《數據科學入門》(一)
標簽: 數據科學
生成器和迭代器
list的一個問題是,如果使用range生成一個較大的list,而在使用的時候只使用1個或前幾個,就會造成大量的浪費。(python2)
生成器
是一種可以對其進行迭代的程序(通常是for循環),但是它的值只需要延遲產生(lazily).
- method one:
def lazy_range(n):
i = 0
while i < n:
yield i
i += 1
for i in lazy_range(10):
print(i)# dosomethingwith(i)
在python3中range本身就是lazily的。
?延遲的缺點是,你只能通過生成器迭代一次,如果需要多次迭代某個對象,你就需要每次都重新創建一個生成器,或者使用list。
- method two:
使用包含在圓括號中的for語句解析:
lazy_evens_below_20 = (i for i in range(20) if i%2== 0)
print(lazy_evens_below_20)
隨機性
import random
random.random()#生成0-1之間均勻分布的隨機數,是最常用的隨機函數
random.seed(x)#設置隨機數種子
random.random()#兩次設置相同的隨機數種子得到的結果一致
random.randrange(n)#返回從range(n)中[0:n-1]中隨機選取
random.randrange(x,y)#返回從range(x,y)中[x,y-1]中隨機選取
up_to_tem = list(range(10))#注意這里直接使用range(10)不可以一定要強制list()才行
random.shuffle(up_to_tem)#shuffle對list中的元素隨機重新排列
random.choice(up_to_tem)#注意只能隨機選取一個元素
#不重復選取
random.sample(list,num)#list:待選取list num:想要選取的元素個數
#重復選取
#多次調用choice即可
four_with_replacement = [random.choice(list(range(10))) for _ in range(4)]
#使用_占位,沒有實際意義
正則表達式
import re
#正則的package
re.match("a","cat")#cat是以a為開頭嗎?
re.search("c"."dog")#dog中是否有一個字符是c?
re.split("[ab]","carbs")#分割掉a,b剩余的字符
re,sub("[0-9]","-","R2D2")#將用虛線進行位的替換
枚舉
有時候,想在一個list上進行迭代,并且同時使用它的元素和索引
在一個已知的list上面進行迭代
for i,document in enumerate(documents):
do_something(i,document)
# i:index,document:element
for i,_ in enumerate(documents):
do_something(i,documents)
# only index
壓縮與參數拆分
如果想要把兩個或者多個list壓縮在一起,可以使用zip同時把多個list轉換為一個對應元素的tuple 的single list:
list1 = [1,2,3]
list2 = ['a','b']
list=zip(list1,list2)
print(tuple(list))
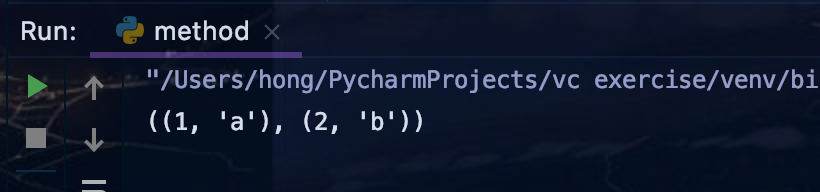
list1 = [1,2,3]
list2 = ['a','b']
list3 = [4,5,6]
list=zip(list1,list2,list3)
print(tuple(list))

if the length of these lists aren’t same, zip will end at the shortest list
(最短截止)
解壓
pairs = [(1,2),(3,4),(5,6)]
letters,numbers= zip(*pairs)
print(letters,numbers)

