Python數據科學入門(Pandas玩轉數據)
慕課網數據科學入門課程學習筆記
一、Series和DataFrame的簡單數學運算
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
1.Series 相加
s1 = Series([1,2,3],index=['A','B','C'])
s1
A 1
B 2
C 3
dtype: int64
s2 = Series([4,5,6,7],index=['B','C','D','E'])
s2
B 4
C 5
D 6
E 7
dtype: int64
s1 + s2
A NaN
B 6.0
C 8.0
D NaN
E NaN
dtype: float64
2.Dataframe運算
df1 = DataFrame(np.arange(4).reshape(2,2),index=['A','B'],columns=['AA','BB'])
df1
df2 = DataFrame(np.arange(9).reshape(3,3),index=['A','B','C'],columns=['AA','BB','CC'])
df2
|
AA |
BB |
CC |
| A |
0 |
1 |
2 |
| B |
3 |
4 |
5 |
| C |
6 |
7 |
8 |
df1 + df2
|
AA |
BB |
CC |
| A |
0.0 |
2.0 |
NaN |
| B |
5.0 |
7.0 |
NaN |
| C |
NaN |
NaN |
NaN |
df3 = DataFrame([[1,2,3],[4,5,np.nan],[7,8,9]],
index=['A','B','C'],columns=['c1','c2','c3'])
df3
|
c1 |
c2 |
c3 |
| A |
1 |
2 |
3.0 |
| B |
4 |
5 |
NaN |
| C |
7 |
8 |
9.0 |
df3.sum()
c1 12.0
c2 15.0
c3 12.0
dtype: float64
df3.min()
c1 1.0
c2 2.0
c3 3.0
dtype: float64
df3.describe()
|
c1 |
c2 |
c3 |
| count |
3.0 |
3.0 |
2.000000 |
| mean |
4.0 |
5.0 |
6.000000 |
| std |
3.0 |
3.0 |
4.242641 |
| min |
1.0 |
2.0 |
3.000000 |
| 25% |
2.5 |
3.5 |
4.500000 |
| 50% |
4.0 |
5.0 |
6.000000 |
| 75% |
5.5 |
6.5 |
7.500000 |
| max |
7.0 |
8.0 |
9.000000 |
二、Series和DataFrame的排序
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
1.Series排序
s1 = Series(np.random.randn(10))
s1
0 0.773184
1 -0.403266
2 0.980296
3 -0.631971
4 0.636405
5 0.732921
6 0.756932
7 -0.597943
8 -1.152224
9 0.771753
dtype: float64
s1.sort_values()
8 -1.152224
3 -0.631971
7 -0.597943
1 -0.403266
4 0.636405
5 0.732921
6 0.756932
9 0.771753
0 0.773184
2 0.980296
dtype: float64
s1.sort_index(ascending=False)
9 0.771753
8 -1.152224
7 -0.597943
6 0.756932
5 0.732921
4 0.636405
3 -0.631971
2 0.980296
1 -0.403266
0 0.773184
dtype: float64
2.DataFrame排序
df1 = DataFrame(np.random.randn(20).reshape(4,5),columns=['a','b','c','d','e'])
df1
|
a |
b |
c |
d |
e |
| 0 |
0.173908 |
-0.978290 |
-0.791529 |
-1.769024 |
-1.971549 |
| 1 |
0.553871 |
-1.436033 |
-1.348179 |
0.244897 |
1.465071 |
| 2 |
1.378478 |
-0.869294 |
0.797711 |
-0.539044 |
-1.211413 |
| 3 |
2.739525 |
-0.111984 |
-1.468831 |
1.418846 |
0.182972 |
df1.sort_values('a',ascending=False)
|
a |
b |
c |
d |
e |
| 3 |
2.739525 |
-0.111984 |
-1.468831 |
1.418846 |
0.182972 |
| 2 |
1.378478 |
-0.869294 |
0.797711 |
-0.539044 |
-1.211413 |
| 1 |
0.553871 |
-1.436033 |
-1.348179 |
0.244897 |
1.465071 |
| 0 |
0.173908 |
-0.978290 |
-0.791529 |
-1.769024 |
-1.971549 |
三、重命名DataFrame的index
import numpy as np
import pandas as pa
from pandas import Series,DataFrame
1.重命名 index
df1 = DataFrame(np.arange(9).reshape(3,3),index=['A','B','C'],columns=['AA','BB','CC'])
df1
|
AA |
BB |
CC |
| A |
0 |
1 |
2 |
| B |
3 |
4 |
5 |
| C |
6 |
7 |
8 |
df1.index=Series(['a','b','c'])
df1
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
|
AA |
BB |
CC |
| a |
0 |
1 |
2 |
| b |
3 |
4 |
5 |
| c |
6 |
7 |
8 |
df1.index = df1.index.map(str.upper)
df1
df1.rename(index=str.lower,columns=str.lower)
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
|
aa |
bb |
cc |
| a |
0 |
1 |
2 |
| b |
3 |
4 |
5 |
| c |
6 |
7 |
8 |
df1
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
