Python爬蟲學習教程:Scrapy爬蟲框架入門
Python爬蟲學習教程:Scrapy概述
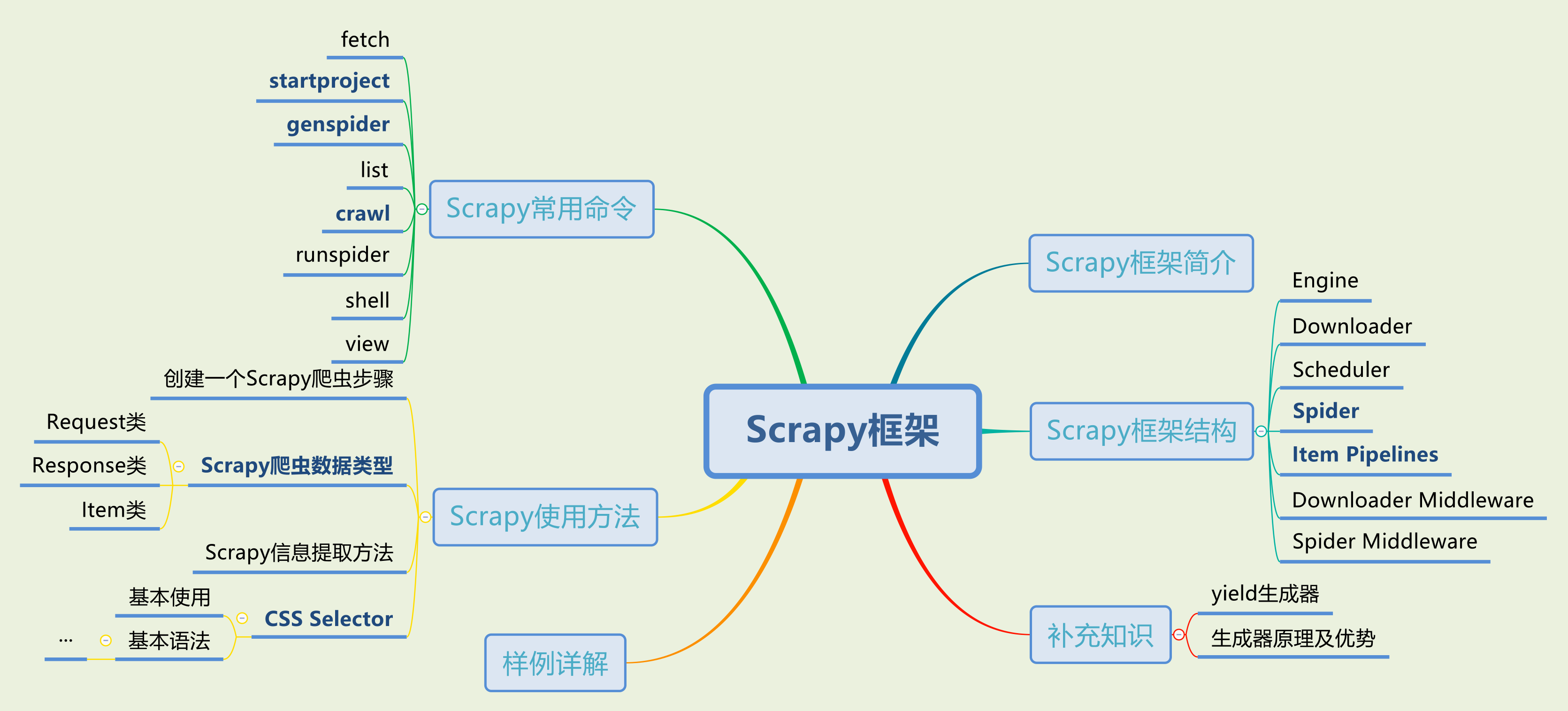
Scrapy是Python開發的一個非常流行的網絡爬蟲框架,可以用來抓取Web站點并從頁面中提取結構化的數據,被廣泛的用于數據挖掘、數據監測和自動化測試等領域。下圖展示了Scrapy的基本架構,其中包含了主要組件和系統的數據處理流程(圖中帶數字的紅色箭頭)。
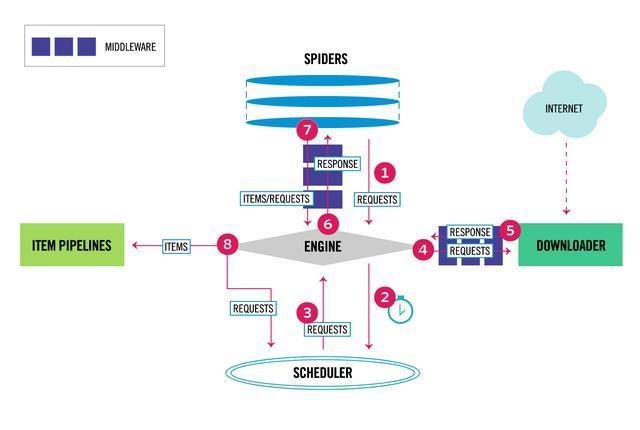
組件
- Scrapy引擎(Engine):Scrapy引擎是用來控制整個系統的數據處理流程。
- 調度器(Scheduler):調度器從Scrapy引擎接受請求并排序列入隊列,并在Scrapy引擎發出請求后返還給它們。
- 下載器(Downloader):下載器的主要職責是抓取網頁并將網頁內容返還給蜘蛛(Spiders)。
- 蜘蛛(Spiders):蜘蛛是有Scrapy用戶自定義的用來解析網頁并抓取特定URL返回的內容的類,每個蜘蛛都能處理一個域名或一組域名,簡單的說就是用來定義特定網站的抓取和解析規則。
- 條目管道(Item
Pipeline):條目管道的主要責任是負責處理有蜘蛛從網頁中抽取的數據條目,它的主要任務是清理、驗證和存儲數據。當頁面被蜘蛛解析后,將被發送到條目管道,并經過幾個特定的次序處理數據。每個條目管道組件都是一個Python類,它們獲取了數據條目并執行對數據條目進行處理的方法,同時還需要確定是否需要在條目管道中繼續執行下一步或是直接丟棄掉不處理。