇到類似的問題。在可視化數據時,你必須考慮呈現數據的最佳方法,以防止觀看者從你呈現的內容中推斷出虛假信息。
為了解決此問題(并展示一些可用的自定義設置),以下代碼為每條繪制的線分配了特定的顏色:
import matplotlib
from pandas import read_csv, DataFrame
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from matplotlib import rcParams
matplotlib.use('GTK3Agg')
rcParams['figure.figsize'] = 11,8
sns.set_style('whitegrid')
FILE = open('sample.csv','r')
DATAFRAME = pd.read_csv(FILE)
DATAFRAME.columns = [ 'red','green','blue' ]
plt.plot(DATAFRAME['red'],'r-')
plt.plot(DATAFRAME['green'],'g-')
plt.plot(DATAFRAME['blue'],'b-')
plt.plot(DATAFRAME['red'],'ro')
plt.plot(DATAFRAME['green'],'go')
plt.plot(DATAFRAME['blue'],'bo')
plt.show()
這使用特殊的 Matplotlib 表示法為每列創建兩個圖。每列的初始圖分配有一種顏色(紅色為 r,綠色為 g ,藍色為 b )。這些是內置的 Matplotlib 設置。 - 表示實線(雙破折號,例如 r--,將創建虛線)。為每個具有相同顏色的列創建第二個圖,但是使用 o 表示點或節點。為了演示內置的 Seaborn 主題,請將 sns.set_style 的值更改為 whitegrid 。
停用你的虛擬環境
探索完 Pandas 和繪圖后,可以使用 deactivate 命令停用 Python 虛擬環境:
(example) $ deactivate $
當你想重新使用它時,只需像在本文開始時一樣重新**它即可。重新**虛擬環境時,你必須重新安裝模塊,但是它們是從緩存安裝的,而不是從互聯網下載的,因此你不必聯網。
無盡的可能性
Pandas、Matplotlib、Seaborn 和數據科學的真正力量是無窮的潛力,使你能夠以有意義和啟發性的方式解析、解釋和組織數據。下一步是使用你在本文中學到的新工具探索簡單的數據集。Matplotlib 和 Seaborn 不僅有折線圖,還有很多其他功能,因此,請嘗試創建條形圖或餅圖或完全不一樣的東西。
一旦你了解了你的工具集并對如何關聯數據有了一些想法,則可能性是無限的。數據科學是尋找隱藏在數據中的故事的新方法。讓開源成為你的媒介。
智能推薦

Python數據科學入門(Pandas玩轉數據)- 筆記03
Python數據科學入門(Pandas玩轉數據) 慕課網數據科學入門課程學習筆記 一、Series和DataFrame的簡單數學運算 1.Series 相加 A 1 B 2 C 3 dtype: int64 B 4 C 5 D 6 E 7 dtype: int64 A NaN B 6.0 C 8.0 D NaN E NaN dtype: float64 2.Dataframe運算 AA BB A ...

