SQLite3源碼學習(27) Bitmap算法
1. 算法背景
假如有100個不重復的數存放在文件里,怎么確定某個數是否在這100個數中?
一般可以這樣做,將這100個數讀取到內存并存放在char a[100]的數組里,只需遍歷這100個數即可。
那么假如有10億個不重復的數呢,最大的數是2^32-1,這個時候顯然內存存放不了那么多數,那么只能先將一部分數據讀到內存,做完判斷后再去讀一部分數據,直到讀完10億個數為止,這個時候不但需要遍歷很久,而且還要大量的磁盤I/O操作,在時間上是不可承受的。
為了加快查找,可以申請一個4G的超大數組char a[2^32],把每個數都映射成數組的下標,如果某個數x存在,就將a[x-1]置1,不存在就置0,這是時候只需一次取地址操作即可。但是內存顯然更大,我們觀察到上面的方法用一個字節來標記一個數是否存在,其實只需1bit就可以標記,這樣就可以把內存減小8倍。
網上所說的Bitmap算法正是這么一個算法,把一個數映射成一個bit來標記。下圖說明了簡單的示例,有2個字節,標記1~15,其中{1,2,5,7,11}存在,則將相應的bit位置1,否則置0。
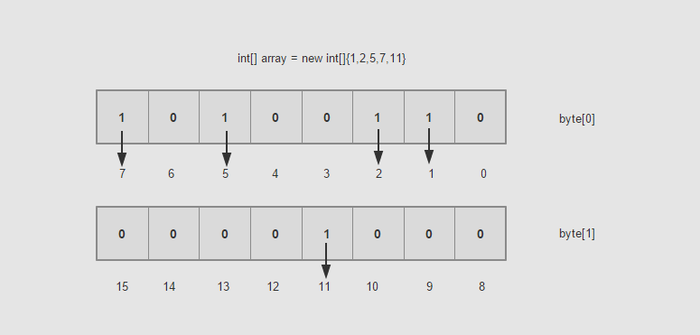
代碼實現起來很簡單,假設sz是數據范圍的上限,用pV來表示一個bit數組。
unsigned char *pV = 0;
pV = sqlite3MallocZero( (sz+7)/8 + 1 ); //申請sz/8字節大小的的內存
那么SETBIT(pV,1000)就是把pV中的第1000比特置1,CLEARBIT(pV,1000)就是把pV中的第1000比特置0,TESTBIT(pV,1000)就是判斷1000是否在pV中存在,宏定義實現如下
#define SETBIT(V,I) V[I>>3] |= (1<<(I&7))
#define CLEARBIT(V,I) V[I>>3] &= ~(1<<(I&7))
#define TESTBIT(V,I) (V[I>>3]&(1<<(I&7)))!=02. 算法改進
雖然用bit來表示一個數可以減小內存空間,但也需要500M的內存,內存占用還是太大,我們發現即使數據量有10億,也有大量的bit位是空著,而且一般情況下數據量也沒這么大,這就導致了大量內存空間的浪費。
針對上述問題,SQLite對Bitmap算法做了改進,也就是需要多少數,就申請多少bit的空間,算法的實現是非常精妙的,下面我們就來欣賞一下。
SQLite主要用Bitmap算法來存放文件數據頁編號,最大可以到2^32-1。首先定義一個Bitvec的結構體,該結構體如下。
typedef struct Bitvec Bitvec;
struct Bitvec {
//Bitmap中存放的最大的數為2^32-1
u32 iSize; /* Maximum bit index. Max iSize is 4,294,967,296. */
//當前Bitvec對象中hash元素的個數
u32 nSet; /* Number of bits that are set - only valid for aHash
** element. Max is BITVEC_NINT. For BITVEC_SZ of 512,
** this would be 125. */
//把iSize分割后的子對象的iSize大小
u32 iDivisor; /* Number of bits handled by each apSub[] entry. */
/* Should >=0 for apSub element. */
/* Max iDivisor is max(u32) / BITVEC_NPTR + 1. */
/* For a BITVEC_SZ of 512, this would be 34,359,739. */
//以下是一個聯合體,根據iSize、nSet和iDivisor的大小來決定使用哪一種結構
union {
BITVEC_TELEM aBitmap[BITVEC_NELEM]; /* Bitmap representation */
u32 aHash[BITVEC_NINT]; /* Hash table representation */
Bitvec *apSub[BITVEC_NPTR]; /* Recursive representation */
} u;
};
相關宏定義如下:
/* Bitvec 結構體的大小*/
#define BITVEC_SZ 512
/* 一個字節類型,占8bit*/
#define BITVEC_TELEM u8
#define BITVEC_NELEM 500 // 即aBitmap的大小占512-4*3=500字節
#define BITVEC_NINT 125 //即aHash的長度,占125*4=500字節
