python爬蟲實踐之爬取笑話段子
標簽: python python爬蟲 python爬蟲實踐
目錄
概述
爬取笑話段子。
準備
所需模塊
- re
- requests
- lxml
涉及知識點
- python基礎
- requests模塊基礎
- re模塊基礎
- xpath表達式基礎
運行效果
控制臺打印:

完成爬蟲
1. 分析網頁
打開笑話大全,按F12分析網頁
第一頁的URL是:http://www.lovehhy.net/Joke/Detail/QSBK/1
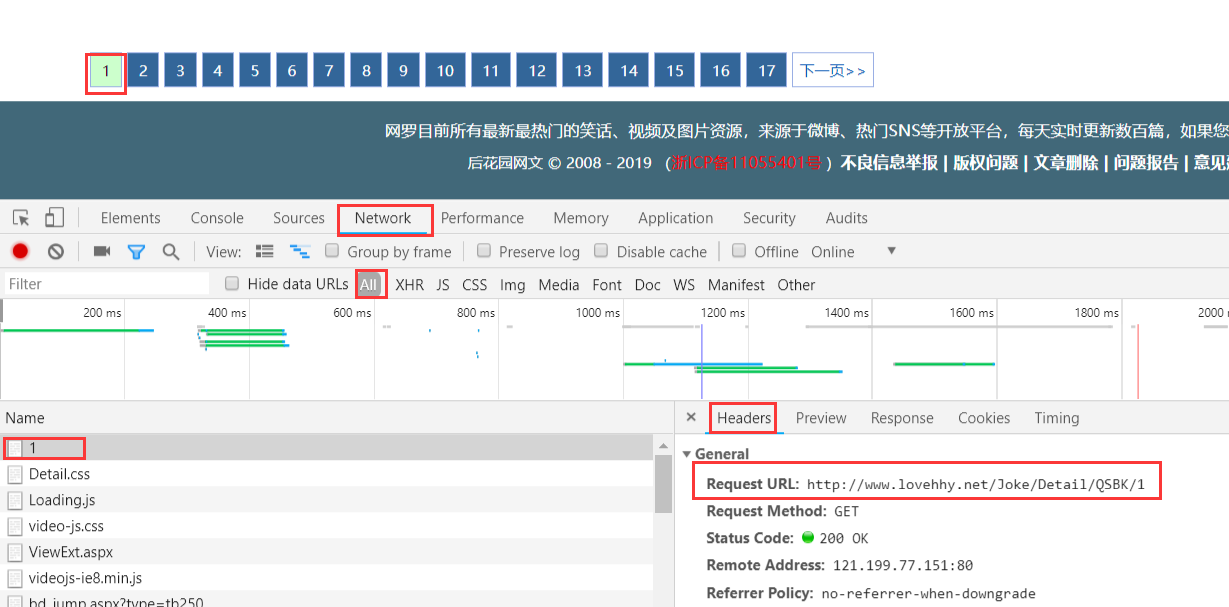
第二頁的URL是:http://www.lovehhy.net/Joke/Detail/QSBK/2
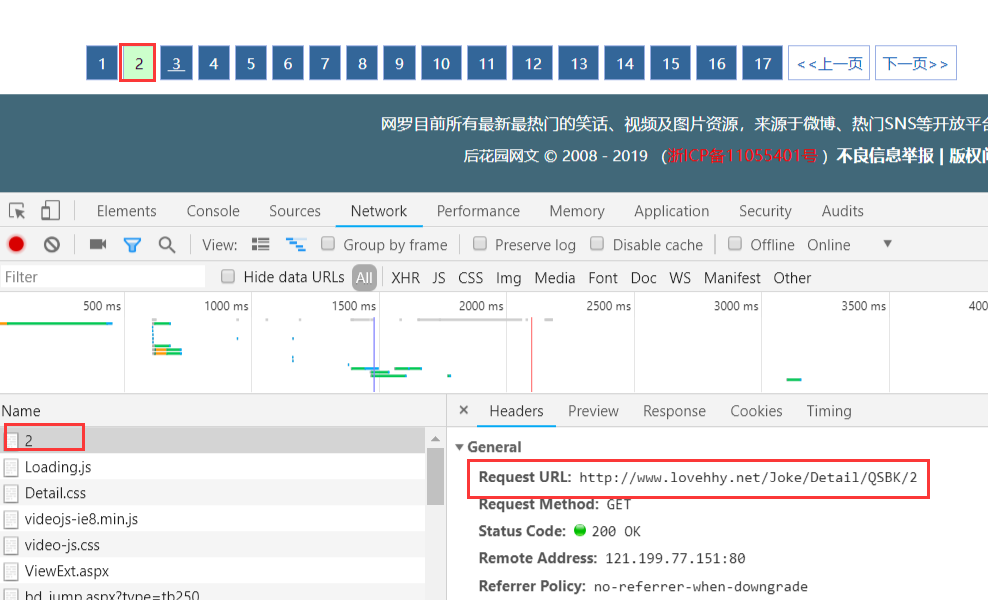
同理第三頁的URL是:http://www.lovehhy.net/Joke/Detail/QSBK/3
比較三者:
# 第1頁的URL:http://www.lovehhy.net/Joke/Detail/QSBK/1
# 第2頁的URL:http://www.lovehhy.net/Joke/Detail/QSBK/2
# 第3頁的URL:http://www.lovehhy.net/Joke/Detail/QSBK/3
# 故可以得到請求的URL公式:url="http://www.lovehhy.net/Joke/Detail/QSBK/"+page_index
# 其中page_index為頁碼因此可以根據URL獲取響應得到的HTML源碼,然后使用xpath表達式提取想要的數據。
2. 爬蟲代碼
import re
import requests
from lxml import etree
# 爬蟲實戰:爬取笑話段子
# 第1頁的URL:http://www.lovehhy.net/Joke/Detail/QSBK/1
# 第2頁的URL:http://www.lovehhy.net/Joke/Detail/QSBK/2
# 第3頁的URL:http://www.lovehhy.net/Joke/Detail/QSBK/3
# 故可以得到請求的URL公式:url="http://www.lovehhy.net/Joke/Detail/QSBK/"+page_index
# 其中page_index為頁碼
# 打印的頁數
page_num = int(input("請輸入您要獲取多少頁笑話:"))
