SQLite3源碼學習(28) Pager模塊之事務管理
事務管理是Pager模塊中最核心的要素,所有對數據庫數據的讀寫操作都在事務中進行。一個數據庫需要在多線程的使用環境下保持數據的一致性,雖然操作系統對磁盤的讀寫操作并不是原子,但是通過事務以及日志的回滾機制使每一個事務的執行都是原子的,所以即使出現系統崩潰或斷電,數據庫并不會因此而損壞。
在一個事務中,SQLite的Pager模塊通過有機地結合文件鎖,回滾日志和頁緩存來實現數據庫的ACID特性。在用戶程序并發訪問數據庫時,可以支持一個寫事務和多個讀事務,由于SQLite只實現了較粗粒度的文件鎖,同一時間最多只能有一個寫事務。
事務分為系統事務和用戶事務,用戶事務需要用BEGIN TRANSACTION和和COMMIT TRANSACTION明確指出事務的開始和結束,沒有明確指出時為系統事務,SQLite在每執行一條SQL語句時都會創建一個事務。本文主要講的是系統事務,系統事務又分為讀事務和寫事務。
1. 事務狀態
在SQLite數據庫中,事務分為7個狀態,Pager.eState變量存儲當前事務的狀態,這7個狀態的宏定義如下:
#define PAGER_OPEN 0
#define PAGER_READER 1
#define PAGER_WRITER_LOCKED 2
#define PAGER_WRITER_CACHEMOD 3
#define PAGER_WRITER_DBMOD 4
#define PAGER_WRITER_FINISHED 5
#define PAGER_ERROR 6OPEN狀態為事務的初始狀態,此時沒有加任何鎖,不能對數據庫進行讀寫操作。在PAGER_READER中,意味著Pager模塊已經獲得了共享鎖,可以開始一個讀事務。WRITER_LOCKED狀態表示數據庫開始一個寫事務,此時獲取了RESERVED鎖,但是并沒有對數據庫進行寫操作,在這個狀態下打開了一個回滾日志并往頭部寫入信息,其他讀事務可以正常進行。在WRITER_CACHEMOD狀態中,tree模塊可以向頁緩存里寫數據,同時還要先把原始數據備份到日志里,在WRITER_DBMOD中,RESERVED鎖被升級為獨占鎖,此時更新日志頭里的記錄數,并把日志文件和修改的數據庫頁面刷新到磁盤里。在WRITER_FINISHED狀態里,結束一個寫事務,將鎖恢復成共享鎖或無鎖狀態。如果出現I/O讀寫操作錯誤,此時將跳入ERROR狀態,在錯誤狀態下任何對數據庫的讀寫操作都會無效,錯誤將會返回到b-tree層處理。在源代碼的注釋中有對這些狀態更詳細的說明。
各個狀態的流程關系如下圖
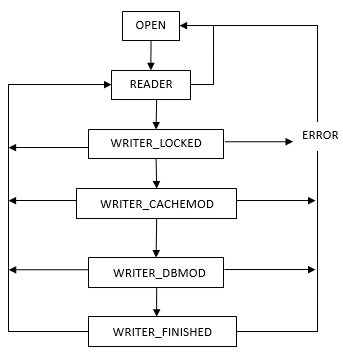
相應的關系轉換函數如下
** OPEN -> READER [sqlite3PagerSharedLock]
** READER -> OPEN [pager_unlock]
**
** READER -> WRITER_LOCKED [sqlite3PagerBegin]
** WRITER_LOCKED -> WRITER_CACHEMOD [pager_open_journal]
** WRITER_CACHEMOD -> WRITER_DBMOD [syncJournal]
** WRITER_DBMOD -> WRITER_FINISHED [sqlite3PagerCommitPhaseOne]
** WRITER_*** -> READER [pager_end_transaction]
**
** WRITER_*** -> ERROR [pager_error]
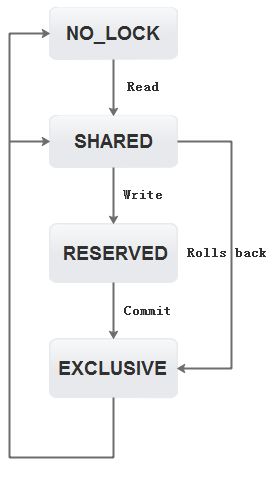
** ERROR -> OPEN [pager_unlock]在一個事務中,文件鎖對事務的原子性和隔離性起到了非常重要的作用,鎖的狀態保存在Pager.Lock里,在讀事務時需要先獲取共享鎖,開始一個寫事務時將共享鎖升級為保留鎖,最后提交時再升級為獨占鎖,如果需要日志回滾則直接從共享鎖升級為獨占鎖,鎖的各種狀態轉換如下圖所示
2. 讀事務
在開始一個讀事務時,需要獲取文件共享鎖,多個共享鎖可以同時存在,共享鎖不能和獨占鎖共存,當其他線程有寫事務時,在把修改的數據頁提交到磁盤的時候會獲取獨占鎖,此時將不能開始一個讀事務。
在開始一個讀事務之前,首先要判斷有沒有熱日志存在,如果有熱日志存在,表明上一個寫事務時存在系統崩潰的情況,數據庫可能損壞,需要回滾日志來恢復數據的原始內容。
由于事務的實現有很多繁瑣的細節,下面貼出的代碼都略去細節,只從主干的邏輯來分析代碼的實現過程。
每一個事務由B-Tree模塊調用sqlite3BtreeBeginTrans()函數發起,然后由lockBtree()函數獲取共享鎖和數據庫文件的第一頁數據,數據庫的第一頁并不存儲數據,而是存儲數據庫的相關信息。如果沒有獲取成功,將會持續循環直到成功為止。
