Python爬蟲(九)——京東比價定向爬蟲
文章目錄
Python爬蟲(九)——京東比價定向爬蟲
- 目標:獲取淘寶搜索頁面的信息,提取其中的商品名稱和價格。
- 要求:淘寶的搜索接口 翻頁的處理
- 技術路線:requests-re
判斷可行性
查看鏈接
第一頁:
https://search.jd.com/Search?keyword=相機&enc=utf-8&page=1
第二頁:
https://search.jd.com/Search?keyword=相機&enc=utf-8&page=3
第三頁:
https://search.jd.com/Search?keyword=相機&enc=utf-8&page=5
由上我們可以猜測最后的s變量和頁碼有關。
查看robots協議
打開淘寶的robots.txt。發現:
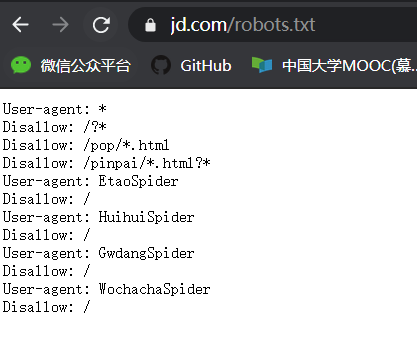
結果我們發現它不允許我們爬取。不過我們如果行為就像人類的行為,沒有過度消耗服務器的資源僅僅是用于學習和探索那是沒有問題的。
程序的設計
步驟
- 提交上屏搜索請求,循環獲取頁面
- 對于每個頁面,提取商品名稱和價格信息
- 將信息輸出到屏幕上
方法
def getHTMLText(url)
def getHTMLText(url):
try: # 利用前面的代碼框架返回頁面的text
r=requests.get(url,timeout=30)
r.raise_for_status()
r.encoding=r.apparent_encoding
return r.text
except:
return ''
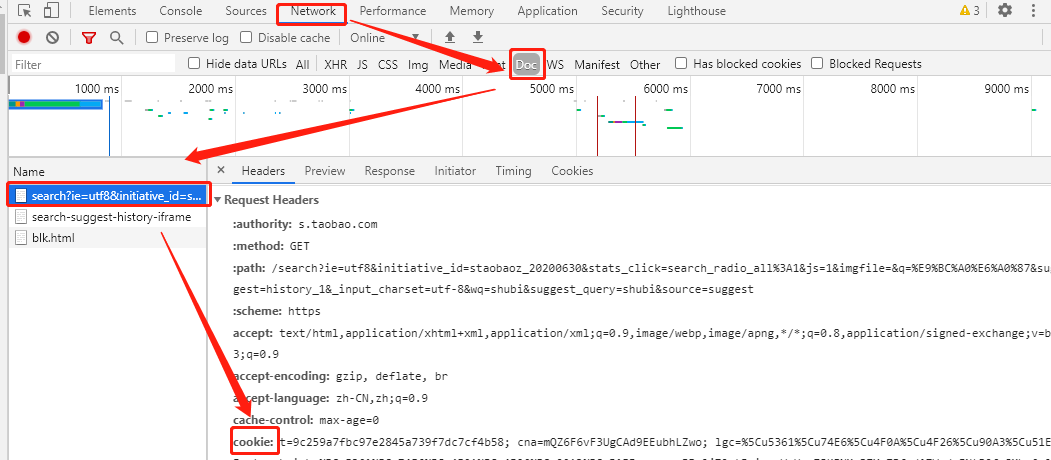
這時我們發現無法得到結果,查看后發現界面跳轉到了登錄界面,于是我們加入cookies參數來解決這個問題。
那么如何得到cookie呢?我們打開這個網頁,按下f12打開開發者模式:
然后選中network刷新一下界面,在最上面找到Search?keyword=這個包:
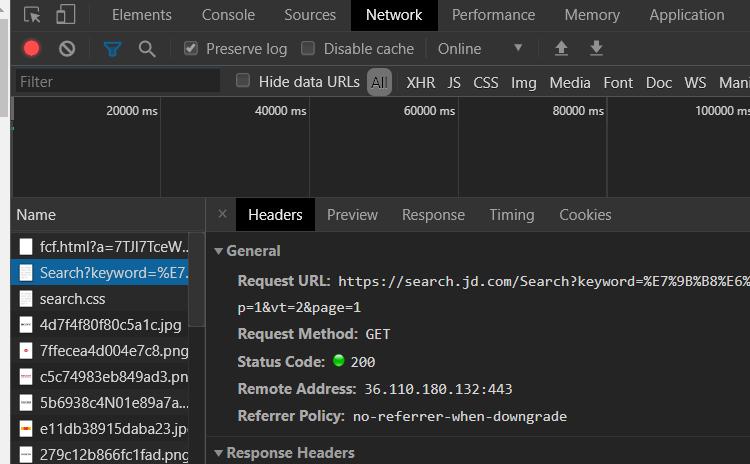
然后我們在右邊的Request Hearders中就能找到自己的cookie:
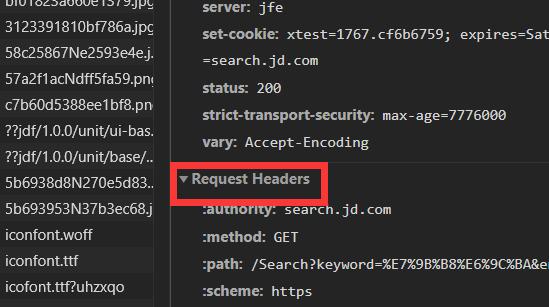
代碼:
def getHTMLText(url):
try: # 利用前面的代碼框架返回頁面的text
r = requests.get(url, timeout=30, headers={'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36'}, cookies={
'cookie': '你的cookie'})
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ''
parsePage(ilt, html)
我們首先打開網頁的源代碼找到商品的信息。

