Scrapy框架入門
1. 創建爬蟲
cmd 或 powershell 或 bash 創建爬蟲命令:
cmd打開方式:win + R ,輸入cmd,回車。
powershell:win + S,輸入powershell,回車。
bash:Linux下,ctrl + alt + T。
scrapy startproject 爬蟲名稱
2. 核心類Spider
以爬取Scrapy百度百科為例。
首先在setting中關閉網頁爬蟲檢查:
ROBOTSTXT_OBEY = False
然后在spiders目錄下創建Spider01文件:
# Spider01.py
import scrapy
# Spider01類繼承自scrapy.Spider類
class Spider01(scrapy.Spider):
# 爬蟲名稱
name = 'spider01'
# 要爬的網址,是一個列表,可以寫多個
start_urls = ['https://baike.baidu.com/item/scrapy/7914913?fr=aladdin']
def parse(self, response):
# 輸出網頁的html
print(response.text)
再創建文件啟動程序RUN.py
# RUN.py
import scrapy.cmdline as cmdline
def run_spider(spider_name: str):
cmdline.execute(("scrapy crawl " + spider_name).split())
if __name__ == '__main__':
run_spider('spider01')
文件目錄如圖所示

此時運行RUN.py,若在控制臺能正確輸出網頁的html,則說明到此為止是成功的。
2.1 抽取數據
使用xpath或者css選擇器,選擇器的語法在此不贅述。此處只介紹scrapy的API。
import scrapy
class Spider01(scrapy.Spider):
name = 'spider01'
start_urls = ['https://baike.baidu.com/item/scrapy/7914913?fr=aladdin']
def parse(self, response):
# 抽取html中全部的子標題,getall()方法將子標題以列表的形式返回
print(response.xpath('//h2[@class="title-text"]/text()').getall())
# 如果使用get()取代getall(),則只返回html中第一個與之匹配的內容
print(response.xpath('//h2[@class="title-text"]/text()').getall())
3. items的使用
items用于格式化存儲爬取的數據
首先在item中構造類ScrapydemoItem。
# itmes.py
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class ScrapydemoItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
content = scrapy.Field()
其次,在spider的parse中調用它,在調用之前,需要導入該類。
import scrapy
from ScrapyDemo.items import ScrapydemoItem
class Spider01(scrapy.Spider):
name = 'spider01'
start_urls = ['https://baike.baidu.com/item/scrapy/7914913?fr=aladdin']
def parse(self, response):
item = ScrapydemoItem()
item['title'] = response.xpath('//h2[@class="title-text"]/text()').get()
item['content'] = response.xpath('//h2[@class="title-text"]/../following-sibling::*[1]/text()').get()
print(item['title'])
print(item['content'])
4. middlewares中間件的開發
middleware位于request與response之間,用于更換代理IP、更換Cookies、更換User-Agent、自動重試。
4.1 更換代理IP
from scrapy import signals
import random
from scrapy.utils.project import get_project_settings
class ScrapydemoDownloaderMiddleware(object):
# 其他方法保持默認即可
def process_request(self, request, spider):
# 發送每個請求時,都會經過該方法
# 因此,該方法適合放置代理IP
proxy = random.choice(get_project_settings()['PROXIES'])
request.meta['proxy'] = proxy
# 使用了settings.py配置文件,因此需要導入它 from scrapy.utils.project import get_project_settings
# 在settings.py中添加代理IP
# PROXIES = ['https://114.217.243.25:8118',
# 'https://125.37.175.233:8118',
# 'http://1.85.116.218:8118']
# 需要看清楚是HTTP型還是HTTPS型的代理IP
return None
寫完后,需要去setting.py中找到下面一段代碼,并取消注釋,即可成功**。所有中間件都需要**,不再贅述。
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# 'ScrapyDemo.middlewares.ScrapydemoDownloaderMiddleware': 543,
#}
4.2 更換User-Agent
from scrapy import signals
import random
from scrapy.utils.project import get_project_settings
class ScrapydemoDownloaderMiddleware(object):
def process_request(self, request, spider):
ua = random.choice(get_project_settings()['USER_AGENT_LIST'])
request.headers['User-Agent'] = ua
return None
在settings.py中添加請求頭
4.3 更換cookie
4.4 自動重試
# setting.py
RETRY_ENABLED = True
RETRY_TIMES = 10
RETRY_HTTP_CODES = [
412
]
5. Pipeline
管道組件,由三個核心方法構成:open_spider、process_item、close_spider。
-
當爬蟲啟動時,會觸發open_spider組件,此時通常是獲取數據庫連接,或者打開文件。
-
當爬蟲每yield一個item時,都會經過process_item函數,在這個函數中,我們通常會檢查新來的item是否與已有的item重復了。或者將item寫入數據庫。
-
當爬蟲關閉時,會經過close_spider函數,此時通常是關閉數據庫或者文件。
Pipeline組件可以有多個,相當于管道的串聯,每個Pipeline都需要在settings.py中開放。
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'scrapyDemo.pipelines.ScrapydemoPipeline': 300, # 300代表優先級,數字越小越先執行
}
下面是一個刪除重復item的Pipeline
class ScrapydemoPipeline(object):
# 爬蟲啟動時執行
def open_spider(self, spider):
self.contentSet = set()
print("hello")
# 每yield一個item時都會經過這個函數
def process_item(self, item, spider):
if item["content"] not in self.contentSet:
self.contentSet.add(item["content"])
# 在這里可以將item寫入文件或數據庫
# Pipeline組件可以有多個,在settings.py文件中設置優先級
return item
else:
# item重復了
pass
# 爬蟲結束時執行
def close_spider(self, spider):
print("bye")
智能推薦

