小白初學XML(XML基本語法,XML約束(DTD、Schema )、解析(jaxp、DOM4J、Jsoup、selector方法、xpath))
標簽: xml
(1)XML介紹
1 XML的前世今生:
XML和HTML都是W3C公司創建出來的,XML起初是為了代替他的哥哥HTML,
因為在當時HTML已經被各大瀏覽器的玩壞(兼容性過高,導致不規范),才產生
了他的弟弟XML,語法相當的嚴格,但是由于XML使用起來沒有HTML簡單好用,
XML沒有替代了他哥哥。現在XML主要是用來存儲數據和配置文件相似
2 XML概念:
Extensible Markup Language 可擴展標記語言
可擴展:標簽都是自定義的
3 XML功能:
可以和HTML一樣做網頁的結構(現在大部分已經拋棄這個功能)
可以和properties 一樣存儲數據,做配置文件、網絡中傳輸
4 XML和HTML的區別:
1 XML的標簽都是自定義的,HTML標簽都是預定義的
2 XML語法嚴格,HTML語法松散
3 XML是儲存數據,HTML是展示數據的
5 我的第一個XML文件
<?xml version="1.0" ?>
<users>
<user id="1">
<name>張三</name>
<age>20</age>
<gender>male</gender>
</user>
<user id="2">
<name>李四</name>
<age>22</age>
<gender>female</gender>
</user>
</users>
XML文件可以直接拖到瀏覽器上看結果
(2)XML語法
1 基本語法
1 XML的綴名為 .XML
2 XML的第一行必須定義文檔聲明 <?xml version="1.0" ?>
3 XML有且僅有一個根標簽 <users></users>
4 XML標簽的屬性值必須用雙或單引號括起來
5 XML標簽必須正確關閉(要么自閉和標簽<name></name>要么維度標簽<br/>)
6 XML標簽區分大小寫
2 組成部分
1 文檔聲明:
格式:
<? xml version="1.0" ?> 注意<與?與xml之間不能有空格
屬性列表:
version: 版本號,必須的屬性(1.0是主流版本,通常使用1.0版本)
encoding: 編碼方式。告知解析引擎寫該XML文檔的編碼,默認IOS-8859-1
standalone:是否獨立 yes 不依賴其他文件 no依賴其他文件
2 指令(了解):
結合CSS樣式的,當時為了代替HTML的時候的功能
標簽全部被解析,結合css展示其中的數據
<?xml-stylesheet type="text/css" href="a.css" ?>
導入a.css文件
3 標簽: 標簽名稱自定義
XML標簽必須正確關閉(要么自閉和標簽<name></name>要么維度標簽<br/>)
4 屬性:
必須要有引號(單雙都可以),id屬性值唯一