while( pBt->pPage1==0 &&SQLITE_OK==(rc = lockBtree(pBt)) );
lockBtree()做的工作主要是以下3部分:
1.獲取共享鎖
rc = sqlite3PagerSharedLock(pBt->pPager);
2.獲取第一頁數據
rc =btreeGetPage(pBt, 1, &pPage1, 0);
3.根據第一頁數據校驗數據庫的有效性
在sqlite3PagerSharedLock()除了獲取共享鎖之外,如果存在熱日志,還需要對日志回滾來恢復數據庫內容,實現代碼如下,省去了變量的定義、各種條件判斷和錯誤處理
int sqlite3PagerSharedLock(Pager *pPager){
//獲取共享鎖,如果需要在失敗后重復嘗試
//可以設置xBusyHandler回調函數來等待成功或超時
rc = pager_wait_on_lock(pPager, SHARED_LOCK);
/*判斷是否為熱日志,做的工作有以下3點
** 1.判斷是否存在保留鎖,如果存在,說明存在其他寫事務,此
** 日志是剛創建的,并非熱日志。
** 2.如果數據庫文件長度為0,說明是一個這是一個新的數據庫
** 文件,不需要回滾,只需刪除日志即可
** 3.如果不存在保留鎖,讀取日志文件的第一個字節,如果不為0
** 此時判定日志文件為熱日志
*/
if( pPager->eLock<=SHARED_LOCK ){
rc = hasHotJournal(pPager, &bHotJournal);
}
//如果存在熱日志,開始回滾
if( bHotJournal ){
//先獲取獨占鎖
rc = pagerLockDb(pPager, EXCLUSIVE_LOCK);
//打開日志文件
……
//回滾前先同步日志,這里沒看懂
//回滾的時候并沒有改變日志的內容,似乎不需要
rc = pagerSyncHotJournal(pPager);
//開始回滾
rc = pager_playback(pPager, !pPager->tempFile);
//回滾完畢后,將鎖恢復為共享鎖
pagerUnlockDb(pPager, SHARED_LOCK);
}
//獲取共享鎖后,判斷數據庫是否更改,根據第一頁的
//第24字節的File change counter來判斷
//如果有更改,將頁緩存里的內容丟棄
rc = sqlite3OsRead(pPager->fd, &dbFileVers, sizeof(dbFileVers), 24);
if( memcmp(pPager->dbFileVers, dbFileVers, sizeof(dbFileVers))!=0 ){
pager_reset(pPager);
}
//更改事務狀態為PAGER_READER
pPager->eState = PAGER_READER;
pPager->hasHeldSharedLock = 1;
}pager_playback()函數就是把日志里的內容回滾到數據庫,首先從日志頭里讀取記錄數,將每一個記錄頁寫回到數據庫磁盤文件,簡要代碼如下
static int pager_playback(Pager *pPager, int isHot){
//讀取文件長度
rc = sqlite3OsFileSize(pPager->jfd, &szJ);
while( 1 ){
//讀取記錄數,存在nRec變量里
rc = readJournalHdr(pPager, isHot, szJ, &nRec, &mxPg);
for(u=0; u<nRec; u++){
//根據journalOff讀取日志頁,日志頁的頭部記錄了頁號
//根據頁號把數據頁寫入到數據庫文件的對應位置
rc = pager_playback_one_page(pPager,&pPager->journalOff,0,1,0);
}
}
}在得到共享鎖后,就可以調用sqlite3PagerGet()來讀取數據頁了,這個函數調用了pPager->xGet()接口,如果使用Mmap,注冊的是getPageMMap,否則注冊的是getPageNormal,getPageNormal的實現如下
static int getPageNormal(
Pager *pPager, /* The pager open on the database file */
Pgno pgno, /* Page number to fetch */
DbPage **ppPage, /* Write a pointer to the page here */
int flags /* PAGER_GET_XXX flags */
){