#define BITVEC_NPTR 125 //即apSub的長度,占125*4=500字節
#define BITVEC_NBIT 4000//即一個Bitvec對象所表示的最大bit數量500*8
為了清晰起見,把聯合體中的宏定義替換掉得到
union {
u8 aBitmap[500]; /* Bitmap representation */
u32 aHash[125]; /* Hash table representation */
Bitvec *apSub[125]; /* Recursive representation */
} u;
那么自然要問aBitmap、aHash和apSub都有什么作用,根據Bitvec對象所處的狀態來決定用哪個數據結構來表示。假設p是一個Bitvec對象,其關系如下圖
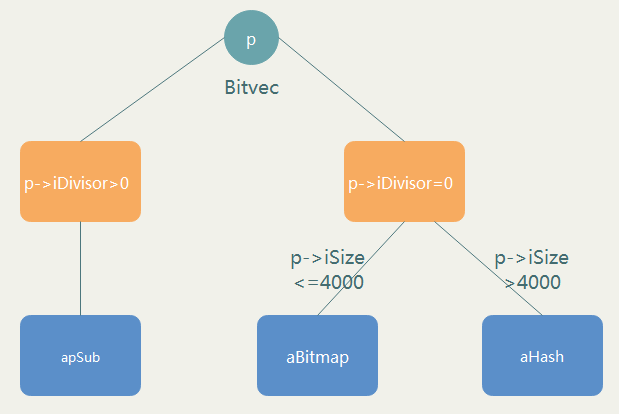
當p沒有被分割時,即p-> iDivisor=0時,如果p-> iSize<=4000當前對象的元素個數小于4000,則用aBitmap的每個bit位來存放數據,當p->iSize>4000時,由于aBitmap已經不夠存放,所以用aHash來存放數據,最多存放124個,當超過時把p平均分割成125份,每一份長度為p-> iDivisor,當p被分割后,聯合體u用apSub來表示每個分割后的子對象。
3. 代碼實現
首先創建一個Bitvec對象,設置iSize為該對象的數據長度:
Bitvec *sqlite3BitvecCreate(u32 iSize){
Bitvec *p;
assert( sizeof(*p)==BITVEC_SZ );
p = sqlite3MallocZero( sizeof(*p) );
if( p ){
p->iSize = iSize;
}
return p;
}接下來在Bitvec對象p中用sqlite3BitvecSet() 函數把數據i對應的bit位置1,如上一節所說,這里分為3種情況考慮,還使用了遞歸的技術代碼如下。
int sqlite3BitvecSet(Bitvec *p, u32 i){
u32 h;
if( p==0 ) return SQLITE_OK;
assert( i>0 );
assert( i<=p->iSize );
i--;//在SQLite中頁號從1開始,在Bitmap中從第0比特開始
//這里需要注意的是p->iDivisor>0必有p->iSize > 4000
//因為只有p->iSize >4000,才有必要分割
//但是當p->iSize >4000,不一定需要分割,可能有p->iDivisor=0
//如果該對象分割后,找出最后沒有被分割的子對象
while((p->iSize > BITVEC_NBIT) && p->iDivisor) {
//由第70行p->iDivisor = (p->iSize + 125 - 1)/125可知
// p->iSize被分割成了125份,存放在 p->u.apSub子對象中
//bin為子對象的索引
u32 bin = i/p->iDivisor;
i = i%p->iDivisor;
if( p->u.apSub[bin]==0 ){
//子對象不存在新建一個
p->u.apSub[bin] = sqlite3BitvecCreate( p->iDivisor );
if( p->u.apSub[bin]==0 ) return SQLITE_NOMEM_BKPT;
}
p = p->u.apSub[bin];
}
//此時p->iDivisor=0,如果p->iSize<4000,把i在p->u.aBitmap中的相應的bit置1
if( p->iSize<=BITVEC_NBIT ){
p->u.aBitmap[i/BITVEC_SZELEM] |= 1 << (i&(BITVEC_SZELEM-1));//BITVEC_SZELEM=8
return SQLITE_OK;
}
//如果p->iSize>4000則把i存放在對應的hash數組里
h = BITVEC_HASH(i++);//i%125
/* if there wasn't a hash collision, and this doesn't */
/* completely fill the hash, then just add it without */
/* worring about sub-dividing and re-hashing. */
//當對應的hash表中還沒有元素時
if( !p->u.aHash[h] ){
if (p->nSet<(BITVEC_NINT-1)) {
//hash表中元素個數小于125時,直接對p->u.aHash[h]賦值
goto bitvec_set_end;
} else {
//hash表元素超了后,將對象分割