5 文本:
有一些轉義字符,和HTML一樣,比如大于號: >
CDATD區的數據會被原樣展示:
<! [ CDATA[數據] ] >
(3)XML約束
1 簡介
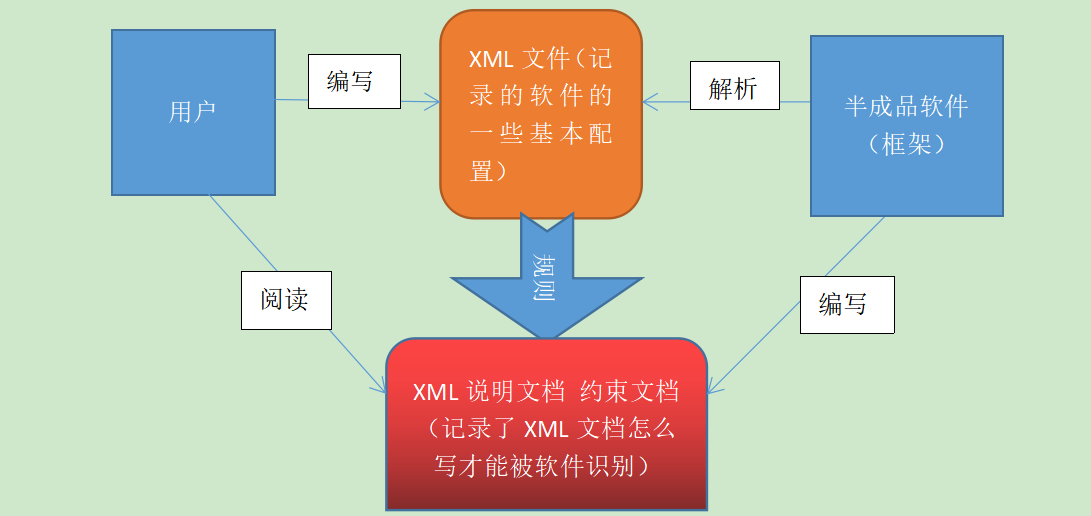
誰編寫XML文件? 用戶(程序員)、軟件使用者
誰解析XML文件? 軟件
約束文檔:規范XML文檔的書寫規范
作為框架使用(程序員):
1 能夠在XML文件引入約束文檔
2 能夠簡單的讀懂約束文檔
2 約束分類:
DTD約束:一種簡單的約束技術,一個.dtd文件
Schema約束:一種復雜的約束技術,一個.xsd文件
3 DTD約束:
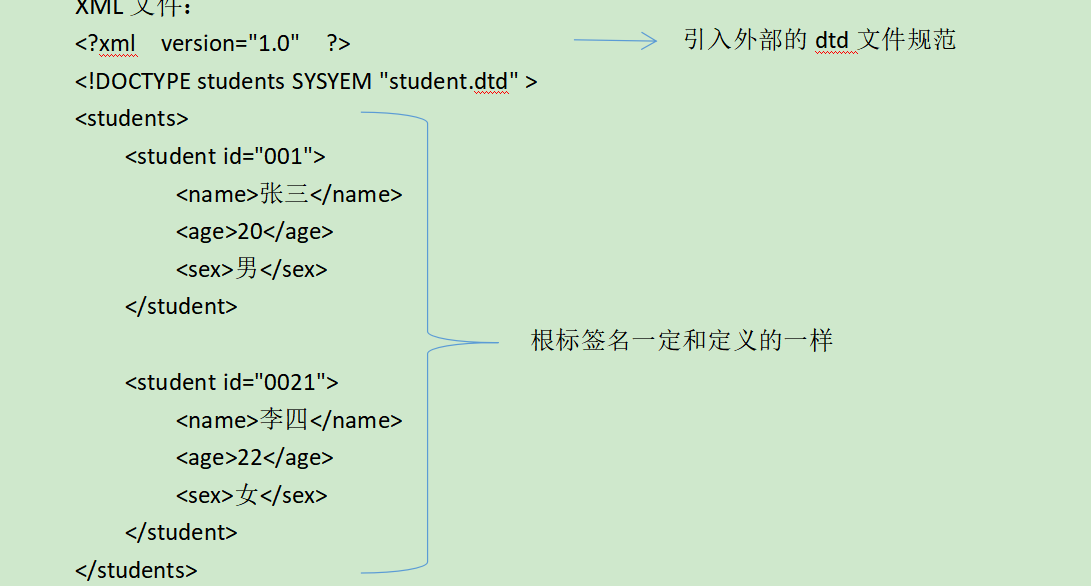
(1)怎么為一個XML使用一個DTD約束??
在XML文檔中引入DTD約束:
XML內部dtd: <!DOCTYPE 根標簽名 [ dtd約束內容 ] >
XML外部dtd:引入一個dtd文件
本地dtd引入XML: <!DOCTYPE 根標簽名 SYSTEM “dtd文件的位置 ”>
網絡dtd映入XML: <!DOCTYPE 根標簽名 PUBLIC “dtd名字” “dtd文件的位置URL ”>
(其中SYSTEM表示系統,dtd名字隨便起 該XML文件根標簽必須以該根標簽名)
(2)簡單的閱讀以下.dtd文檔
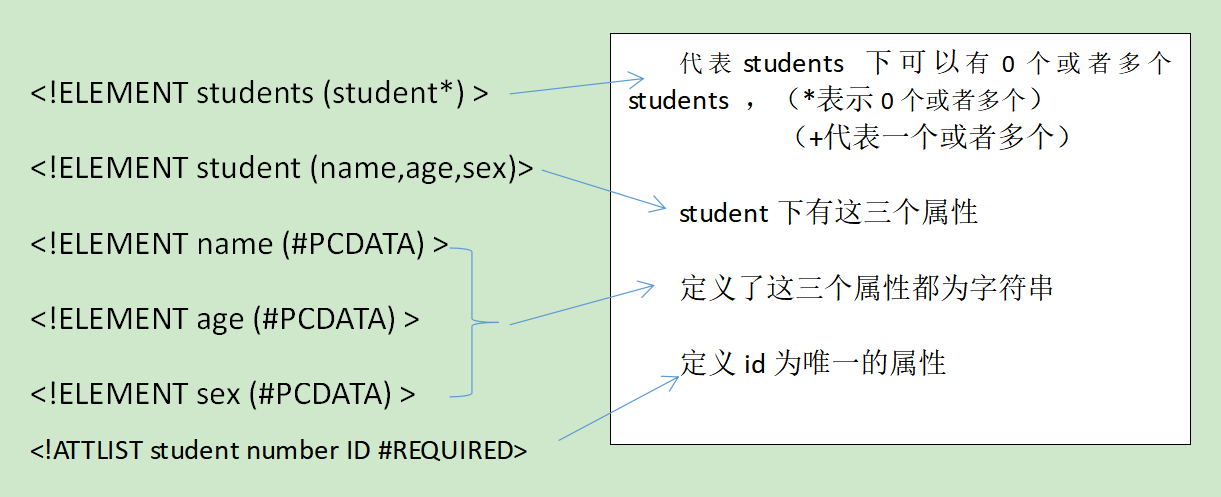
(3)dtd約束文檔的缺陷:
不能規范標簽里面文本的內容格式
Schema約束能夠解決該問題
4 Schema 約束
.xsd文件
怎么在XML文件中引入Schema約束??
看明白.xsd文件Schema約束的基本內容??
(5)解析:
解析概念:將文檔中的數據加載到內存
兩種解析思想:
1 DOM思想:(和JS的DOM一樣,將標記語言一次性加載到內存,形成一顆dom樹)
優點:操作方便,可以對XMl文件進行增刪改查
缺點:一次性價值,占內存
(適應于PC端,內存較大)
2 SAX思想: 逐行讀取,基于事件驅動
優點:幾乎不占內存
缺點:只能讀,不能增刪改
(適應于手機端)
常見的XML的解析器:
解析器??? 更具XML解析思想寫出來的解析jar包
1.JAXP解析器: sum公司提供的,支持DOM和SAX兩種思想
(相當于JAVA官方提供的,性能較差,沒人使用)
2.DOM4J解析器:DOM思想實現的一款非常優秀的解析器
3.Jsoup解析器:DOM思想實現的一款非常優秀的解析器(主要講解)
4.PULL解析器: Android 系統內置的解析器
Jsoup解析器:(可以解析HTML也可以解析XML)
先導入jsuop包
快速入門:
1 導入jsoup的jar包
2獲取document對象
3獲取對應的元素標簽element對象
4獲取數據
//1 導入jar包
//2 根據文件獲取document對象