for index in range(1, page_num + 1):
# 請求的URL
url = "http://www.lovehhy.net/Joke/Detail/QSBK/" + str(index)
# 發送請求,獲取響應到的HTML源碼
response = requests.get(url).text
# 處理換行問題,如果不處理,只會得到一行的內容
response = re.sub("<br />", "", response)
# 將HTML源碼字符串轉換成HTML對象
html = etree.HTML(response)
# 獲取所有笑話的標題
data_title_list = html.xpath("//div//h3/a")
# 獲取所有笑話的內容
data_content_list = html.xpath("//div//div[@id='endtext']")
# 打印到控制臺
if len(data_title_list) == len(data_content_list):
for i in range(0, len(data_title_list)):
print(data_title_list[i].text, "\n", data_content_list[i].text, "\n\n\n")
智能推薦
[python3]爬蟲實戰一之爬取糗事百科段子
參考http://cuiqingcai.com/990.html。不過原文是python2.7.且糗事百科又改版了。這是最新版。 本篇目標 1.抓取糗事百科熱門段子 2.過濾帶有圖片的段子 3.實現每按一次回車顯示一個段子的發布人,段子內容,點贊數。 糗事百科是不需要登錄的,所以也沒必要用到Cookie,另外糗事百科有的段子是附圖的,我們把圖抓下來圖片不便于顯示,那么我們就嘗試過濾掉有圖的段子吧。...
python爬蟲實戰之翻頁爬取糗事百科段子
近期在翻看視頻學習爬蟲,把每天學習的內容記錄下~如有一起學習的爬友就更好了。 爬蟲實戰之糗事百科段子 簡單基礎 1、正則表達式 2、信息篩選工具 urllib基礎 實戰 簡單基礎 1、正則表達式 用途:用于信息篩選提取 1、全局匹配函數使用格式: re.compole(‘正則表達式’).findall(‘源字符串’) 普通字符abc 正常匹配-abc...