//從頁緩存中獲取數據頁
pBase = sqlite3PcacheFetch(pPager->pPCache, pgno, 3);
//如果獲取失敗,釋放掉未使用的頁
if( pBase==0 ){
rc = sqlite3PcacheFetchStress(pPager->pPCache, pgno, &pBase);
}
//初始化pPg的一些信息
pPg = *ppPage = sqlite3PcacheFetchFinish(pPager->pPCache, pgno, pBase);
//如果pPg->pPager存在,說明頁緩存里已經有數據,cache命中
//直接返回cache中的結果即可
if( pPg->pPager && !noContent ){
pPager->aStat[PAGER_STAT_HIT]++;
return SQLITE_OK;
}else{
//如果沒有命中,先設置數據頁對應的Pager對象
pPg->pPager = pPager;
//如果不需要數據,將數據區初始化為0
if( !isOpen(pPager->fd) || pPager->dbSize<pgno || noContent ){
memset(pPg->pData, 0, pPager->pageSize);
} else{
//否則從磁盤中讀取數據
//根據pPg->pgno和pPager->pageSize找到偏移地址
// iFrame用作WAL模式,暫時不管
rc = readDbPage(pPg, iFrame);
}
}
}每讀一頁數據都要對應地調用sqlite3PagerUnref ()來釋放對這一頁的引用,如果沒有其他事務引用數據頁,則將該頁添加到LRU鏈表里,讀完數據后調用btreeEndTransaction()來結束一個讀事務,如果btree里沒有其他事務了,那么調用releasePageNotNull(pPage1)釋放數據庫的第一頁數據,如果pPCache里沒有頁被引用,調用pager_unlock(pPager)釋放共享鎖,將事務恢復到OPEN狀態
3. 寫事務
一個寫事務是在一個讀事務的基礎上進行的,因為開始一個寫事務時也要先獲取共享鎖,讀取要修改的數據頁到內存,在此基礎上再把共享鎖升級為保留鎖,從而開始一個寫事務。
按照第一節描述的事務狀態的變化來一步步分析寫事務是如何完成的:
1. sqlite3PagerBegin
此時開始一個寫事務,獲取保留鎖,將事務狀態升級為WRITER_LOCKED
2. pager_open_journal
此時打開一個日志文件,并向日志頭里寫入初始化信息,把事務狀態升級為WRITER_CACHEMOD,相關代碼如下:
if( rc==SQLITE_OK ){
rc = sqlite3JournalOpen (
pVfs, pPager->zJournal, pPager->jfd, flags, nSpill
);
}
if( rc==SQLITE_OK ){
/* TODO: Check if all of these are really required. */
pPager->nRec = 0;
pPager->journalOff = 0;
pPager->setMaster = 0;
pPager->journalHdr = 0;
rc = writeJournalHdr(pPager);
}
pPager->eState = PAGER_WRITER_CACHEMOD;3. sqlite3PagerWrite
將要寫的頁加入到頁緩存的dirty鏈表里面,把頁的flag設為可寫
pPg->flags |= PGHDR_WRITEABLE;
如果頁號小于數據庫長度,將頁寫入到日志文件
if( pPg->pgno<=pPager->dbOrigSize ){
rc = pagerAddPageToRollbackJournal(pPg);
if( rc!=SQLITE_OK ){
return rc;
}
}
static SQLITE_NOINLINE int pagerAddPageToRollbackJournal(PgHdr *pPg){
i64 iOff = pPager->journalOff;
//寫入頁號
rc = write32bits(pPager->jfd, iOff, pPg->pgno);
if( rc!=SQLITE_OK ) return rc;
//寫入數據頁內容
rc = sqlite3OsWrite(pPager->jfd, pData2, pPager->pageSize, iOff+4);
if( rc!=SQLITE_OK ) return rc;
//寫入校驗字節
rc = write32bits(pPager->jfd, iOff+pPager->pageSize+4, cksum);