Document document = Jsoup.parse(new File("D:\\IDEA\\源碼\\Text1\\src\\Student.xml"),"utf-8");
//3獲取對應的元素標簽element對象
//查找所有的name標簽,Element對象其實就是一個ArrayList數組
Elements elements = document.getElementsByTag("name");
//4獲取數據
Element element =elements.get(1);
String name = element.text();
System.out.println(name);
常見的類及其使用方法
Jsoup類: 工具類,解析HTML或者XML文檔,返回Document對象
* Parse靜態方法,獲取Document對象,解析傳過來的XML或者HTML文檔.
1 parse(File,String) 傳入文件以及編碼方式
2 parse(String) 解析XML或者HTML字符串
3 parse(URL,int) 解析該網站的HTML/XML,并設置超時時間(毫秒),超時不在訪問
(會把整個網頁的代碼全部爬下來)
Document類: 文檔的對象,DOM樹結構的根節點
*獲取Element、Elements對象
1 getElementById(String) 通過id獲取唯一的一個標簽對象
2 getElementsByTag(String 標簽名) 根據標簽名獲取對象
3 getElementsByAttribute(String 屬性名) 根據屬性名獲取對象
4 getElementsByAttributeValue(String 屬性名,String 屬性值) 根據屬性名和屬性值獲取對象
Elements類: Element類的集合(相當于ArrayList<Element>)
Element類: 標簽元素對象
*獲取子元素對象
1 getElementById(String) 通過id獲取唯一的一個標簽對象
2 getElementsByTag(String 標簽名) 根據標簽名獲取對象
3 getElementsByAttribute(String 屬性名) 根據屬性名獲取對象
4 getElementsByAttributeValue(String 屬性名,String 屬性值) 根據屬性名和屬性值獲取對象
*獲取屬性值:
attr(String 屬性名) 根據屬性名得到屬性值
*獲取文本內容:
text() 獲取文本內容
html() 獲取標簽體內所有的內容
Node類: 節點對象
是Element和Document類的父類
快捷查詢方式:
1 selector(String cssQuery)方法,通過css選擇器查詢標簽元素Element對象
(Document對象和Element對象都可以使用)
怎么寫cssQuery字符串??