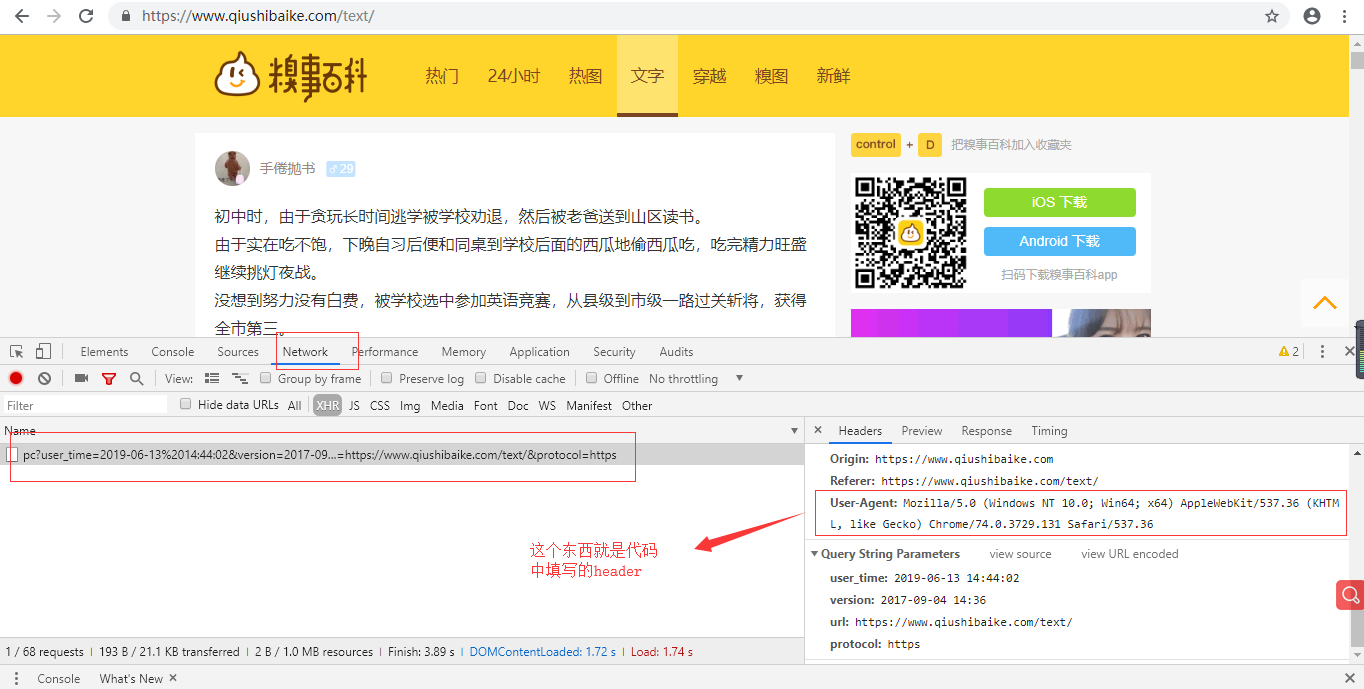
python3爬蟲之爬取糗事百科段子
查看源代碼信息找到文本內容,可以看到規律都是class為context的,所以代碼中也是按這個獲取的. 然后選第二頁的時候,可以看到路徑后面多了個2,找到這些規律后,就可以進行循環爬取內容了...
