通過DOM方式解析xml
簡述:XML 指可擴展標記語言(eXtensible Markup Language)。
XML 被設計用來傳輸和存儲數據。
XML 很重要,也很容易學習。
什么是xml?
- XML 指可擴展標記語言(EXtensible Markup Language)。
- XML 是一種很像HTML的標記語言。
- XML 的設計宗旨是傳輸數據,而不是顯示數據。
- XML 標簽沒有被預定義。您需要自行定義標簽。
- XML 被設計為具有自我描述性。
- XML 是 W3C 的推薦標準。
XML和HTML之間的差異
XML 不是 HTML 的替代。
XML 和 HTML 為不同的目的而設計:
- XML 被設計用來傳輸和存儲數據,其焦點是數據的內容。
- HTML 被設計用來顯示數據,其焦點是數據的外觀。
HTML 旨在顯示信息,而 XML 旨在傳輸信息。
通過XML可以自己發明標簽
例:
<note>
<to>Tove</to>
<from>Jani</from>
<heading>Reminder</heading>
<body>Don't forget me this weekend!</body>
</note>上面實例中的標簽沒有在任何 XML 標準中定義過(比如 <to> 和 <from>)。這些標簽是由 XML 文檔的創作者發明的。
這是因為 XML 語言沒有預定義的標簽。
HTML 中使用的標簽都是預定義的。HTML 文檔只能使用在 HTML 標準中定義過的標簽(如 <p>、<h1> 等等)。
XML 允許創作者定義自己的標簽和自己的文檔結構。
DOM解析
DOM的全稱是Document Object Model,也即文檔對象模型。在應用程序中,基于DOM的XML分析器將一個XML文檔轉換成一個對象模型的集合(通常稱DOM樹),應用程序正是通過對這個對象模型的操作,來實現對XML文檔數據的操作。通過DOM接口,應用程序可以在任何時候訪問XML文檔中的任何一部分數據,因此,這種利用DOM接口的機制也被稱作隨機訪問機制。
DOM接口提供了一種通過分層對象模型來訪問XML文檔信息的方式,這些分層對象模型依據XML的文檔結構形成了一棵節點樹。無論XML文檔中所描述的是什么類型的信息,即便是制表數據、項目列表或一個文檔,利用DOM所生成的模型都是節點樹的形式。也就是說,DOM強制使用樹模型來訪問XML文檔中的信息。由于XML本質上就是一種分層結構,所以這種描述方法是相當有效的。
DOM樹所提供的隨機訪問方式給應用程序的開發帶來了很大的靈活性,它可以任意地控制整個XML文檔中的內容。然而,由于DOM分析器把整個XML文檔轉化成DOM樹放在了內存中,因此,當文檔比較大或者結構比較復雜時,對內存的需求就比較高。而且,對于結構復雜的樹的遍歷也是一項耗時的操作。所以,DOM分析器對機器性能的要求比較高,實現效率不十分理想。不過,由于DOM分析器所采用的樹結構的思想與XML文檔的結構相吻合,同時鑒于隨機訪問所帶來的方便,因此,DOM分析器還是有很廣泛的使用價值的。
優點:
1、形成了樹結構,有助于更好的理解、掌握,且代碼容易編寫。
2、解析過程中,樹結構保存在內存中,方便修改。
缺點:
1、由于文件是一次性讀取,所以對內存的耗費比較大。
2、如果XML文件比較大,容易影響解析性能且可能會造成內存溢出。