查看JSoup幫助文檔中的Selector類定義的cssQuery定義的語法
比如:
cssQuery=“name” 查詢name 標簽對象
cssQuery=”#itcast” 查詢ID為itcast的標簽
cssQuery=”name[id=’0001’]” 查詢Id值為0001的name 標簽
cssQuery=”student[id=’0001’] age” 查詢Id值為0001的student標簽的所有age子標簽
2 XPath通過“特殊的語法”查詢標簽元素Element對象
XPath 使用路徑表達式來選取 XML 文檔中的節點或者節點集。
怎么使用Xpath??
使用Jsoup的Xpath()需要額外導入一個jar包(JsoupXpath.jar)
1 根據document對象創建JXDocument對象 JXDocument jxDocument = new JXDocument (document);
2 JXDocument對象常見的方法:
通過xpath語法查詢標簽元素
selN(String xpath) 返回List<JxNode>
sel(String xpath) 返回List<Object>
selNOne(String xpath) 返回JxNode
selOne(String xpath) 返回Object
可以通過JxNode對象轉化為標簽元素對象getElement()方法
3 Xpath的查詢語法
詳細的Xpath語法查看W3Cshool參考手冊
Xpath = “ //student” 查詢所以的student標簽
Xpath =”//student//name” 查詢所以的student標簽下的name標簽
Xpath = “//student[@id]” 查詢含有id屬性的student標簽
Xpath = “//student[@id=’itcast’]” 查詢id為itcast屬性的student標簽
看嗶哩嗶哩黑馬培訓機構視頻:204-217 https://b23.tv/FewvhM
智能推薦

dom4j 解析XML文件
<?xml version="1.0" encoding="UTF-8"?> <!-- 手機的根節點 --> <Phones> <Brand name="三星"> <Type name="note4">note4</Type...

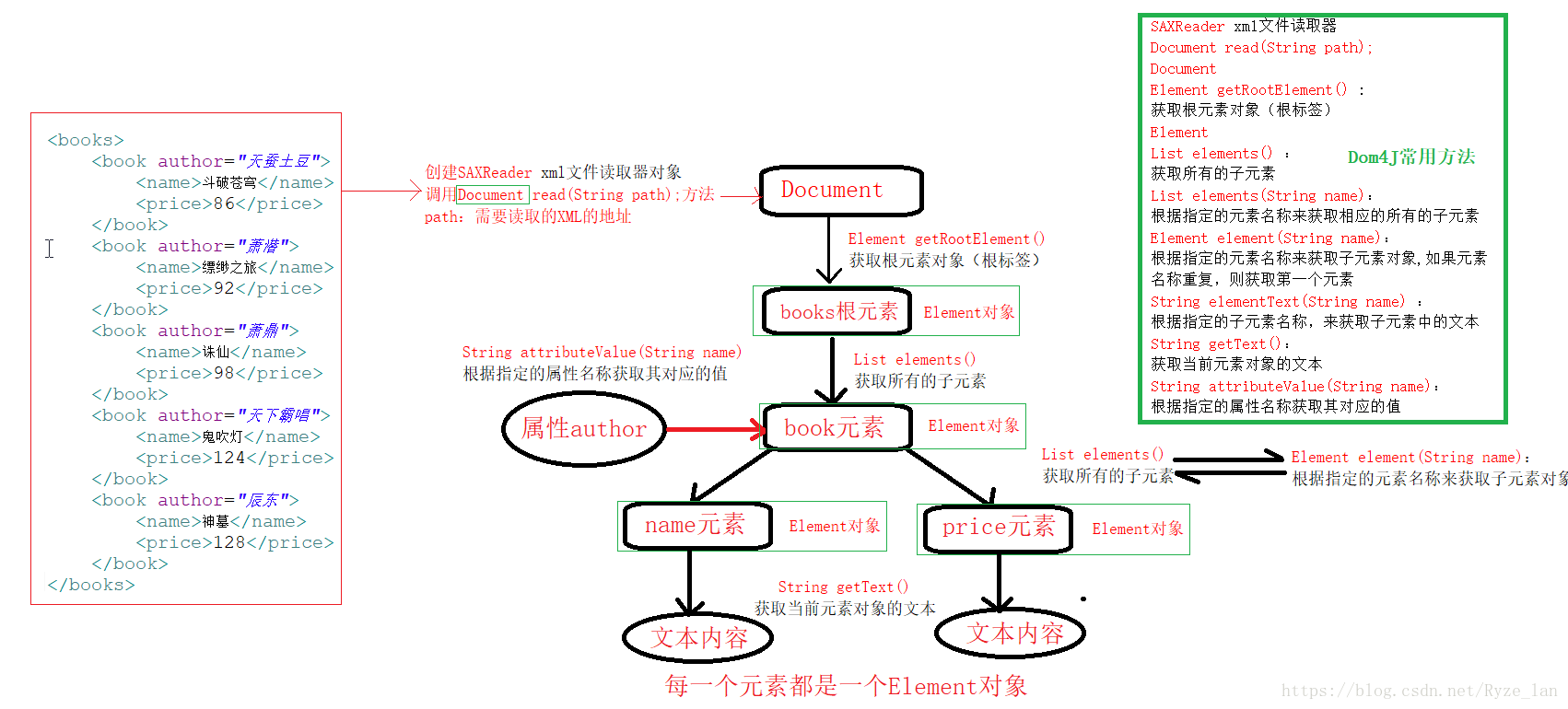
Dom4J解析XML
Dom for java 解析步驟及常用API 下載依賴的jar包 下載連接 并導入項目 Dom4J讀取解析XML原理分析: Dom4J的常用方法: SAXReader 對象 xml文件讀取器 Document read(String path);加載執行xml文檔 Document 對象 Element getRootElement() :獲取根元素對象(根標簽) Element 對...