Python爬蟲day7—Scrapy框架入門
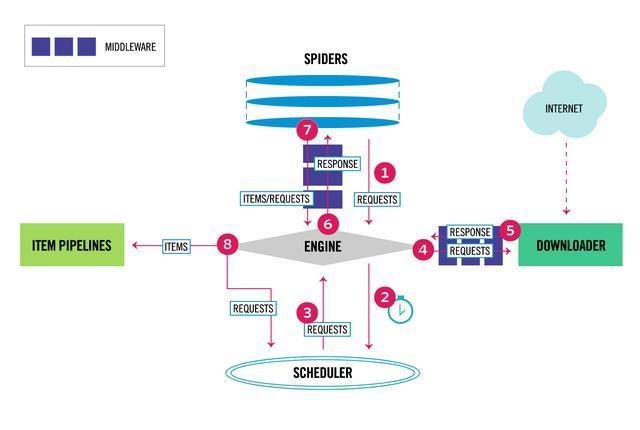
Scrapy爬蟲框架入門 概述 Scrapy是Python開發的一個非常流行的網絡爬蟲框架,可以用來抓取Web站點并從頁面中提取結構化的數據,被廣泛的用于數據挖掘、數據監測和自動化測試等領域。下圖展示了Scrapy的基本架構,其中包含了主要組件和系統的數據處理流程(圖中帶數字的紅色箭頭)。 組件 Scrapy引擎(Engine):Scrapy引擎是用來控制整個系統的數據處理流程。 調度器(Sche...
Python爬蟲學習教程:Scrapy爬蟲框架入門
Python爬蟲學習教程:Scrapy概述 Scrapy是Python開發的一個非常流行的網絡爬蟲框架,可以用來抓取Web站點并從頁面中提取結構化的數據,被廣泛的用于數據挖掘、數據監測和自動化測試等領域。下圖展示了Scrapy的基本架構,其中包含了主要組件和系統的數據處理流程(圖中帶數字的紅色箭頭)。 組件 Scrapy引擎(Engine):Scrapy引擎是用來控制整個系統的數據處理流程。 調度...


freemarker + ItextRender 根據模板生成PDF文件
1. 制作模板 2. 獲取模板,并將所獲取的數據加載生成html文件 2. 生成PDF文件 其中由兩個地方需要注意,都是關于獲取文件路徑的問題,由于項目部署的時候是打包成jar包形式,所以在開發過程中時直接安照傳統的獲取方法沒有一點文件,但是當打包后部署,總是出錯。于是參考網上文章,先將文件讀出來到項目的臨時目錄下,然后再按正常方式加載該臨時文件; 還有一個問題至今沒有解決,就是關于生成PDF文件...
電腦空間不夠了?教你一個小秒招快速清理 Docker 占用的磁盤空間!
Docker 很占用空間,每當我們運行容器、拉取鏡像、部署應用、構建自己的鏡像時,我們的磁盤空間會被大量占用。 如果你也被這個問題所困擾,咱們就一起看一下 Docker 是如何使用磁盤空間的,以及如何回收。 docker 占用的空間可以通過下面的命令查看: TYPE 列出了docker 使用磁盤的 4 種類型: Images:所有鏡像占用的空間,包括拉取下來的鏡像,和本地構建的。 Con...
猜你喜歡

requests實現全自動PPT模板
http://www.1ppt.com/moban/ 可以免費的下載PPT模板,當然如果要人工一個個下,還是挺麻煩的,我們可以利用requests輕松下載 訪問這個主頁,我們可以看到下面的樣式 點每一個PPT模板的圖片,我們可以進入到詳細的信息頁面,翻到下面,我們可以看到對應的下載地址 點擊這個下載的按鈕,我們便可以下載對應的PPT壓縮包 那我們就開始做吧 首先,查看網頁的源代碼,我們可以看到每一...


Linux C系統編程-線程互斥鎖(四)
互斥鎖 互斥鎖也是屬于線程之間處理同步互斥方式,有上鎖/解鎖兩種狀態。 互斥鎖函數接口 1)初始化互斥鎖 pthread_mutex_init() man 3 pthread_mutex_init (找不到的情況下首先 sudo apt-get install glibc-doc sudo apt-get install manpages-posix-dev) 動態初始化 int pthread_...

統計學習方法 - 樸素貝葉斯
引入問題:一機器在良好狀態生產合格產品幾率是 90%,在故障狀態生產合格產品幾率是 30%,機器良好的概率是 75%。若一日第一件產品是合格品,那么此日機器良好的概率是多少。 貝葉斯模型 生成模型與判別模型 判別模型,即要判斷這個東西到底是哪一類,也就是要求y,那就用給定的x去預測。 生成模型,是要生成一個模型,那就是誰根據什么生成了模型,誰就是類別y,根據的內容就是x 以上述例子,判斷一個生產出...

styled-components —— React 中的 CSS 最佳實踐
https://zhuanlan.zhihu.com/p/29344146 Styled-components 是目前 React 樣式方案中最受關注的一種,它既具備了 css-in-js 的模塊化與參數化優點,又完全使用CSS的書寫習慣,不會引起額外的學習成本。本文是 styled-components 作者之一 Max Stoiber 所寫,首先總結了前端組件化樣式中的最佳實踐原則,然后在此基...