機器學習入門之《統計學習方法》筆記——樸素貝葉斯法
??樸素貝葉斯(naive Bayes)法是基于貝葉斯定理與特征條件獨立假設的分類方法。
目錄
樸素貝葉斯法
??設輸入空間 為 維向量的集合,輸出空間為類標記集合 ,輸入特征向量 ,輸出類標記為 , 是 和 的聯合概率分布,數據集
由 獨立同分布產生。
??樸素貝葉斯法就是通過訓練集來學習聯合概率分布 .具體就是從先驗概率分布和條件概率分布入手,倆概率相乘即可得聯合概率。
??稱之為樸素是因為將條件概率的估計簡化了,對條件概率分布作了條件獨立性假設,這也是樸素貝葉斯法的基石,假設如下
??這個公式在之前的假設條件下等價于
??對于給定的輸入向量 ,通過學習到的模型計算后驗概率分布 ,后驗分布中最大的類作為 的輸出結果,根據貝葉斯定理可知后驗概率為
??其中
??所有 的 都是相同的,這樣我們可以把輸出結果化簡成
??這樣,就了解了樸素貝葉斯法的基本原理了,下面要介紹的是參數估計。
參數估計
極大似然估計
??我們已經知道對于給定的輸入向量 ,其輸出結果可以表示為
??可以使用極大似然估計法來估計相應的概率。先驗概率 的極大似然估計是
?? 設第 個特征 可能的取值的集合為 ,條件概率 的極大似然估計是
學習與分類算法
??下面給出樸素貝葉斯法的學習與分類算法。
算法 (樸素貝葉斯算法)
輸入: 訓練數據 , 其中 , , , , ;實例 ;
輸出: 實例 的分類.
(1) 計算先驗概率及條件概率
(2) 對于給定的實例 ,計算
(3) 確定實例 的類
例子:試由下表的訓練數據學習一個樸素貝葉斯分類器并確定
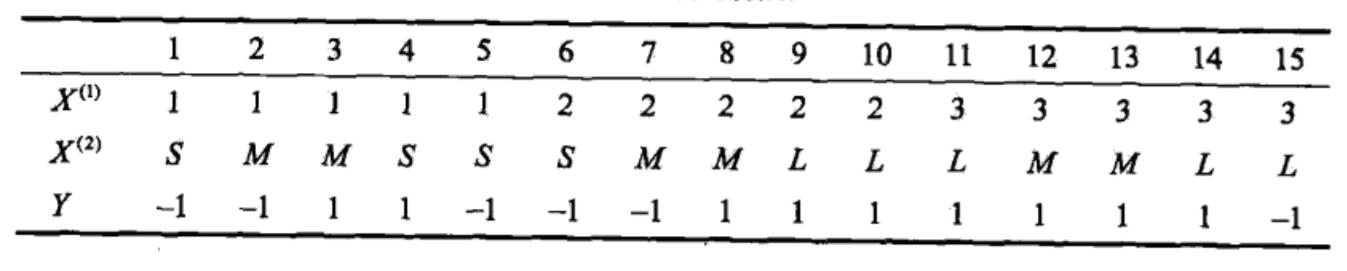
python代碼如下:
import numpy as np
#構造NB分類器
def Train(X_train, Y_train, feature):
global class_num,label
class_num = 2 #分類數目
label = [1, -1] #分類標簽
feature_len = 3 #特征長度
#構造3×2的列表
feature = [[1, 'S'],
[2, 'M'],
[3, 'L']]
prior_prob = np.zeros(class_num) # 初始化先驗概率
con_prob = np.zeros((class_num,feature_len,2)) # 初始化條件概率
positive_count = 0 #統計正類
negative_count = 0 #統計負類
for i in range(len(Y_train)):
if Y_train[i] == 1:
positive_count += 1
else:
negative_count += 1
prior_prob[0] = positive_count / len(Y_train) #求得正類的先驗概率
prior_prob[1] = negative_count / len(Y_train) #求得負類的先驗概率
'''
con_prob是一個2*3*2的三維列表,第一維是類別分類,第二維和第三維是一個3*2的特征分類
'''
#分為兩個類別
for i in range(class_num):
#對特征按行遍歷
for j in range(feature_len):
#遍歷數據集,并依次做判斷
for k in range(len(Y_train)):
if Y_train[k] == label[i]: #相同類別
if X_train[k][0] == feature[j][0]:
con_prob[i][j][0] += 1
if X_train[k][1] == feature[j][1]:
con_prob[i][j][1] += 1
class_label_num = [positive_count, negative_count] #存放各類型的數目
for i in range(class_num):
for j in range(feature_len):
con_prob[i][j][0] = con_prob[i][j][0] / class_label_num[i] #求得i類j行第一個特征的條件概率
con_prob[i][j][1] = con_prob[i][j][1] / class_label_num[i] #求得i類j行第二個特征的條件概率
return prior_prob,con_prob
#給定數據進行分類
def Predict(testset, prior_prob, con_prob, feature):
result = np.zeros(len(label))
for i in range(class_num):
for j in range(len(feature)):
if feature[j][0] == testset[0]:
conA = con_prob[i][j][0]
if feature[j][1] == testset[1]:
conB = con_prob[i][j][1]
result[i] = conA * conB * prior_prob[i]
result = np.vstack([result,label])
return result
def main():
X_train = [[1, 'S'], [1, 'M'], [1, 'M'], [1, 'S'], [1, 'S'],
[2, 'S'], [2, 'M'], [2, 'M'], [2, 'L'], [2, 'L'],
[3, 'L'], [3, 'M'], [3, 'M'], [3, 'L'], [3, 'L']]
Y_train = [-1, -1, 1, 1, -1, -1, -1, 1, 1, 1, 1, 1, 1, 1, -1]
#構造3×2的列表
feature = [[1, 'S'],
[2, 'M'],
[3, 'L']]
testset = [2, 'S']
prior_prob, con_prob= Train(X_train, Y_train, feature)
result = Predict(testset, prior_prob, con_prob, feature)
print('The result:',result)
main()
??得到結果:
The result: [[ 0.02222222 0.06666667]
[ 1. -1. ]]
貝葉斯估計
??極大似然估計的一個可能是會出現所要估計的概率值為0的情況,這時會影響到后驗概率的計算結果,解決這一問題的方法是采用貝葉斯估計,具體的只需要在極大似然估計的基礎上加多一個參數即可。
??當 時就是最大似然估計。常取 ,這時稱為拉普拉斯平滑(Laplace smoothing)。
小結
??樸素貝葉斯法高效,且易于實現,但是其缺點就是分類的性能不一定很高。
參考文章
智能推薦