使用Dom4j解析XML
轉載自 使用Dom4j解析XML dom4j是一個Java的XML API,類似于jdom,用來讀寫XML文件的。dom4j是一個非常非常優秀的Java XML API,具有性能優異、功能強大和極端易用使用的特點,同時它也是一個開放源代碼的軟件,可以在SourceForge上找到它. 對主流的Ja...

猜你喜歡

freemarker + ItextRender 根據模板生成PDF文件
1. 制作模板 2. 獲取模板,并將所獲取的數據加載生成html文件 2. 生成PDF文件 其中由兩個地方需要注意,都是關于獲取文件路徑的問題,由于項目部署的時候是打包成jar包形式,所以在開發過程中時直接安照傳統的獲取方法沒有一點文件,但是當打包后部署,總是出錯。于是參考網上文章,先將文件讀出來到項目的臨時目錄下,然后再按正常方式加載該臨時文件; 還有一個問題至今沒有解決,就是關于生成PDF文件...
電腦空間不夠了?教你一個小秒招快速清理 Docker 占用的磁盤空間!
Docker 很占用空間,每當我們運行容器、拉取鏡像、部署應用、構建自己的鏡像時,我們的磁盤空間會被大量占用。 如果你也被這個問題所困擾,咱們就一起看一下 Docker 是如何使用磁盤空間的,以及如何回收。 docker 占用的空間可以通過下面的命令查看: TYPE 列出了docker 使用磁盤的 4 種類型: Images:所有鏡像占用的空間,包括拉取下來的鏡像,和本地構建的。 Con...

requests實現全自動PPT模板
http://www.1ppt.com/moban/ 可以免費的下載PPT模板,當然如果要人工一個個下,還是挺麻煩的,我們可以利用requests輕松下載 訪問這個主頁,我們可以看到下面的樣式 點每一個PPT模板的圖片,我們可以進入到詳細的信息頁面,翻到下面,我們可以看到對應的下載地址 點擊這個下載的按鈕,我們便可以下載對應的PPT壓縮包 那我們就開始做吧 首先,查看網頁的源代碼,我們可以看到每一...


Linux C系統編程-線程互斥鎖(四)
互斥鎖 互斥鎖也是屬于線程之間處理同步互斥方式,有上鎖/解鎖兩種狀態。 互斥鎖函數接口 1)初始化互斥鎖 pthread_mutex_init() man 3 pthread_mutex_init (找不到的情況下首先 sudo apt-get install glibc-doc sudo apt-get install manpages-posix-dev) 動態初始化 int pthread_...