goto bitvec_set_rehash;
}
}
/* there was a collision, check to see if it's already */
/* in hash, if not, try to find a spot for it */
//如果元素存在沖突,找一個空閑的hash元素存放
//由上面的代碼知道這個空閑的元素是必定存在的
do {
if( p->u.aHash[h]==i ) return SQLITE_OK;
h++;
if( h>=BITVEC_NINT ) h = 0;
} while( p->u.aHash[h] );
/* we didn't find it in the hash. h points to the first */
/* available free spot. check to see if this is going to */
/* make our hash too "full". */
bitvec_set_rehash:
// BITVEC_MXHASH是125/2=62
//如果hash表中元素存在沖突,那么大于62就開始分割
if( p->nSet>=BITVEC_MXHASH ){
unsigned int j;
int rc;
//分配1個臨時的hash數組
u32 *aiValues = sqlite3StackAllocRaw(0, sizeof(p->u.aHash));
if( aiValues==0 ){
return SQLITE_NOMEM_BKPT;
}else{
//把原來的數存放在臨時數組里
memcpy(aiValues, p->u.aHash, sizeof(p->u.aHash));
memset(p->u.apSub, 0, sizeof(p->u.apSub));
p->iDivisor = (p->iSize + BITVEC_NPTR - 1)/BITVEC_NPTR;
//這里采用遞歸調用來創建分割后i所在的子對象
rc = sqlite3BitvecSet(p, i);
//對象p分割后,對原來存放在hash表中的元素重新設定
for(j=0; j<BITVEC_NINT; j++){
if( aiValues[j] ) rc |= sqlite3BitvecSet(p, aiValues[j]);
}
sqlite3StackFree(0, aiValues);
return rc;
}
}
bitvec_set_end:
p->nSet++;
p->u.aHash[h] = i;
return SQLITE_OK;
}理解了數值如何在Bitvec對象存放后,其他接口也就不難理解了,只要分3種情況討論即可。
int sqlite3BitvecTestNotNull(Bitvec *p, u32 i)
該函數判斷元素i是否在對象p中,如果p被分割了,那么找到i在哪個分割后的子對象里,在子對象里根據p->iSize是否小于4000來決定在aBitmap中找還是在aHash里找。
void sqlite3BitvecClear(Bitvec *p, u32 i, void *pBuf)
清除對象p中的數值i,同上分為3種情況處理,pBuf是用來重新排列hash表時的臨時數組。
void sqlite3BitvecDestroy(Bitvec *p)
銷毀對象p和p中包含的所有子對象
4. 測試代碼
SQLite提供了Tcl的測試接口:
int sqlite3BitvecBuiltinTest(int sz, int *aOp)
sz為設置Bitvec對象的數據長度,aOp是一組操作命令,每4個元素組成一組操作命令,最后以0結尾
aOp[0]為命令號, aOp[1]為重復的次數,aOp[2]為賦值的頁號,aOp[3]為每次重復后頁號的遞增值。
Tcl腳本使用方法為:
sqlite3BitvecBuiltinTest SIZE PROGRAM
參數SIZE的值傳給sz,PROGRAM的值傳給aOp
使用舉例:
sqlite3BitvecBuiltinTest 400000 {1 400000 1 1 0}
該命令表示設置對象的長度為400000,{1 400000 1 1 0}為一個命令組,從頁號1開始對Bitvec對象賦值,重復400000次,每次遞增1
更多的測試用例見bitvec.test文件。
智能推薦
經典算法- BitMap
原文鏈接https://www.jianshu.com/p/6082a2f7df8e 一、問題引入 舉一個例子,有一個無序有界int數組{1,2,5,7},初步估計占用內存4X4=16字節,這倒是沒什么奇怪的,但是假如有10億個這樣的數呢,如果這樣的一個大的數據做查找和排序,那估計內存也崩潰了,有人說,這些數據可以不用一次性加載,那就是要存盤了,存盤必然消耗IO。我們提倡的是高性能,這個方案直接不...