統計學習筆記六----樸素貝葉斯
前言 樸素貝葉斯(naive Bayes)算法是基于貝葉斯定理和特征條件獨立假設的分類方法,它是一種生成模型! 對于給定的訓練數據集,首先基于特征條件獨立假設學習輸入/輸出的聯合概率分布;然后基于此模型,對給定的輸入x,利用貝葉斯定理求出后驗概率最大的輸出y。 樸素貝葉斯算法實現簡單,學習與預測的效率都很高,是一種常用的方法。 條件獨立性的假設 樸素貝葉斯法對條件概率分布作了條件獨立性...
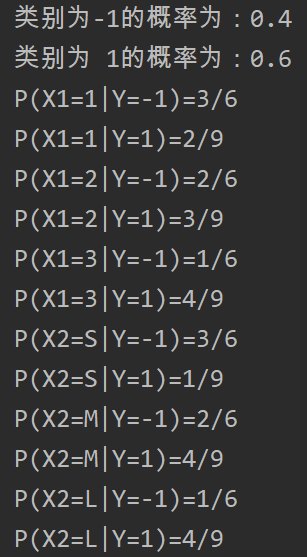
樸素貝葉斯(naive Bayes)的python實現——基于《統計學習方法》例題的編程求解
樸素貝葉斯方法是基于貝葉斯定理與特征條件獨立假設的分類方法。認為樣本的特征X與標簽y服從聯合概率分布P(X, y),所有的樣本都是基于這個概率分布產生的。由于條件概率P(X=x|Y=y)的參數具有指數數量級,因此進行估算切實際。貝葉斯法對條件概率分布做了條件獨立性假設,從而減少了模型的復雜性,增加了模型的泛化能力,減少了過擬合的風險。 #后驗概率最大化 可以證明,期望風險最小化準則可以得到后驗概率...