//修改寫日志的偏移地址
pPager->journalOff += 8 + pPager->pageSize;
//增加記錄數
pPager->nRec++;
}如果頁號大于數據庫長度,此時要向數據庫尾部添加新頁,將flag置為PGHDR_NEED_SYNC,并變更數據庫長度
pPg->flags |= PGHDR_NEED_SYNC;
if( pPager->dbSize<pPg->pgno ){
pPager->dbSize = pPg->pgno;
}此后b-tree層就可以對頁緩存里的數據進行修改了。
4.sqlite3PagerCommitPhaseOne
當b-tree層已經對頁緩存修改數據完畢,需要把修改提交到數據庫,此時需要把鎖升級為獨占鎖,在這段時間內不能開始新的讀事務,如果還有正在進行的讀事務先等其處理完畢。
提交事務時先調用pager_incr_changecounter()對文件的change counter加1,接著調用syncJournal()對日志刷盤,關于日志的部分已經在之前的文章已經講過了,日志刷盤后會把事務狀態更新為WRITER_DBMOD。
然后把所有的臟頁都刷新到磁盤,關鍵代碼如下
rc = pager_write_pagelist(pPager,sqlite3PcacheDirtyList(pPager->pPCache));
static int pager_write_pagelist(Pager *pPager, PgHdr *pList){
//遍歷臟頁鏈表寫入數據
while( rc==SQLITE_OK && pList ){
Pgno pgno = pList->pgno;
i64 offset = (pgno-1)*(i64)pPager->pageSize;
rc = sqlite3OsWrite(pPager->fd, pData, pPager->pageSize, offset);
pList = pList->pDirty;
}
}寫完后清理所有的臟頁,把事務狀態更新為WRITER_FINISHED
sqlite3PcacheCleanAll(pPager->pPCache);5.sqlite3PagerCommitPhaseTwo
此時數據庫已經更新完畢,最后調用pager_end_transaction()結束整個寫事務,把事務狀態恢復到PAGER_READER,并刪除日志文件,如果數據庫文件長度變短,需要截斷多余的文件內容,另外現在鎖的狀態還是獨占鎖,需要將鎖降級為共享鎖。
以上5點就是整個數據庫寫事務的過程,通過日志和文件鎖實現了事務的原子提交特性。
4.參考資料
Atomic Commit In SQLite
http://www.sqlite.org/atomiccommit.html
SQLite的原子提交原理
https://blog.csdn.net/javensun/article/details/8515690
SQLite3源碼學習(24) Pager模塊之事務鎖的實現1
https://blog.csdn.net/pfysw/article/details/80100236
SQLite3源碼學習(26) Pager模塊之日志管理
https://blog.csdn.net/pfysw/article/details/80191235
SQLite3源碼學習(8)Pager模塊概述及初始化
https://blog.csdn.net/pfysw/article/details/79121815
SQLite入門與分析(四)---Page Cache之事務處理(1)
http://www.cnblogs.com/hustcat/archive/2009/02/26/1398558.html
SQLite入門與分析(四)---Page Cache之事務處理(2)
http://www.cnblogs.com/hustcat/category/175618.html
SQLite入門與分析(四)---Page Cache之事務處理(3)
http://www.cnblogs.com/hustcat/archive/2009/02/26/1398826.html
SQLite學習筆記(七)&&事務處理
智能推薦


freemarker + ItextRender 根據模板生成PDF文件
1. 制作模板 2. 獲取模板,并將所獲取的數據加載生成html文件 2. 生成PDF文件 其中由兩個地方需要注意,都是關于獲取文件路徑的問題,由于項目部署的時候是打包成jar包形式,所以在開發過程中時直接安照傳統的獲取方法沒有一點文件,但是當打包后部署,總是出錯。于是參考網上文章,先將文件讀出來到項目的臨時目錄下,然后再按正常方式加載該臨時文件; 還有一個問題至今沒有解決,就是關于生成PDF文件...
