DC學院學習筆記(十一):數據預處理—數據清理
終于到了數據存儲與預處理的最后一講了,感覺講得還不錯!下面來看看數據的預處理吧!
- 格式轉換
- 缺失數據
- 異常數據
- 數據標準化操作
準備知識
Pandas
Pandas逐漸成為了一個非常大的庫,在數據處理問題方面表現優秀,是一個不可或缺的工具,Pandas中包含兩個主要的數據結構:Series & DataFrame
更多請看:
Seaborn
Seaborn是基于matplotlib的繪圖庫,可以制作更多更美觀的圖形,如Example gallery中也可以看到很多關于圖像的示例。這個繪圖庫可以很好地輔助我們對數據進行第一步的觀察
更多請看:
Seaborn tutorial
格式轉換
如Python記錄時間的方式,不能夠直接實現減運算,就需要進行轉換
- pandas.to_datetime
缺失數據、異常數據
- 忽略缺失數據
- 直接標記
- 利用平均值、最常出現值進行填充
標準化
一般在分析數據時進行操作
數據清理示例
這里還是用iris數據集舉例
import pandas
users = pandas.read_csv("iris.csv")## 讀取前幾條
users.head()| Id | SepalLengthCm | SepalWidthCm | PetalLengthCm | PetalWidthCm | Species | |
|---|---|---|---|---|---|---|
| 0 | 1 | 5.1 | 3.5 | 1.4 | 0.2 | Iris-setosa |
| 1 | 2 | 4.9 | 3.0 | 1.4 | 0.2 | Iris-setosa |
| 2 | 3 | 4.7 | 3.2 | 1.3 | 0.2 | Iris-setosa |
| 3 | 4 | 4.6 | 3.1 | 1.5 | 0.2 | Iris-setosa |
| 4 | 5 | 5.0 | 3.6 | 1.4 | 0.2 | Iris-setosa |
users.tail()| Id | SepalLengthCm | SepalWidthCm | PetalLengthCm | PetalWidthCm | Species | |
|---|---|---|---|---|---|---|
| 145 | 146 | 6.7 | 3.0 | 5.2 | 2.3 | Iris-virginica |
| 146 | 147 | 6.3 | 2.5 | 5.0 | 1.9 | Iris-virginica |
| 147 | 148 | 6.5 | 3.0 | 5.2 | 2.0 | Iris-virginica |
| 148 | 149 | 6.2 | 3.4 | 5.4 | 2.3 | Iris-virginica |
| 149 | 150 | 5.9 | 3.0 | 5.1 | 1.8 | Iris-virginica |
#查看平均值,標準差等,只針對數字的屬性
users.describe()| Id | SepalLengthCm | SepalWidthCm | PetalLengthCm | PetalWidthCm | |
|---|---|---|---|---|---|
| count | 150.000000 | 150.000000 | 150.000000 | 150.000000 | 150.000000 |
| mean | 75.500000 | 5.843333 | 3.054000 | 3.758667 | 1.198667 |
| std | 43.445368 | 0.828066 | 0.433594 | 1.764420 | 0.763161 |
| min | 1.000000 | 4.300000 | 2.000000 | 1.000000 | 0.100000 |
| 25% | 38.250000 | 5.100000 | 2.800000 | 1.600000 | 0.300000 |
| 50% | 75.500000 | 5.800000 | 3.000000 | 4.350000 | 1.300000 |
| 75% | 112.750000 | 6.400000 | 3.300000 | 5.100000 | 1.800000 |
| max | 150.000000 | 7.900000 | 4.400000 | 6.900000 | 2.500000 |
#查看數據的屬性,150條,每條有6個屬性
users.shape(150, 6)
users.loc[1:3,'SepalWidthCm']1 3.0
2 3.2
3 3.1
Name: SepalWidthCm, dtype: float64
#去除有NaN的數據
users['SepalLengthCm'].dropna()[1:5]1 4.9
2 4.7
3 4.6
4 5.0
Name: SepalLengthCm, dtype: float64
#用seaborn做一個簡單的可視化
import seaborn
#因為我用的是jupyter notebook,所以要加上這句話
%matplotlib inline
#箱線圖
seaborn.boxplot(users['PetalWidthCm'].dropna())