*(星號)執行參數拆分argument unpacking
?可以在任何函數上進行參數拆分
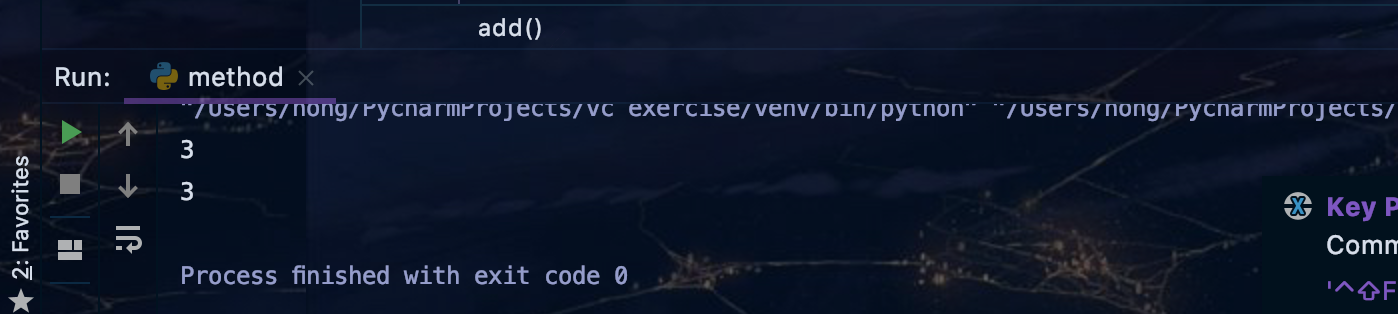
def add(a,b):
return a+b
ans = add(1,2)
print(ans)
ans = add(*[1,2])
print(ans)
args 和 kwargs
如果想要創建一個更高階的函數,把某個函數f作為input,并返回一個對任意輸入都返回f值兩倍的函數:
def doubler(f):
def g(x):
return 2*f(x)
return g
def f2(x,y):
return x+y
g = doubler(f2(1,2))
print(g(1,2))
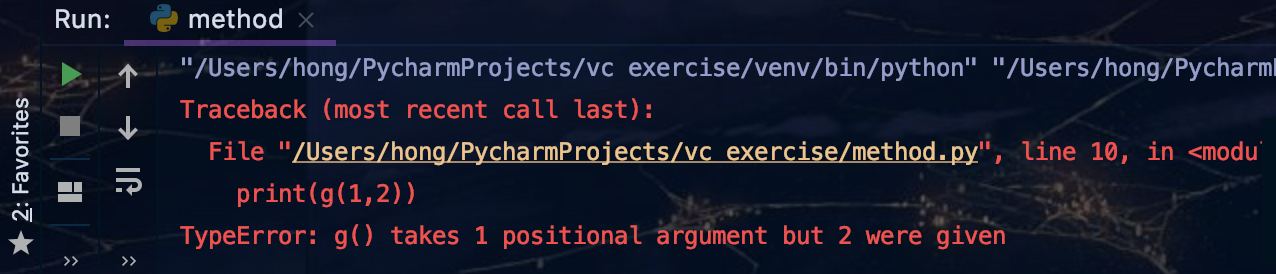
對于有多個參數的函數就不適用
需要一個可以取任意參數的函數的method,利用參數拆分可以做到:
def magic(*args,**kwargs):
print("unnamed args:",args)
print("keyword args:",kwargs)
magic(1,2,key='word',key2='word2')
輸出的未命名的args和關鍵字kwargs如下:

也就是說當定義了這樣一個function時,args是它的一個未命名參數的tuple,kwargs是它的一個已命名參數的dict
反過來也適用,可以使用一個list/tuple和dict來給函數提供參數
def other_way_magic(x,y,z):
return x+y+z
x_y_list = [1,2]
z_dict = {"z":3}
print(other_way_magic(*x_y_list,**z_dict))
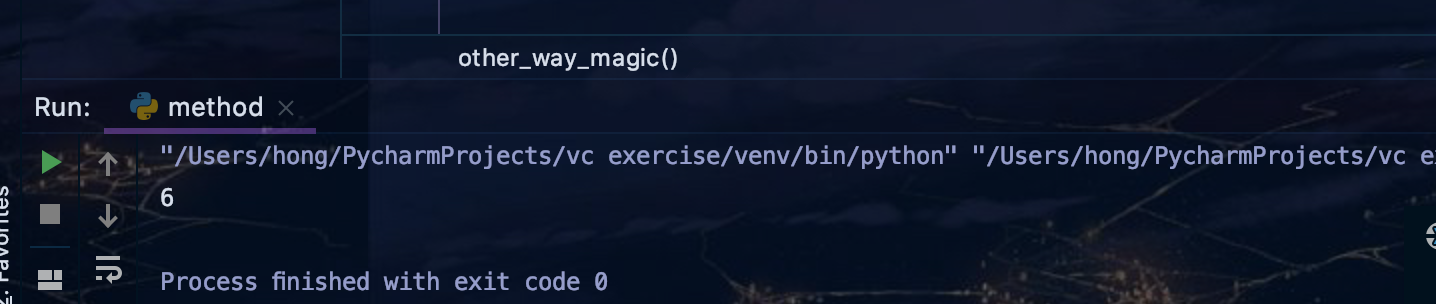
用它可以將任意參數作為輸入的高階函數
def doubler_correct(f):
def g(*args,**kwargs):
return 2*f(*args,**kwargs)
return g
def f2(x,y):
return x+y
g = doubler_correct(f2)
print(g(1,2))