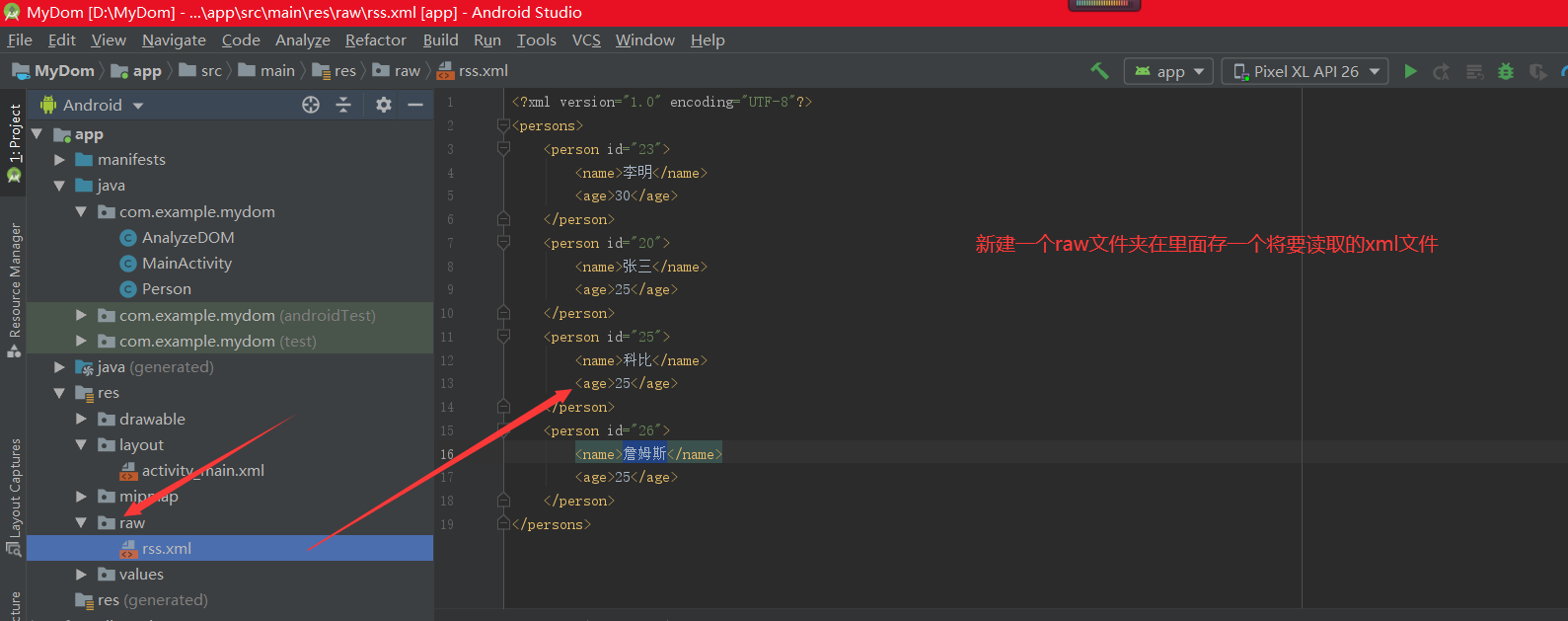
1.首先使用文本文檔新建一個xml文件(注意編碼格式)
xml代碼如下:
<?xml version='1.0' encoding='UTF-8' ?>
<root>
<hang>
<產品唯一ID>aab產品唯一ID</產品唯一ID>
<通用名>aa通用名</通用名>
<商品名>aa商品名</商品名>
<劑型>aa劑型</劑型>
<批準文號>aa批準文號</批準文號>
<規格>aa規格</規格>
<包裝說明>aa包裝說明</包裝說明>
<包裝單位>aa包裝單位</包裝單位>
<生產企業>aa生產企業</生產企業>
<大包裝轉換比>aa大包裝轉換比</大包裝轉換比>
<中包裝轉換比>aa中包裝轉換比</中包裝轉換比>
<備注>aa備注</備注>
<庫存>aa庫存</庫存>
<供應價>aa供應價</供應價>
<是否上架>aa是否上架</是否上架>
</hang>
<hang>
<產品唯一ID>a121</產品唯一ID>
<通用名>b12</通用名>
<商品名>c231</商品名>
<劑型>dewrwer</劑型>
<批準文號>e324324</批準文號>
<規格>f45645</規格>
<包裝說明>g4543</包裝說明>
<包裝單位>hq324e2</包裝單位>
<生產企業>i76</生產企業>
<大包裝轉換比>j453</大包裝轉換比>
<中包裝轉換比>k4r43r</中包裝轉換比>
<備注>le4tr4</備注>
<庫存>mq3e2</庫存>
<供應價>nefrw</供應價>
<是否上架>o56</是否上架>
</hang>
</root>
2.通過java編寫DOM解析程序
java源代碼:
import java.io.IOException;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import org.w3c.dom.Document;
import org.w3c.dom.NamedNodeMap;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import org.xml.sax.SAXException;
public class DOMTest {
public static void main(String[] args) {
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();//創建一個DocumentBuilderFactory的對象
//創建一個DocumentBuilder的對象
try {
DocumentBuilder db = dbf.newDocumentBuilder();//創建DocumentBuilder對象
Document document = db.parse("F://123.xml");//通過DocumentBuilder對象的parser方法加載123.xml文件到當前項目下
NodeList bookList = document.getElementsByTagName("hang");//獲取所有book節點的集合