條目管道通常執行的任務有:清理HTML數據、驗證解析到的數據(檢查條目是否包含必要的字段)、檢查是不是重復數據(如果重復就丟棄)、將解析到的數據存儲到數據庫(關系型數據庫或NoSQL數據庫)中。 - 中間件(Middlewares):中間件是介于Scrapy引擎和其他組件之間的一個鉤子框架,主要是為了提供自定義的代碼來拓展Scrapy的功能,包括下載器中間件和蜘蛛中間件。
其實在前面的Python爬蟲學習教程中,有跟大家講到過Scrapy

數據處理流程
Scrapy的整個數據處理流程由Scrapy引擎進行控制,通常的運轉流程包括以下的步驟:
- 引擎詢問蜘蛛需要處理哪個網站,并讓蜘蛛將第一個需要處理的URL交給它。
- 引擎讓調度器將需要處理的URL放在隊列中。
- 引擎從調度那獲取接下來進行爬取的頁面。
- 調度將下一個爬取的URL返回給引擎,引擎將它通過下載中間件發送到下載器。
- 當網頁被下載器下載完成以后,響應內容通過下載中間件被發送到引擎;如果下載失敗了,引擎會通知調度器記錄這個URL,待會再重新下載。
- 引擎收到下載器的響應并將它通過蜘蛛中間件發送到蜘蛛進行處理。
- 蜘蛛處理響應并返回爬取到的數據條目,此外還要將需要跟進的新的URL發送給引擎。
- 引擎將抓取到的數據條目送入條目管道,把新的URL發送給調度器放入隊列中。
上述操作中的2-8步會一直重復直到調度器中沒有需要請求的URL,爬蟲停止工作。
安裝和使用Scrapy
可以先創建虛擬環境并在虛擬環境下使用pip安裝scrapy。
項目的目錄結構如下圖所示。
(venv) $ tree
.