因為傳入函數的參數具有不確定性,所以像最開始那樣直接固定參數個數不行,所以才用這種參數隨便的method。
智能推薦
數據科學工具——Jupyter notebook入門
Jupyter notebook入門 安裝環境 啟動JUPYTER NOTEBOOK JUPYTER NOTEBOOK入門 JUPYTER的魔術命令 批量安裝python第三方庫 今天來介紹一下數據科學中最常用的一個工具:Jupyter notebook 安裝環境 首先我們需要python環境的搭建,這里對應的是兩個版本3.7和2.7,建議大家都安裝3.7版本 當然這里推薦大家安裝Anaconda...

數據科學入門三個月的一些隨想
原文首發于簡書于[2018.05.30] 這個學期旁聽了統數學院的三門課:馬景義老師的[數據挖掘],劉苗老師的[時間序列分析],李豐老師的[統計計算]。 我以前說,沒有數學的日子里,我的生活中只剩下了鄙視鏈和毒雞湯,無法進行深層次的思考。現在上了三個月的課,仍是十分贊同這句話。三個月來,在數據科學這個行業里摸爬滾打,算是有不少收獲,在這里寫一些隨想吧。全文的結構是: 數據挖掘 關于這門課程的收獲 ...
機器學習——數據科學包(一)
文章目錄 機器學習——基礎算法(一) 一、numpy &pandas有什么用 二、numpy&pandas的安裝 三、numpy屬性 四、numpy的創建array 五、numpy的基礎運算 (一)減法(加法類似) (二)平方 (三)...

計算與推斷思維 一、數據科學
一、數據科學 原文:Data Science 譯者:飛龍 協議:CC BY-NC-SA 4.0 自豪地采用谷歌翻譯 什么是數據科學 數據科學是通過探索,預測和推斷,從大量不同的數據集中得出有用的結論。探索涉及識別信息中的規律。預測涉及使用我們所知道的信息,對我們希望知道的值作出知情的猜測。推斷涉及量化我們的確定程度:我們發現的這些規律是否也出現在新的觀察中?我們的預測有多準確?我們用于探索的主要工...

猜你喜歡

freemarker + ItextRender 根據模板生成PDF文件
1. 制作模板 2. 獲取模板,并將所獲取的數據加載生成html文件 2. 生成PDF文件 其中由兩個地方需要注意,都是關于獲取文件路徑的問題,由于項目部署的時候是打包成jar包形式,所以在開發過程中時直接安照傳統的獲取方法沒有一點文件,但是當打包后部署,總是出錯。于是參考網上文章,先將文件讀出來到項目的臨時目錄下,然后再按正常方式加載該臨時文件; 還有一個問題至今沒有解決,就是關于生成PDF文件...
電腦空間不夠了?教你一個小秒招快速清理 Docker 占用的磁盤空間!
Docker 很占用空間,每當我們運行容器、拉取鏡像、部署應用、構建自己的鏡像時,我們的磁盤空間會被大量占用。 如果你也被這個問題所困擾,咱們就一起看一下 Docker 是如何使用磁盤空間的,以及如何回收。 docker 占用的空間可以通過下面的命令查看: TYPE 列出了docker 使用磁盤的 4 種類型: Images:所有鏡像占用的空間,包括拉取下來的鏡像,和本地構建的。 Con...

requests實現全自動PPT模板
http://www.1ppt.com/moban/ 可以免費的下載PPT模板,當然如果要人工一個個下,還是挺麻煩的,我們可以利用requests輕松下載 訪問這個主頁,我們可以看到下面的樣式 點每一個PPT模板的圖片,我們可以進入到詳細的信息頁面,翻到下面,我們可以看到對應的下載地址 點擊這個下載的按鈕,我們便可以下載對應的PPT壓縮包 那我們就開始做吧 首先,查看網頁的源代碼,我們可以看到每一...


Linux C系統編程-線程互斥鎖(四)
互斥鎖 互斥鎖也是屬于線程之間處理同步互斥方式,有上鎖/解鎖兩種狀態。 互斥鎖函數接口 1)初始化互斥鎖 pthread_mutex_init() man 3 pthread_mutex_init (找不到的情況下首先 sudo apt-get install glibc-doc sudo apt-get install manpages-posix-dev) 動態初始化 int pthread_...