我們發現淘寶商品的名字在標簽em中且都有相機,而價格在標簽i中且都是由數字.數字組成,于是利用以下兩個正則表達式表示:
#價格
r'\<i\>[\d]*\.[\d]*\<\/i\>'
#商品名稱
r'\<em\>.*相機.*\<\/em\>'
那么方法的代碼為:
def parsePage(ilt, html):
try:
# 商品價格由數字和小數點組成所以用[\d.]*\.[\d]*來表示
plt = re.findall(r'\<i\>[\d]*\.[\d]*\<\/i\>', html)
tlt = re.findall(r'\<em\>.*相機.*\<\/em\>', html)
for i in range(len(plt)):
price = plt[i][3:-4] # 直接利用python字符串特性得到價格
if re.findall(r'.*京品數碼.*', tlt[i]) or re.findall(r'.*京東國際.*', tlt[i]) or re.findall(r'.*京東超市.*', tlt[i]):
print('here')
# 通過最小匹配來得到第一個<之前的內容
title = re.findall(r'span\>.*?\<', tlt[i])[0][5:-1]+'相機'
else:
# 同樣的方法獲得其他類型商品名稱
title = re.findall(r'em\>.*?\<', tlt[i])[0][3:-1]+'相機'
ilt.append([price, title])
except:
print("")
printGoodLists(ilt)
最后將結果打印出來,這里我也遇到了一些問題:無法打印出界面中所有的商品,我用BeautifulSoup+re分析也是同樣的結果,如果你知道問題的所在希望能夠給我留言或者私信我。
def printGoodLists(ilt):
tplt = "{:4}\t{:8}\t{:16}" # 給出打印模板,第一個長度為4,第二個長度為8,最后一個長度為16
print(tplt.format("序號", "價格", "商品名稱"))
count = 0
for goods in ilt:
count += 1
print(tplt.format(count, goods[0], goods[1]))
print("")
完整代碼
#encoding='utf-8
import requests
import re
def getHTMLText(url):
try: # 利用前面的代碼框架返回頁面的text
r = requests.get(url, timeout=30, headers={'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36'}, cookies={
'cookie': '你的cookie'})
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ''
def parsePage(ilt, html):
try:
# 商品價格由數字和小數點組成所以用[\d.]*\.[\d]*來表示
plt = re.findall(r'\<i\>[\d]*\.[\d]*\<\/i\>', html)
tlt = re.findall(r'\<em\>.*相機.*\<\/em\>', html)
for i in range(len(plt)):
price = plt[i][3:-4] # 直接利用python字符串特性得到價格
if re.findall(r'.*京品數碼.*', tlt[i]) or re.findall(r'.*京東國際.*', tlt[i]) or re.findall(r'.*京東超市.*', tlt[i]):
# 通過最小匹配來得到第一個<之前的內容
title = re.findall(r'span\>.*?\<', tlt[i])[0][5:-1]+'相機'
else:
# 同樣的方法獲得其他類型商品名稱
title = re.findall(r'em\>.*?\<', tlt[i])[0][3:-1]+'相機'
ilt.append([price, title])
except:
print("")
def printGoodLists(ilt):
tplt = "{:4}\t{:8}\t{:16}" # 給出打印模板,第一個長度為4,第二個長度為8,最后一個長度為16
print(tplt.format("序號", "價格", "商品名稱"))
count = 0
for goods in ilt:
count += 1
print(tplt.format(count, goods[0], goods[1]))
print("")
goods = '相機'
depth = 3
startUrl = 'https://search.jd.com/Search?keyword='+goods+'&enc=utf-8'
infoList = []
for i in range(depth): # 這里通過循環來查詢多個頁面并保存再infoList中
try:
page = i*2+1
url = startUrl+'&page='+str(page) # 利用之前觀察的頁面url來設定每個頁面的url
html = getHTMLText(url)
parsePage(infoList, html)
except:
continue
printGoodLists(infoList)
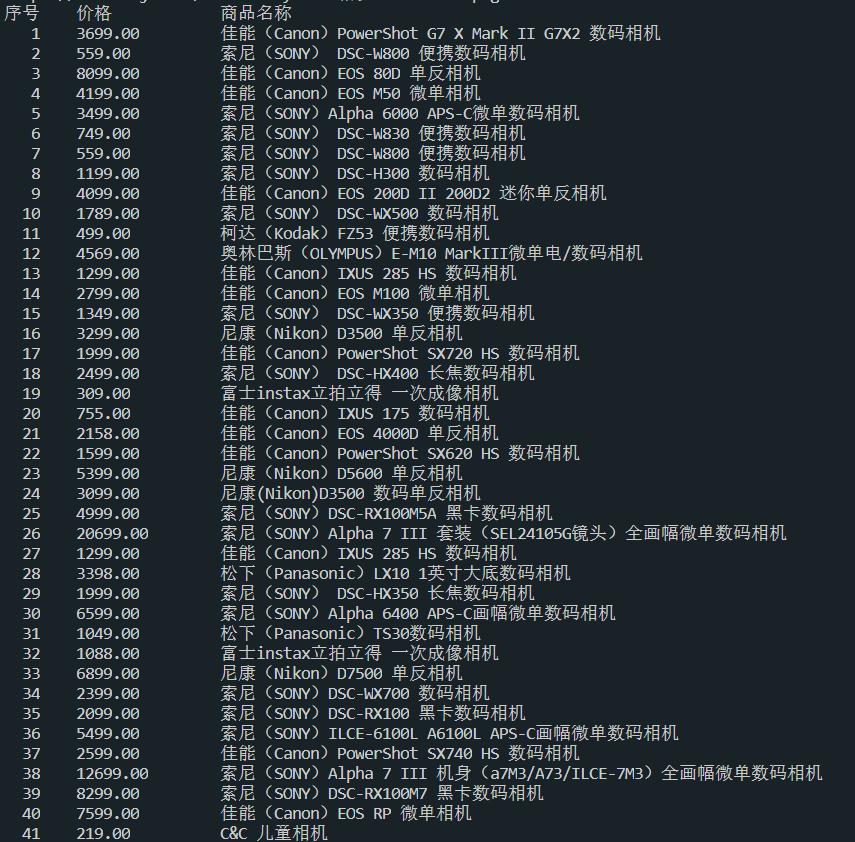
運行結果:
智能推薦
網絡爬蟲之實戰 4-2 淘寶商品比價定向爬蟲
文章截圖均來自中國大學mooc Python網絡爬蟲與信息提取的教程,以上僅作為我的個人學習筆記。 下面是教程鏈接:https://www.icourse163.org/learn/BIT-1001870001?tid=1450316449#/learn/content?type=detail&id=1214620493&cid=1218397635&replay=true...