System.out.println("一共有" + bookList.getLength() + "個產品"); //通過nodelist的getLength()方法可以獲取bookList的長度
for (int i = 0; i < bookList.getLength(); i++) {//遍歷每一個book節點
System.out.println("=================下面開始遍歷第" + (i + 1) + "個產品的內容=================");
Node book = bookList.item(i); //通過 item(i)方法 獲取一個book節點,nodelist的索引值從0開始
NamedNodeMap attrs = book.getAttributes();//獲取book節點的所有屬性集合
System.out.println("第 " + (i + 1) + "個產品共有" + attrs.getLength() + "個屬性");
for (int j = 0; j < attrs.getLength(); j++) {//遍歷hang的屬性
Node attr = attrs.item(j);//通過item(index)方法獲取hang節點的某一個屬性
System.out.print("屬性名:" + attr.getNodeName());//獲取屬性名
System.out.println("--屬性值" + attr.getNodeValue());//獲取屬性值
}
NodeList childNodes = book.getChildNodes(); //解析hang節點的子節點
System.out.println("第" + (i+1) + "個產品共有" +
childNodes.getLength() + "個子節點");//遍歷childNodes獲取每個節點的節點名和節點值
for (int k = 0; k < childNodes.getLength(); k++) {
if (childNodes.item(k).getNodeType() == Node.ELEMENT_NODE) {//區分出text類型的node以及element類型的node
System.out.print("第" + (k + 1) + "個節點的節點名:" //獲取了element類型節點的節點名
+ childNodes.item(k).getNodeName());
System.out.println("--節點值是:" + childNodes.item(k).getFirstChild().getNodeValue()); //獲取了element類型節點的節點值
}
}
System.out.println("======================結束遍歷第" + (i + 1) + "個產品的內容=================");
}
} catch (ParserConfigurationException e) {
e.printStackTrace();
} catch (SAXException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}運行結果如下:
一共有2個產品