數據分析(3)python科學計算:用NumPy快速處理數據
NumPy更加高效 NumPy數組結構比Python本身的list更加的節省資源: 列表 list 的元素在系統內存中是分散存儲的,而 NumPy 數組存儲在一個均勻連續的內存塊中。這樣數組計算遍歷所有的元素,不像列表 list 還需要對內存地址進行查找,從而節省了計算資源。 另外在內存訪問模式中,緩存會直接把字節塊從 RAM 加載到 CPU 寄存器中。因為數據連續的存儲在內存中,NumPy 直接...
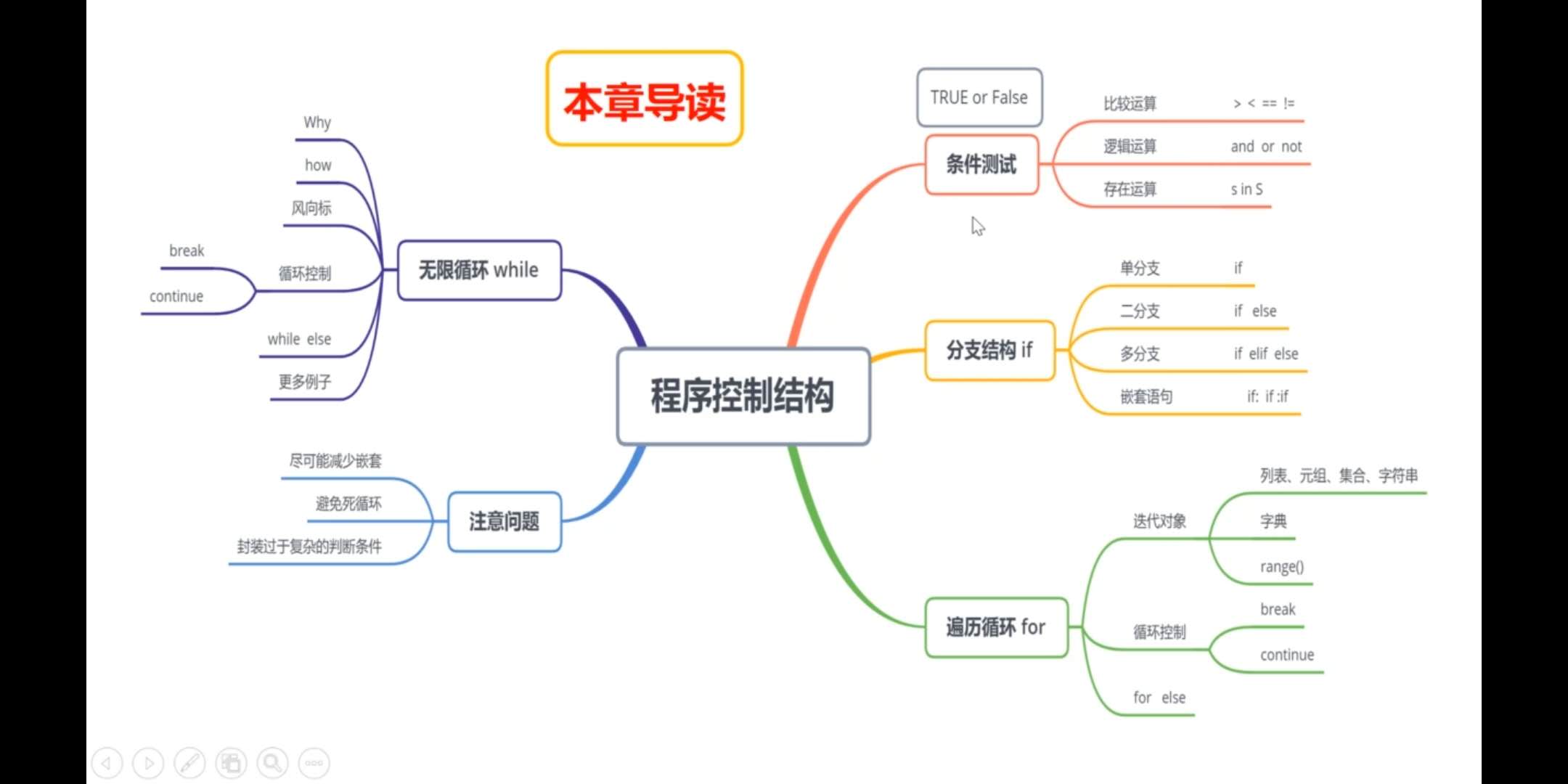
Python基礎+數據科學入門(四)程序控制結構
聲明:該博客參考深度之眼的視頻課程,如有侵權請聯系小編刪除博文,謝謝! 若總結有所失誤,還請見諒,并歡迎及時指出。 程序控制結構 1.1 條件測試 1.1.1 比較運算 1.1.2 比較運算 1.1.3 比較運算...