電腦空間不夠了?教你一個小秒招快速清理 Docker 占用的磁盤空間!
Docker 很占用空間,每當我們運行容器、拉取鏡像、部署應用、構建自己的鏡像時,我們的磁盤空間會被大量占用。 如果你也被這個問題所困擾,咱們就一起看一下 Docker 是如何使用磁盤空間的,以及如何回收。 docker 占用的空間可以通過下面的命令查看: TYPE 列出了docker 使用磁盤的 4 種類型: Images:所有鏡像占用的空間,包括拉取下來的鏡像,和本地構建的。 Con...

requests實現全自動PPT模板
http://www.1ppt.com/moban/ 可以免費的下載PPT模板,當然如果要人工一個個下,還是挺麻煩的,我們可以利用requests輕松下載 訪問這個主頁,我們可以看到下面的樣式 點每一個PPT模板的圖片,我們可以進入到詳細的信息頁面,翻到下面,我們可以看到對應的下載地址 點擊這個下載的按鈕,我們便可以下載對應的PPT壓縮包 那我們就開始做吧 首先,查看網頁的源代碼,我們可以看到每一...

猜你喜歡

Linux C系統編程-線程互斥鎖(四)
互斥鎖 互斥鎖也是屬于線程之間處理同步互斥方式,有上鎖/解鎖兩種狀態。 互斥鎖函數接口 1)初始化互斥鎖 pthread_mutex_init() man 3 pthread_mutex_init (找不到的情況下首先 sudo apt-get install glibc-doc sudo apt-get install manpages-posix-dev) 動態初始化 int pthread_...

統計學習方法 - 樸素貝葉斯
引入問題:一機器在良好狀態生產合格產品幾率是 90%,在故障狀態生產合格產品幾率是 30%,機器良好的概率是 75%。若一日第一件產品是合格品,那么此日機器良好的概率是多少。 貝葉斯模型 生成模型與判別模型 判別模型,即要判斷這個東西到底是哪一類,也就是要求y,那就用給定的x去預測。 生成模型,是要生成一個模型,那就是誰根據什么生成了模型,誰就是類別y,根據的內容就是x 以上述例子,判斷一個生產出...

styled-components —— React 中的 CSS 最佳實踐
https://zhuanlan.zhihu.com/p/29344146 Styled-components 是目前 React 樣式方案中最受關注的一種,它既具備了 css-in-js 的模塊化與參數化優點,又完全使用CSS的書寫習慣,不會引起額外的學習成本。本文是 styled-components 作者之一 Max Stoiber 所寫,首先總結了前端組件化樣式中的最佳實踐原則,然后在此基...

19.vue中封裝echarts組件
19.vue中封裝echarts組件 1.效果圖 2.echarts組件 3.使用組件 按照組件格式整理好數據格式 傳入組件 home.vue 4.接口返回數據格式...