=================下面開始遍歷第1個產品的內容=================
第 1個產品共有0個屬性
第1個產品共有31個子節點
第2個節點的節點名:產品唯一ID--節點值是:aab產品唯一ID
第4個節點的節點名:通用名--節點值是:aa通用名
第6個節點的節點名:商品名--節點值是:aa商品名
第8個節點的節點名:劑型--節點值是:aa劑型
第10個節點的節點名:批準文號--節點值是:aa批準文號
第12個節點的節點名:規格--節點值是:aa規格
第14個節點的節點名:包裝說明--節點值是:aa包裝說明
第16個節點的節點名:包裝單位--節點值是:aa包裝單位
第18個節點的節點名:生產企業--節點值是:aa生產企業
第20個節點的節點名:大包裝轉換比--節點值是:aa大包裝轉換比
第22個節點的節點名:中包裝轉換比--節點值是:aa中包裝轉換比
第24個節點的節點名:備注--節點值是:aa備注
第26個節點的節點名:庫存--節點值是:aa庫存
第28個節點的節點名:供應價--節點值是:aa供應價
第30個節點的節點名:是否上架--節點值是:aa是否上架
======================結束遍歷第1個產品的內容=================
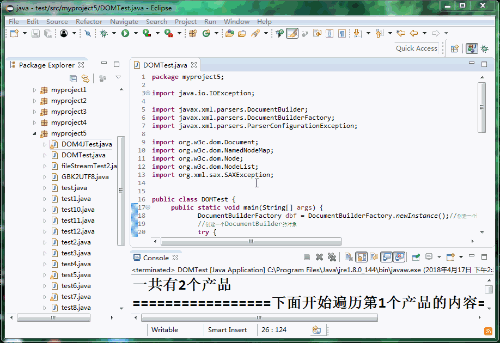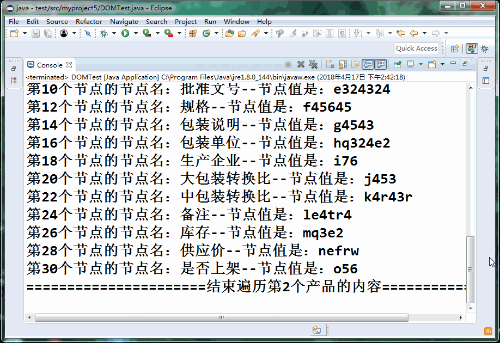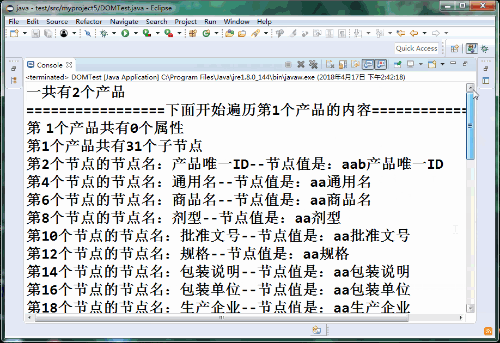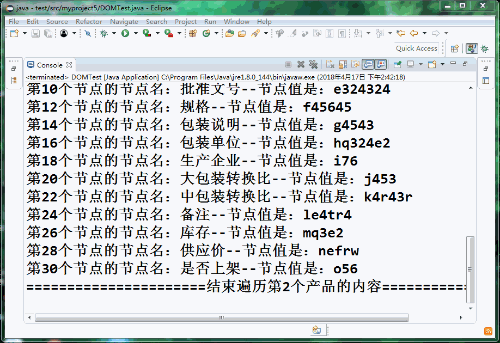
=================下面開始遍歷第2個產品的內容=================
第 2個產品共有0個屬性
第2個產品共有31個子節點
第2個節點的節點名:產品唯一ID--節點值是:a121
第4個節點的節點名:通用名--節點值是:b12
第6個節點的節點名:商品名--節點值是:c231
第8個節點的節點名:劑型--節點值是:dewrwer
第10個節點的節點名:批準文號--節點值是:e324324
第12個節點的節點名:規格--節點值是:f45645
第14個節點的節點名:包裝說明--節點值是:g4543
第16個節點的節點名:包裝單位--節點值是:hq324e2
第18個節點的節點名:生產企業--節點值是:i76
第20個節點的節點名:大包裝轉換比--節點值是:j453
第22個節點的節點名:中包裝轉換比--節點值是:k4r43r
第24個節點的節點名:備注--節點值是:le4tr4
第26個節點的節點名:庫存--節點值是:mq3e2
第28個節點的節點名:供應價--節點值是:nefrw
第30個節點的節點名:是否上架--節點值是:o56
======================結束遍歷第2個產品的內容=================智能推薦

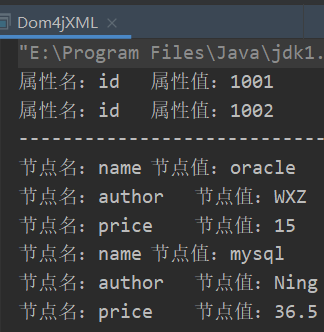
DOM4J方式解析XML文件
DOM4J是一個Java的XML API,是JDOM的升級品,用來讀寫XML文件的。 DOM4J解析XML的步驟 創建SAXReader對象 調用read()方法 獲取根元素 通過迭代器遍歷直接節點 XML文件 解析過程 運行結果...