爬蟲03_re庫03_淘寶商品比價定向爬蟲
1.實例分析 定向爬蟲可行性: 訪問https://www.taobao.com/robots.txt 得User-agent: Baiduspider Disallow: / User-agent: baiduspider Disallow: / 這里對根目錄進行限制,但我們僅是拿來學習技術實現,不做商業用途且騷擾。 2.程序結構設計 3.代碼實現 關于寫headers信息:...
優化淘寶商品比價定向爬蟲--爬蟲的瀏覽器偽裝
優化淘寶商品比價定向爬蟲--爬蟲的瀏覽器偽裝 原代碼問題 淘寶Robots協議 User-Agent 查找headers和cookie 完整代碼 原代碼問題 爬取不到任何內容處理 原因:由于淘寶的設置,雖然可以requests爬取頁面內容,但正則表達式會匹配不到任何內容; 解決:替換headers,偽裝瀏覽器向服務器發起請求 淘寶Robots協議 Robots協議,是國際上搜索引擎對所有網站內容抓...


freemarker + ItextRender 根據模板生成PDF文件
1. 制作模板 2. 獲取模板,并將所獲取的數據加載生成html文件 2. 生成PDF文件 其中由兩個地方需要注意,都是關于獲取文件路徑的問題,由于項目部署的時候是打包成jar包形式,所以在開發過程中時直接安照傳統的獲取方法沒有一點文件,但是當打包后部署,總是出錯。于是參考網上文章,先將文件讀出來到項目的臨時目錄下,然后再按正常方式加載該臨時文件; 還有一個問題至今沒有解決,就是關于生成PDF文件...
猜你喜歡
電腦空間不夠了?教你一個小秒招快速清理 Docker 占用的磁盤空間!
Docker 很占用空間,每當我們運行容器、拉取鏡像、部署應用、構建自己的鏡像時,我們的磁盤空間會被大量占用。 如果你也被這個問題所困擾,咱們就一起看一下 Docker 是如何使用磁盤空間的,以及如何回收。 docker 占用的空間可以通過下面的命令查看: TYPE 列出了docker 使用磁盤的 4 種類型: Images:所有鏡像占用的空間,包括拉取下來的鏡像,和本地構建的。 Con...

requests實現全自動PPT模板
http://www.1ppt.com/moban/ 可以免費的下載PPT模板,當然如果要人工一個個下,還是挺麻煩的,我們可以利用requests輕松下載 訪問這個主頁,我們可以看到下面的樣式 點每一個PPT模板的圖片,我們可以進入到詳細的信息頁面,翻到下面,我們可以看到對應的下載地址 點擊這個下載的按鈕,我們便可以下載對應的PPT壓縮包 那我們就開始做吧 首先,查看網頁的源代碼,我們可以看到每一...


Linux C系統編程-線程互斥鎖(四)
互斥鎖 互斥鎖也是屬于線程之間處理同步互斥方式,有上鎖/解鎖兩種狀態。 互斥鎖函數接口 1)初始化互斥鎖 pthread_mutex_init() man 3 pthread_mutex_init (找不到的情況下首先 sudo apt-get install glibc-doc sudo apt-get install manpages-posix-dev) 動態初始化 int pthread_...

統計學習方法 - 樸素貝葉斯
引入問題:一機器在良好狀態生產合格產品幾率是 90%,在故障狀態生產合格產品幾率是 30%,機器良好的概率是 75%。若一日第一件產品是合格品,那么此日機器良好的概率是多少。 貝葉斯模型 生成模型與判別模型 判別模型,即要判斷這個東西到底是哪一類,也就是要求y,那就用給定的x去預測。 生成模型,是要生成一個模型,那就是誰根據什么生成了模型,誰就是類別y,根據的內容就是x 以上述例子,判斷一個生產出...