|____ scrapy.cfg
|____ douban
| |____ spiders
| | |____ __init__.py
| | |____ __pycache__
| |____ __init__.py
| |____ __pycache__
| |____ middlewares.py
| |____ settings.py
| |____ items.py
| |____ pipelines.py
【說明】:Windows系統的命令行提示符下有tree命令,但是Linux和MacOS的終端是沒有tree命令的,可以用下面給出的命令來定義tree命令,其實是對find命令進行了定制并別名為tree。
alias tree="find . -print | sed -e 's;[^/]*/;|____;g;s;____|; |;g'"
Linux系統也可以通過yum或其他的包管理工具來安裝tree。
yum install tree
根據剛才描述的數據處理流程,基本上需要我們做的有以下幾件事情:
1.在items.py文件中定義字段,這些字段用來保存數據,方便后續的操作。
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class DoubanItem(scrapy.Item):
name = scrapy.Field()
year = scrapy.Field()
score = scrapy.Field()
director = scrapy.Field()
classification = scrapy.Field()
actor = scrapy.Field()
2.在spiders文件夾中編寫自己的爬蟲。
(venv) $ scrapy genspider movie movie.douban.com --template=crawl
# -*- coding: utf-8 -*-
import scrapy
from scrapy.selector import Selector
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from douban.items import DoubanItem
class MovieSpider(CrawlSpider):
name = 'movie'
allowed_domains = ['movie.douban.com']
start_urls = ['https://movie.douban.com/top250']
rules = (
Rule(LinkExtractor(allow=(r'https://movie.douban.com/top250\?start=\d+.*'))),
Rule(LinkExtractor(allow=(r'https://movie.douban.com/subject/\d+')), callback='parse_item'),
)
def parse_item(self, response):
sel = Selector(response)
item = DoubanItem()
item['name']=sel.xpath('//*[@id="content"]/h1/span[1]/text()').extract()
item['year']=sel.xpath('//*[@id="content"]/h1/span[2]/text()').re(r'\((\d+)\)')
item['score']=sel.xpath('//*[@id="interest_sectl"]/div/p[1]/strong/text()').extract()
item['director']=sel.xpath('//*[@id="info"]/span[1]/a/text()').extract()
item['classification']= sel.xpath('//span[@property="v:genre"]/text()').extract()
item['actor']= sel.xpath('//*[@id="info"]/span[3]/a[1]/text()').extract()
return item
說明:上面我們通過Scrapy提供的爬蟲模板創建了Spider,其中的rules中的LinkExtractor對象會自動完成對新的鏈接的解析,該對象中有一個名為extract_link的回調方法。Scrapy支持用XPath語法和CSS選擇器進行數據解析,對應的方法分別是xpath和css,上面我們使用了XPath語法對頁面進行解析,如果不熟悉XPath語法可以看看后面的補充說明。
到這里,我們已經可以通過下面的命令讓爬蟲運轉起來。
(venv)$ scrapy crawl movie
可以在控制臺看到爬取到的數據,如果想將這些數據保存到文件中,可以通過-o參數來指定文件名,Scrapy支持我們將爬取到的數據導出成JSON、CSV、XML、pickle、marshal等格式。
(venv)$ scrapy crawl moive -o result.json
3.在pipelines.py中完成對數據進行持久化的操作。
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import pymongo
from scrapy.exceptions import DropItem
from scrapy.conf import settings
from scrapy import log
class DoubanPipeline(object):
def __init__(self):
connection = pymongo.MongoClient(settings['MONGODB_SERVER'], settings['MONGODB_PORT'])
db = connection[settings['MONGODB_DB']]
self.collection = db[settings['MONGODB_COLLECTION']]
def process_item(self, item, spider):
#Remove invalid data
valid = True
for data in item:
if not data:
valid = False
raise DropItem("Missing %s of blogpost from %s" %(data, item['url']))
if valid:
#Insert data into database
new_moive=[{
"name":item['name'][0],
"year":item['year'][0],