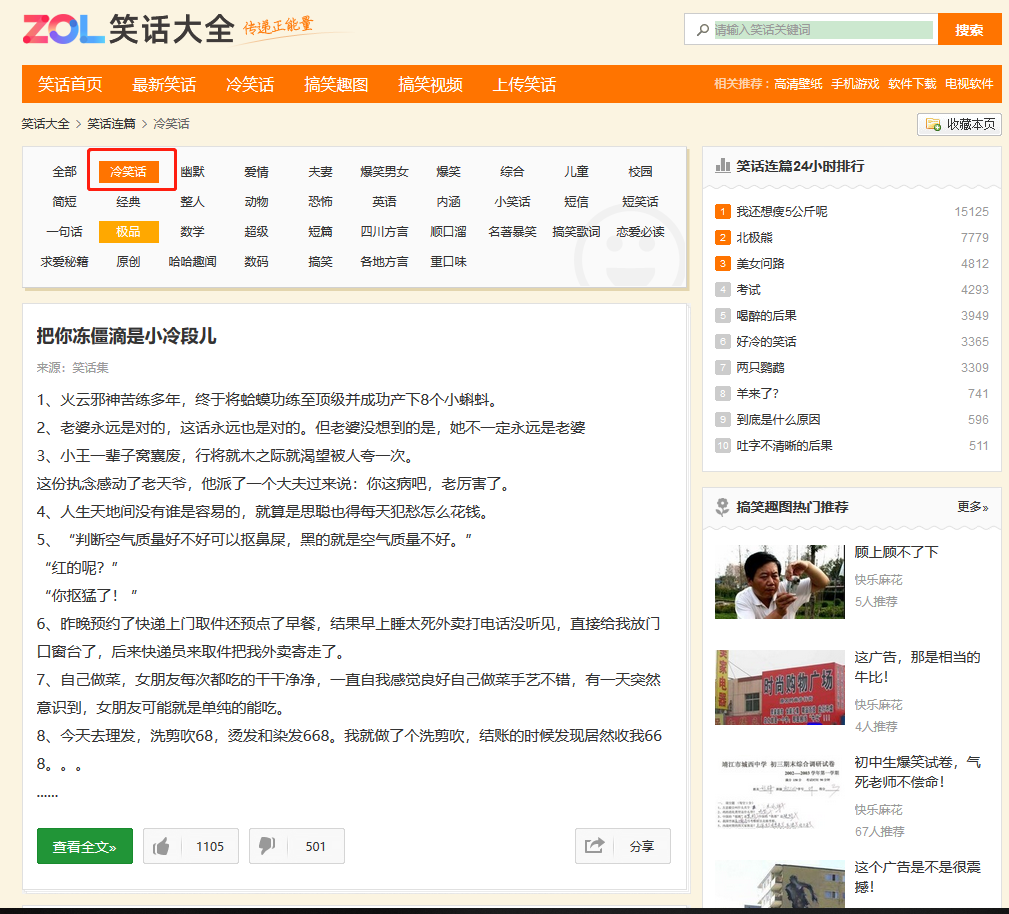
【python實現網絡爬蟲(3)】最簡單的網絡爬蟲(笑話大全網冷笑話標題爬取)
爬取笑話網 笑話大全網址,找到笑話分類,選擇冷笑話 窺探網頁細節 步驟一、觀察翻頁之后URL的變化 看到這里就可以找出里面的規律, 第一頁的話URL應該是http://xiaohua.zol.com.cn/lengxiaohua/1.html,不妨把這個網址輸入,驗證一下,結果正是對應了上面的規律 步驟二、推薦使用瀏覽器為Chrome(谷歌) 主要是插件豐富,原生功能設計對爬蟲開發者非常友好 步驟...
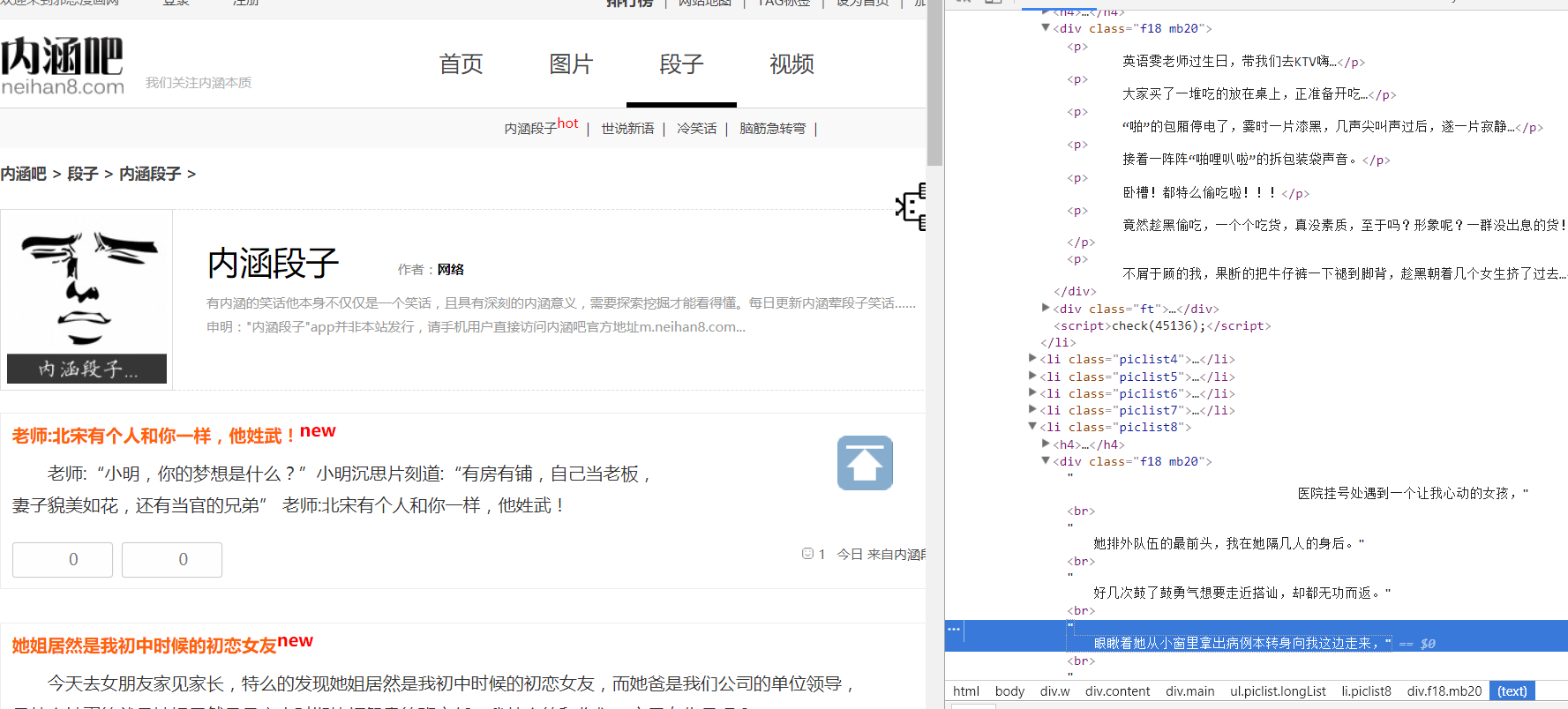
python爬蟲--正則爬取內涵段子文字
背景:虛擬機ubuntu16.04 爬取內涵段子文字,replace處理字符串 要求,根據客戶要求要爬取的page數,將段子爬取下來: 源碼如下: 打開duanzi.txt文件查看...
猜你喜歡
python爬蟲爬取糗事百科的段子
問題場景 之后的項目需要爬蟲抓取一些信息,找個例子練練手,特此記錄。 環境介紹 Windows Python2.7 IDEA15 通用抓取流程 本文思路 1、給爬蟲一個目標即網頁地址及參數 2、設置一些必要的參數 3、抓取網頁源代碼 4、提取數據 5、保存數據(本文是保存在文件里,多數是存在數據庫里) 目標 CODE 結果截圖 結果文件夾 結果文件...