android DOM解析XML
XML文檔的概述 : 可擴展標記語言(eXtensibleMarkupLanguage,簡稱:XML: 前身是SGML(TheStandardGeneralizedMarkupLanguage),GML的重要概念:文件中能夠明確的將標示與內容分開/所有 文件的標示使用方法均一致 用途: XML設計用來傳送及攜帶數據信息,不用來表現或展示數據,HTML語言則用來表現數據,所以XML用途的焦點 是它說...

XML解析-DOM
關于XML解析 以前有說過 不過那是SAX方式的 今天說一下DOM方法 [序言] 1. 今天解析的目標是:香港天氣rss 地址為: 現在的目標就是:定制化該目標的解析辦法 我們還是查看一下該地址的源文件 具體方法: 現在貼其源文件://注:為了閱讀方便 我加了一些“回車換行”源文件是沒有這些的 ...
猜你喜歡
Dom解析xml文件
DOM(文件對象模型)解析:解析器讀入整個文檔,然后構建一個駐留內存的樹結構,然后代碼就可以根據DOM接口來操作這個樹結構了。 優點:整個文檔讀入內存,方便操作:支持修改、刪除和重現排列等多種功能。 缺點:將整個文檔讀入內存中,保留了過多的不需要的節點,浪費內存和空間。 使用場合:一旦讀入文檔,還需要多次對文檔進行操作,并且在硬件資源充足的情況下(內存,CPU)。 DOM是基于樹形結構的節...


freemarker + ItextRender 根據模板生成PDF文件
1. 制作模板 2. 獲取模板,并將所獲取的數據加載生成html文件 2. 生成PDF文件 其中由兩個地方需要注意,都是關于獲取文件路徑的問題,由于項目部署的時候是打包成jar包形式,所以在開發過程中時直接安照傳統的獲取方法沒有一點文件,但是當打包后部署,總是出錯。于是參考網上文章,先將文件讀出來到項目的臨時目錄下,然后再按正常方式加載該臨時文件; 還有一個問題至今沒有解決,就是關于生成PDF文件...
電腦空間不夠了?教你一個小秒招快速清理 Docker 占用的磁盤空間!
Docker 很占用空間,每當我們運行容器、拉取鏡像、部署應用、構建自己的鏡像時,我們的磁盤空間會被大量占用。 如果你也被這個問題所困擾,咱們就一起看一下 Docker 是如何使用磁盤空間的,以及如何回收。 docker 占用的空間可以通過下面的命令查看: TYPE 列出了docker 使用磁盤的 4 種類型: Images:所有鏡像占用的空間,包括拉取下來的鏡像,和本地構建的。 Con...

requests實現全自動PPT模板
http://www.1ppt.com/moban/ 可以免費的下載PPT模板,當然如果要人工一個個下,還是挺麻煩的,我們可以利用requests輕松下載 訪問這個主頁,我們可以看到下面的樣式 點每一個PPT模板的圖片,我們可以進入到詳細的信息頁面,翻到下面,我們可以看到對應的下載地址 點擊這個下載的按鈕,我們便可以下載對應的PPT壓縮包 那我們就開始做吧 首先,查看網頁的源代碼,我們可以看到每一...