"score":item['score'],
"director":item['director'],
"classification":item['classification'],
"actor":item['actor']
}]
self.collection.insert(new_moive)
log.msg("Item wrote to MongoDB database %s/%s" %
(settings['MONGODB_DB'], settings['MONGODB_COLLECTION']),
level=log.DEBUG, spider=spider)
return item
利用Pipeline我們可以完成以下操作:
- 清理HTML數據,驗證爬取的數據。
- 丟棄重復的不必要的內容。
- 將爬取的結果進行持久化操作。
4.修改settings.py文件對項目進行配置。
# -*- coding: utf-8 -*-
# Scrapy settings for douban project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://doc.scrapy.org/en/latest/topics/settings.html
# https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
# https://doc.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'douban'
SPIDER_MODULES = ['douban.spiders']
NEWSPIDER_MODULE = 'douban.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_3) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.54 Safari/536.5'
# Obey robots.txt rules
ROBOTSTXT_OBEY = True
# Configure maximum concurrent requests performed by Scrapy (default: 16)
# CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
DOWNLOAD_DELAY = 3
RANDOMIZE_DOWNLOAD_DELAY = True
# The download delay setting will honor only one of:
# CONCURRENT_REQUESTS_PER_DOMAIN = 16
# CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
COOKIES_ENABLED = True
MONGODB_SERVER = '120.77.222.217'
MONGODB_PORT = 27017
MONGODB_DB = 'douban'
MONGODB_COLLECTION = 'movie'
# Disable Telnet Console (enabled by default)
# TELNETCONSOLE_ENABLED = False
# Override the default request headers:
# DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
# }
# Enable or disable spider middlewares
# See https://doc.scrapy.org/en/latest/topics/spider-middleware.html
# SPIDER_MIDDLEWARES = {
# 'douban.middlewares.DoubanSpiderMiddleware': 543,
# }
# Enable or disable downloader middlewares
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
# DOWNLOADER_MIDDLEWARES = {
# 'douban.middlewares.DoubanDownloaderMiddleware': 543,
# }
# Enable or disable extensions
# See https://doc.scrapy.org/en/latest/topics/extensions.html
# EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
# }
# Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'douban.pipelines.DoubanPipeline': 400,
}
LOG_LEVEL = 'DEBUG'
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
HTTPCACHE_ENABLED = True
HTTPCACHE_EXPIRATION_SECS = 0
HTTPCACHE_DIR = 'httpcache'
HTTPCACHE_IGNORE_HTTP_CODES = []
HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
更多的Python爬蟲學習教程有會繼續為大家更新!同學們有什么好的建議也可以留言或者私信我!
智能推薦
【小白學爬蟲連載(8)】--scrapy框架入門教程
歡迎大家關注公眾號【哈希大數據】 歡迎大家關注公眾號【哈希大數據】 【小白學爬蟲連載(1)】-爬蟲框架簡介 【小白學爬蟲連載(2)】--Requests庫介紹 【小白學爬蟲連載(3)】--正則表達式詳細介紹 【小白學爬蟲連載(4)】-如何使用chrome分析目標網站 【小白學爬蟲連載(5)】--Beautiful Soup庫詳解 【小白學爬蟲連載(6)】--Selenium庫詳解 【小白學爬蟲連載...
Scrapy爬蟲框架入門(中) - Item Pipeline
更多文章請關注公眾號「我偶像龜叔」 當Item在Spider中被收集之后,它將會被傳遞到Item Pipeline,此時這里可以看作框架模型(model)。 item pipeline常見實現示例: 將爬取結果保存到 數據庫 中 下載項目圖片(item返回包含圖片字段) 數據清理、查重、驗證 … 本次案例會延伸上一篇文章,閱讀之前可以回顧上一篇文章。 Scrapy爬蟲框架入門(上) ...