#柱狀圖
seaborn.distplot(users['PetalWidthCm'].dropna())
#異常數據處理:篩選PetalWidthCm<2及PetalWidthCm>0.5
users_new=users[users["PetalWidthCm"]<2]
users_new=users_new[users_new["PetalWidthCm"]>0.5]
#再重新看一下柱狀圖
seaborn.distplot(users_new["PetalWidthCm"].dropna())
智能推薦
數據分析學習筆記之數據預處理
數據分析學習筆記 數據加載 數據清洗 數據過濾 數據轉換 字符串矢量化計算 數據合并 數據加載 我們首先需要將手機到的數據加載到內存中,才能進行進一步的操作。pandas提供了非常多的讀取數據的函數,分別應用在各種數據源環境中,我們常用的函數為: read_csv read_table read_sql 注意: read_csv與read_table功能相同,只不過默認使用的分隔符不同。read_...
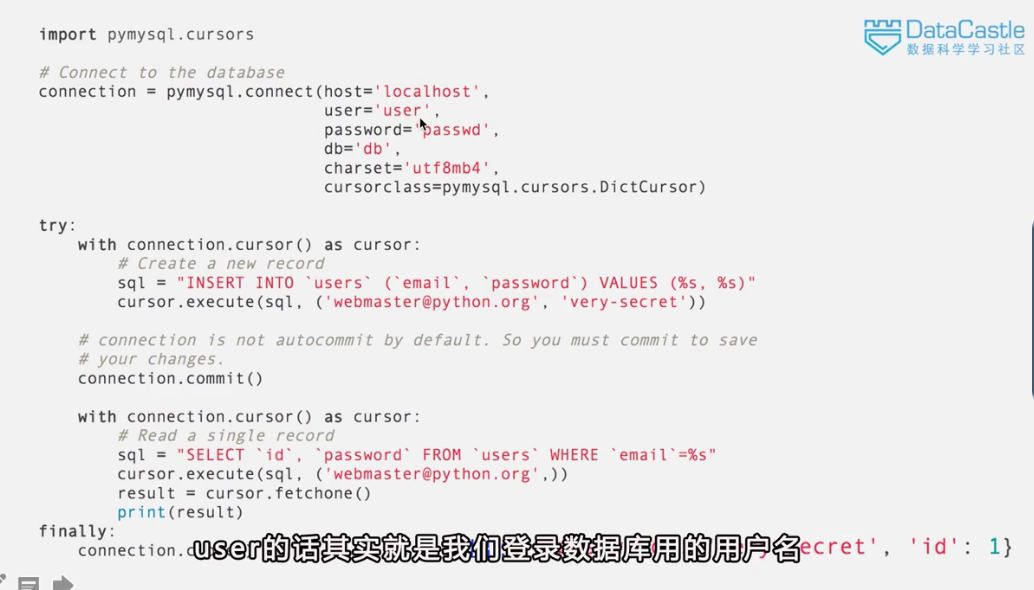
DC學院數據分析師(入門)學習筆記----利用python操作MySQL數據庫
安裝pymysql 原理介紹: 使用pymysql指令來連接數據庫 host:要連接的數據庫的IP地址,如果是遠程的,這里指定遠程的ip地址 user:登錄的賬戶名,如果登錄的是最高權限賬戶則為root password:對應的密碼 db:要連接的數據庫的名稱,如需要訪問存儲的IRIS數據庫,則輸入'IRIS' charset:設置編碼格式,如utf8mb4就是一個編碼格式 cursorclass...

機器學習--數據預處理
歸一化 目的 使得單一特征對于最后的結果影響不太大,尤其是錯誤值 API 代碼演示 問題:如果數據中異常點較多,會有什么影響 對于最大值或者最小值會產生影響,也就對于歸一化過程產生影響,所以這種歸一化方法的魯棒性比較差,只適合傳統精確小數據場景 標準化 目的:通過對原始數據進行變換把數據變換到均值為0,標準差為1范圍內,如果出現異常點,由于具有一定的數據量,少量的異常點對于平均值的影響并不大,從而...

機器學習-數據預處理
歸一化 標準化 標準化和歸一化的選擇 sklearn中的其他庫 特征編碼 離散型數據-針對標簽label Age Sex Embarked Survived 0 22.0 male S 0 1 38.0 female C 2 2 26.0 female S 2 離散型數據-針對特征 Age Sex Embarked Survived 0 22.0 male S 0 1 38.0 female C ...

猜你喜歡

sklearn學習——數據預處理
sklearn學習——數據預處理 模塊:sklearn.preprocessing 1 數據歸一化處理 歸一化之后的數據服從正態分布,公式如下: 在sklearn當中,我們使用preprocessing.MinMaxScaler來實現這個功能。MinMaxScaler有一個重要參數,feature_range,控制我們希望把數據壓縮到的范圍,默認是[0,1]。 代碼: 2數...


freemarker + ItextRender 根據模板生成PDF文件
1. 制作模板 2. 獲取模板,并將所獲取的數據加載生成html文件 2. 生成PDF文件 其中由兩個地方需要注意,都是關于獲取文件路徑的問題,由于項目部署的時候是打包成jar包形式,所以在開發過程中時直接安照傳統的獲取方法沒有一點文件,但是當打包后部署,總是出錯。于是參考網上文章,先將文件讀出來到項目的臨時目錄下,然后再按正常方式加載該臨時文件; 還有一個問題至今沒有解決,就是關于生成PDF文件...
電腦空間不夠了?教你一個小秒招快速清理 Docker 占用的磁盤空間!
Docker 很占用空間,每當我們運行容器、拉取鏡像、部署應用、構建自己的鏡像時,我們的磁盤空間會被大量占用。 如果你也被這個問題所困擾,咱們就一起看一下 Docker 是如何使用磁盤空間的,以及如何回收。 docker 占用的空間可以通過下面的命令查看: TYPE 列出了docker 使用磁盤的 4 種類型: Images:所有鏡像占用的空間,包括拉取下來的鏡像,和本地構建的。 Con...

requests實現全自動PPT模板
http://www.1ppt.com/moban/ 可以免費的下載PPT模板,當然如果要人工一個個下,還是挺麻煩的,我們可以利用requests輕松下載 訪問這個主頁,我們可以看到下面的樣式 點每一個PPT模板的圖片,我們可以進入到詳細的信息頁面,翻到下面,我們可以看到對應的下載地址 點擊這個下載的按鈕,我們便可以下載對應的PPT壓縮包 那我們就開始做吧 首先,查看網頁的源代碼,我們可以看到每一...