Python 數據科學入門教程:TensorFlow 目標檢測
TensorFlow 目標檢測 原文:TensorFlow Object Detection 譯者:飛龍 協議:CC BY-NC-SA 4.0 一、引言 你好,歡迎閱讀 TensorFlow 目標檢測 API 迷你系列。 這個 API 可以用于檢測圖像和/或視頻中的對象,帶有使用邊界框,使用可用的一些預先訓練好的模型,或者你自己可以訓練的模型(API 也變得更容易)。 首先,你要確保你有 Tens...
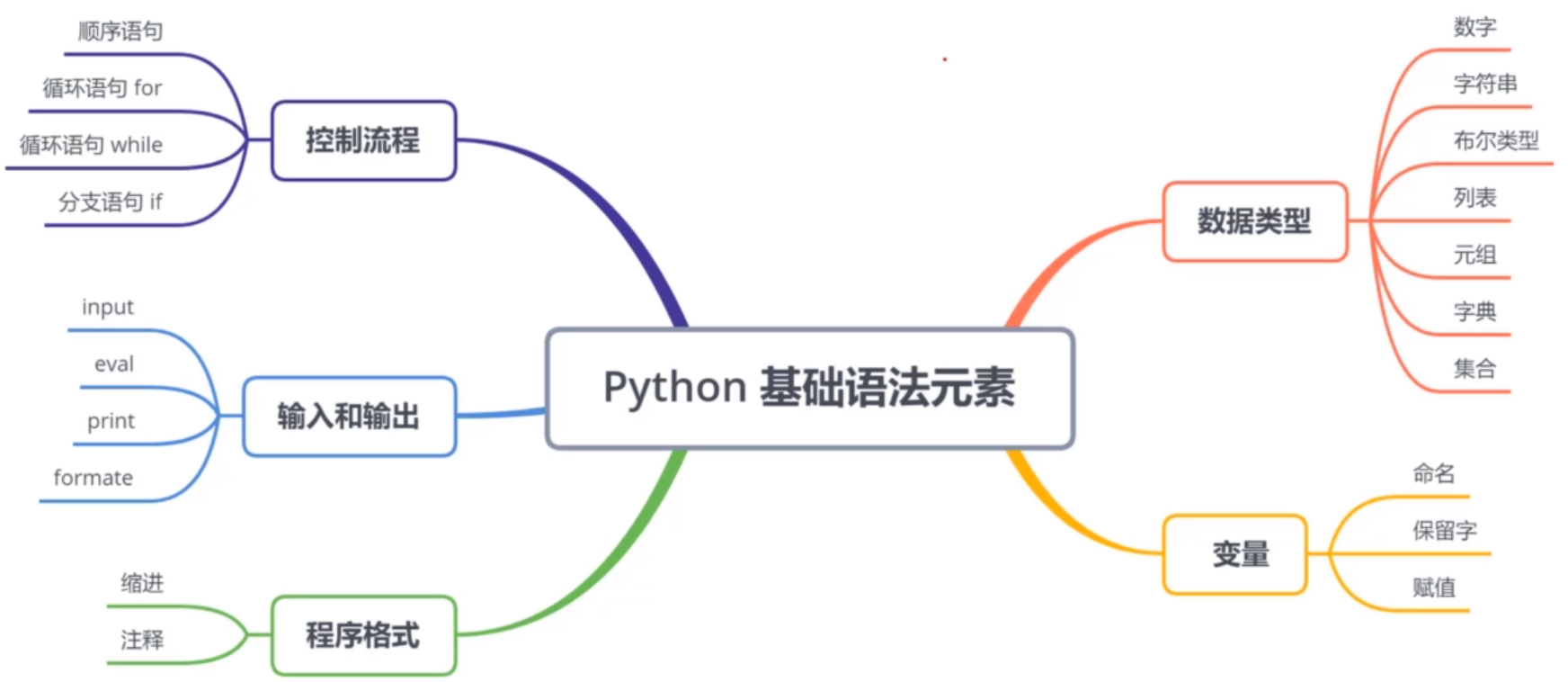
Python基礎+數據科學入門(一)基本語法元素
聲明:該博客參考深度之眼的視頻課程,如有侵權請聯系小編刪除博文,謝謝! 若總結有所失誤,還請見諒,并歡迎及時指出。 Python所使用環境和基本語法元素 該系列python基礎針對之后學習人工智能打造的,所學習的python基礎知識并不全面,僅涉及與人工智能方面相關的python內容 所使用開發環境 以Anaconda為主要開發工具(可自行百度安裝教程),使用Jupyter Notebook 開發...
猜你喜歡

猿創征文|【Python數據科學快速入門系列 | 05】常用科學計算函數
這是機器未來的第44篇文章 原文首發地址:https://blog.csdn.net/RobotFutures/article/details/126615267 文章目錄 1. 概述 2. 加載數據集 3. 查看數據特征 3.1 查看首5行數據 3.2 查看數據集每個特征的最大值 3.3 查看每個特征的最小值 3.4 查看特征均值 3.5 查看特征百分位數 3.6 查看特征數據分布波動 3.8 ...


freemarker + ItextRender 根據模板生成PDF文件
1. 制作模板 2. 獲取模板,并將所獲取的數據加載生成html文件 2. 生成PDF文件 其中由兩個地方需要注意,都是關于獲取文件路徑的問題,由于項目部署的時候是打包成jar包形式,所以在開發過程中時直接安照傳統的獲取方法沒有一點文件,但是當打包后部署,總是出錯。于是參考網上文章,先將文件讀出來到項目的臨時目錄下,然后再按正常方式加載該臨時文件; 還有一個問題至今沒有解決,就是關于生成PDF文件...
電腦空間不夠了?教你一個小秒招快速清理 Docker 占用的磁盤空間!
Docker 很占用空間,每當我們運行容器、拉取鏡像、部署應用、構建自己的鏡像時,我們的磁盤空間會被大量占用。 如果你也被這個問題所困擾,咱們就一起看一下 Docker 是如何使用磁盤空間的,以及如何回收。 docker 占用的空間可以通過下面的命令查看: TYPE 列出了docker 使用磁盤的 4 種類型: Images:所有鏡像占用的空間,包括拉取下來的鏡像,和本地構建的。 Con...

requests實現全自動PPT模板
http://www.1ppt.com/moban/ 可以免費的下載PPT模板,當然如果要人工一個個下,還是挺麻煩的,我們可以利用requests輕松下載 訪問這個主頁,我們可以看到下面的樣式 點每一個PPT模板的圖片,我們可以進入到詳細的信息頁面,翻到下面,我們可以看到對應的下載地址 點擊這個下載的按鈕,我們便可以下載對應的PPT壓縮包 那我們就開始做吧 首先,查看網頁的源代碼,我們可以看到每一...