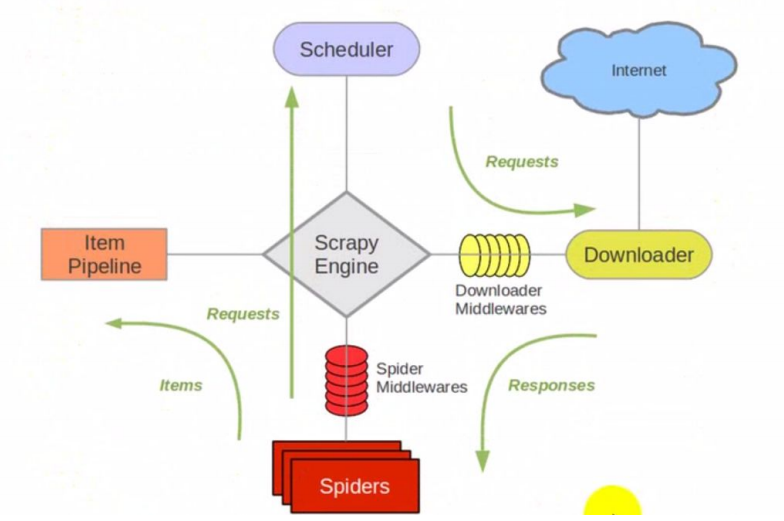
Python爬蟲入門五(Scrapy爬蟲框架)
目錄 一、Scrapy架構流程 1.簡介 2.優勢 3.架構流程圖 4.組件 二、Scrapy爬蟲步驟 三、案例(三國演義名著定向爬蟲項目) 1.新建Scrapy項目 2.明確目標(items.py) 3、制作爬蟲 4、存儲數據 一、Scrapy架構流程 1.簡介 Scrapy,Python開發的一個快速、高層次的屏幕抓取和web抓取框架,用于抓取web站點并從頁面中提取結...
Python 網絡爬蟲從0到1 (6):Scrapy框架入門最全詳解
前面介紹爬蟲分類的時候,我們就對各個網絡爬蟲工具的優缺點進行了分析。Requests庫適合進行輕量化、數據量較小、對速度不敏感的網頁爬取;而要進行數據量較大、對網頁爬取速度較為敏感的網站爬取,就需要使用Scrapy框架。Scrapy為什么是一個框架而不是庫?如何使用這樣一個性能更強但又較Requests庫復雜的工具進行網站爬取?請看本文講解。本文涵蓋了Scrapy框架開發的...

猜你喜歡

freemarker + ItextRender 根據模板生成PDF文件
1. 制作模板 2. 獲取模板,并將所獲取的數據加載生成html文件 2. 生成PDF文件 其中由兩個地方需要注意,都是關于獲取文件路徑的問題,由于項目部署的時候是打包成jar包形式,所以在開發過程中時直接安照傳統的獲取方法沒有一點文件,但是當打包后部署,總是出錯。于是參考網上文章,先將文件讀出來到項目的臨時目錄下,然后再按正常方式加載該臨時文件; 還有一個問題至今沒有解決,就是關于生成PDF文件...
電腦空間不夠了?教你一個小秒招快速清理 Docker 占用的磁盤空間!
Docker 很占用空間,每當我們運行容器、拉取鏡像、部署應用、構建自己的鏡像時,我們的磁盤空間會被大量占用。 如果你也被這個問題所困擾,咱們就一起看一下 Docker 是如何使用磁盤空間的,以及如何回收。 docker 占用的空間可以通過下面的命令查看: TYPE 列出了docker 使用磁盤的 4 種類型: Images:所有鏡像占用的空間,包括拉取下來的鏡像,和本地構建的。 Con...

requests實現全自動PPT模板
http://www.1ppt.com/moban/ 可以免費的下載PPT模板,當然如果要人工一個個下,還是挺麻煩的,我們可以利用requests輕松下載 訪問這個主頁,我們可以看到下面的樣式 點每一個PPT模板的圖片,我們可以進入到詳細的信息頁面,翻到下面,我們可以看到對應的下載地址 點擊這個下載的按鈕,我們便可以下載對應的PPT壓縮包 那我們就開始做吧 首先,查看網頁的源代碼,我們可以看到每一...


Linux C系統編程-線程互斥鎖(四)
互斥鎖 互斥鎖也是屬于線程之間處理同步互斥方式,有上鎖/解鎖兩種狀態。 互斥鎖函數接口 1)初始化互斥鎖 pthread_mutex_init() man 3 pthread_mutex_init (找不到的情況下首先 sudo apt-get install glibc-doc sudo apt-get install manpages-posix-dev) 動態初始化 int pthread_...