27.Qt操作sqlite3數據庫
1 sqlite3操作編程 問題1 驅動無法加載 解決辦法將Qt自帶安裝目錄下的sql文件拷貝到可執行文件目錄下。 2 連接數據庫 3 查詢數據庫 4 數據庫插入...
Sqlite3入門學習(一)
Linux環境下sqlite3的安裝及常用Linux API說明 環境安裝 Step1:一般的linux可能會自帶sqlite,在安裝之前先使用sqlite3命令檢測一下,若顯示并未安裝,則進行下述操作 Step2:先到 https://www.sqlite.org/download.html ,下載sqlite-autoconf-*.tar.gz壓縮包 Step3:下載完了...


freemarker + ItextRender 根據模板生成PDF文件
1. 制作模板 2. 獲取模板,并將所獲取的數據加載生成html文件 2. 生成PDF文件 其中由兩個地方需要注意,都是關于獲取文件路徑的問題,由于項目部署的時候是打包成jar包形式,所以在開發過程中時直接安照傳統的獲取方法沒有一點文件,但是當打包后部署,總是出錯。于是參考網上文章,先將文件讀出來到項目的臨時目錄下,然后再按正常方式加載該臨時文件; 還有一個問題至今沒有解決,就是關于生成PDF文件...
猜你喜歡
電腦空間不夠了?教你一個小秒招快速清理 Docker 占用的磁盤空間!
Docker 很占用空間,每當我們運行容器、拉取鏡像、部署應用、構建自己的鏡像時,我們的磁盤空間會被大量占用。 如果你也被這個問題所困擾,咱們就一起看一下 Docker 是如何使用磁盤空間的,以及如何回收。 docker 占用的空間可以通過下面的命令查看: TYPE 列出了docker 使用磁盤的 4 種類型: Images:所有鏡像占用的空間,包括拉取下來的鏡像,和本地構建的。 Con...

requests實現全自動PPT模板
http://www.1ppt.com/moban/ 可以免費的下載PPT模板,當然如果要人工一個個下,還是挺麻煩的,我們可以利用requests輕松下載 訪問這個主頁,我們可以看到下面的樣式 點每一個PPT模板的圖片,我們可以進入到詳細的信息頁面,翻到下面,我們可以看到對應的下載地址 點擊這個下載的按鈕,我們便可以下載對應的PPT壓縮包 那我們就開始做吧 首先,查看網頁的源代碼,我們可以看到每一...


Linux C系統編程-線程互斥鎖(四)
互斥鎖 互斥鎖也是屬于線程之間處理同步互斥方式,有上鎖/解鎖兩種狀態。 互斥鎖函數接口 1)初始化互斥鎖 pthread_mutex_init() man 3 pthread_mutex_init (找不到的情況下首先 sudo apt-get install glibc-doc sudo apt-get install manpages-posix-dev) 動態初始化 int pthread_...

統計學習方法 - 樸素貝葉斯
引入問題:一機器在良好狀態生產合格產品幾率是 90%,在故障狀態生產合格產品幾率是 30%,機器良好的概率是 75%。若一日第一件產品是合格品,那么此日機器良好的概率是多少。 貝葉斯模型 生成模型與判別模型 判別模型,即要判斷這個東西到底是哪一類,也就是要求y,那就用給定的x去預測。 生成模型,是要生成一個模型,那就是誰根據什么生成了模型,誰就是類別y,根據的內容就是x 以上述例子,判斷一個生產出...