python爬蟲之糗事百科文本笑話
##運行環境 python:python3.6.5 IDE:pycharm ##依賴模塊 request,re ##實現目的 實現從糗事百科網站上爬取所有的文本笑話,以txt的文本保存在程序所在文件夾內 源碼可以直接運行 ##源碼 效果如下...


freemarker + ItextRender 根據模板生成PDF文件
1. 制作模板 2. 獲取模板,并將所獲取的數據加載生成html文件 2. 生成PDF文件 其中由兩個地方需要注意,都是關于獲取文件路徑的問題,由于項目部署的時候是打包成jar包形式,所以在開發過程中時直接安照傳統的獲取方法沒有一點文件,但是當打包后部署,總是出錯。于是參考網上文章,先將文件讀出來到項目的臨時目錄下,然后再按正常方式加載該臨時文件; 還有一個問題至今沒有解決,就是關于生成PDF文件...
電腦空間不夠了?教你一個小秒招快速清理 Docker 占用的磁盤空間!
Docker 很占用空間,每當我們運行容器、拉取鏡像、部署應用、構建自己的鏡像時,我們的磁盤空間會被大量占用。 如果你也被這個問題所困擾,咱們就一起看一下 Docker 是如何使用磁盤空間的,以及如何回收。 docker 占用的空間可以通過下面的命令查看: TYPE 列出了docker 使用磁盤的 4 種類型: Images:所有鏡像占用的空間,包括拉取下來的鏡像,和本地構建的。 Con...