《統計學習方法》代碼全解析——第四部分樸素貝葉斯
1.樸素貝葉斯法是典型的生成學習方法。生成方法由訓練數據學習聯合概率分布 (,) P(X,Y) ,然后求得后驗概率分布 (|) P(Y|X) 。具體來說,利用訓練數據學習 (|) P(X|Y) 和 () P(Y) 的估計,得到聯合概率分布: (,)=()(|) 概率估計方法可以是極大似然估計或貝葉斯估計。 2.樸素貝葉斯法的基本假設是條件獨立性 這是一個較強的假...

統計學習方法第四章(樸素貝葉斯)及Python實現及sklearn實現
1原理 樸素貝葉斯 貝葉斯:根據貝葉斯定理p(y|x) = p(y)p(x|y)/p(x).選擇p(y|x) 最大的類別作為x的類別。可知樸素貝葉斯是監督學習的生成模型(由聯合概率分布得到概率分布)。選擇p(y|x) 最大的類別時,分母相同,所以簡化為比較 p(y)p(x|y)的大小。 樸素: 計算p(x|y)的概率,假設x是n維向量,每維向量有sn個取值可能,則就要計算類別*(sn的n次方)次。...
機器學習入門之《統計學習方法》筆記整理——K近鄰法
目錄 k近鄰算法 算法 k近鄰法 k近鄰模型 距離度量 k值選擇 分類決策規則 k近鄰法的實現kd樹 構造kd樹 算法 構造平衡kd樹 搜索kd樹 算法 用kd樹的最近鄰搜索 小結 參考文章 k近鄰算法 k近鄰算法,即是給定一個訓練數據集,對新的輸入實例,在訓練數據集中找到與該實例最鄰近的K個實例,這K個實例的多數屬于某個類,就把該輸入實例分類到這個類中。 &e...
猜你喜歡

機器學習入門?樸素貝葉斯
本文適用讀者: 了解樸素貝葉斯,并且python version 為 3.x 樸素貝葉斯的優缺點及其適用性: 優點:在數據較少的情況下仍然有效,可以處理多類別問題 缺點:對于輸入數據的準備方式較為敏感 使用數據類型:標稱型數據 樸素貝葉斯的一般過程: 1.收集數據:可以使用任何方法.本章使用RSS源 2.準備數據:需要數值型或者布爾型數據 3.分析數據:有大量特征時,繪制特征作用不大,此時使用直方...


freemarker + ItextRender 根據模板生成PDF文件
1. 制作模板 2. 獲取模板,并將所獲取的數據加載生成html文件 2. 生成PDF文件 其中由兩個地方需要注意,都是關于獲取文件路徑的問題,由于項目部署的時候是打包成jar包形式,所以在開發過程中時直接安照傳統的獲取方法沒有一點文件,但是當打包后部署,總是出錯。于是參考網上文章,先將文件讀出來到項目的臨時目錄下,然后再按正常方式加載該臨時文件; 還有一個問題至今沒有解決,就是關于生成PDF文件...
電腦空間不夠了?教你一個小秒招快速清理 Docker 占用的磁盤空間!
Docker 很占用空間,每當我們運行容器、拉取鏡像、部署應用、構建自己的鏡像時,我們的磁盤空間會被大量占用。 如果你也被這個問題所困擾,咱們就一起看一下 Docker 是如何使用磁盤空間的,以及如何回收。 docker 占用的空間可以通過下面的命令查看: TYPE 列出了docker 使用磁盤的 4 種類型: Images:所有鏡像占用的空間,包括拉取下來的鏡像,和本地構建的。 Con...

requests實現全自動PPT模板
http://www.1ppt.com/moban/ 可以免費的下載PPT模板,當然如果要人工一個個下,還是挺麻煩的,我們可以利用requests輕松下載 訪問這個主頁,我們可以看到下面的樣式 點每一個PPT模板的圖片,我們可以進入到詳細的信息頁面,翻到下面,我們可以看到對應的下載地址 點擊這個下載的按鈕,我們便可以下載對應的PPT壓縮包 那我們就開始做吧 首先,查看網頁的源代碼,我們可以看到每一...