|
AA |
BB |
CC |
| A |
0 |
1 |
2 |
| B |
3 |
4 |
5 |
| C |
6 |
7 |
8 |
df1.rename(index={'A':'g'})
|
AA |
BB |
CC |
| g |
0 |
1 |
2 |
| B |
3 |
4 |
5 |
| C |
6 |
7 |
8 |
2.復習
list1 = [1,2,3,4]
list2 = ['1','2','3','4']
[str(x) for x in list1]
[‘1’, ‘2’, ‘3’, ‘4’]
list(map(str,list1))
[‘1’, ‘2’, ‘3’, ‘4’]
3.寫一個自己的 map
def test_map(x):
return x + '_ABC'
df1.index.map(test_map)
Index([‘A_ABC’, ‘B_ABC’, ‘C_ABC’], dtype=’object’)
df1.rename(index=test_map)
|
AA |
BB |
CC |
| A_ABC |
0 |
1 |
2 |
| B_ABC |
3 |
4 |
5 |
| C_ABC |
6 |
7 |
8 |
四、DataFrame 的merge(合并)操作
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
df1 = DataFrame({'key':['X','Y','Z'],'data_set_1':[1,2,3]})
df1
|
key |
data_set_1 |
| 0 |
X |
1 |
| 1 |
Y |
2 |
| 2 |
Z |
3 |
df2 = DataFrame({'key':['X','X','C'],'data_set_2':[4,5,6]})
df2
|
key |
data_set_2 |
| 0 |
X |
4 |
| 1 |
X |
5 |
| 2 |
C |
6 |
pd.merge(df1,df2)
|
key |
data_set_1 |
data_set_2 |
| 0 |
X |
1 |
4 |
| 1 |
X |
1 |
5 |
pd.merge(df1,df2,on='key',how='left')
|
key |
data_set_1 |
data_set_2 |
| 0 |
X |
1 |
4.0 |
| 1 |
X |
1 |
5.0 |
| 2 |
Y |
2 |
NaN |
| 3 |
Z |
3 |
NaN |
pd.merge(df1,df2,on='key',how='right')
|
key |
data_set_1 |
data_set_2 |
| 0 |
X |
1.0 |
4 |
| 1 |
X |
1.0 |
5 |
| 2 |
C |
NaN |
6 |
pd.merge(df1,df2,on='key',how='outer')
|
key |
data_set_1 |
data_set_2 |
| 0 |
X |
1.0 |
4.0 |
| 1 |
X |
1.0 |
5.0 |
| 2 |
Y |
2.0 |
NaN |
| 3 |
Z |
3.0 |
NaN |
| 4 |
C |
NaN |
6.0 |
五、Concatenaten和Combine
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
1>Concatenaten
1.Numpy array
arr1 = np.arange(9).reshape(3,3)
arr1
array([[0, 1, 2],
[3, 4, 5],
[6, 7, 8]])
arr2 = np.arange(9).reshape(3,3)
arr2
array([[0, 1, 2],
[3, 4, 5],
[6, 7, 8]])
np.concatenate([arr1,arr2])
array([[0, 1, 2],
[3, 4, 5],
[6, 7, 8],
[0, 1, 2],
[3, 4, 5],
[6, 7, 8]])
2.Series
s1 = Series([1,2,3],index=['X','Y','Z'])
s2 = Series([4,5],index=['A','B'])
pd.concat([s1,s2])
X 1
Y 2
Z 3
A 4
B 5
dtype: int64
pd.concat([s1,s2],axis=1)
|
0 |
1 |
| A |
NaN |
4.0 |
| B |
NaN |
5.0 |
| X |
1.0 |
NaN |
| Y |
2.0 |
NaN |
| Z |
3.0 |
NaN |
3.DataFrame
df1 = DataFrame(np.random.randn(4,3),columns=['X','Y,','Z'])
df1
|
X |
Y, |
Z |
| 0 |
0.542921 |
1.710888 |
1.027810 |
| 1 |
0.624385 |
-0.825916 |
0.893589 |
| 2 |
-1.000241 |
2.551461 |
1.541975 |
| 3 |
0.020806 |
0.635956 |
0.573629 |
df2 = DataFrame(np.random.randn(3,3),columns=['X','Y,','A'])
df2
|
X |
Y, |
A |
| 0 |
-0.721702 |
-0.106360 |
-1.701335 |
| 1 |
0.591009 |
0.233578 |
0.212189 |
| 2 |
0.855895 |
-1.831944 |
0.247578 |
pd.concat([df1,df2])
|
A |
X |
Y, |
Z |
| 0 |
NaN |
0.542921 |
1.710888 |
1.027810 |
| 1 |
NaN |
0.624385 |
-0.825916 |
0.893589 |
| 2 |
NaN |
-1.000241 |
2.551461 |
1.541975 |
| 3 |
NaN |
0.020806 |
0.635956 |
0.573629 |
| 0 |
-1.701335 |
-0.721702 |
-0.106360 |
NaN |
| 1 |
0.212189 |
0.591009 |
0.233578 |
NaN |
| 2 |
0.247578 |
0.855895 |
-1.831944 |
NaN |
2> Combine
1.Series
s1 = Series([2,np.nan,4,np.nan],index=['A','B','C','D'])
s1
A 2.0
B NaN
C 4.0
D NaN
dtype: float64
s2 = Series([1,2,3,4],index=['A','B','C','D'])
s2
A 1
B 2
C 3
D 4
dtype: int64
s1.combine_first(s2)
A 2.0
B 2.0
C 4.0
D 4.0
dtype: float64
2.DataFrame
df1 = DataFrame({'X':[1, np.nan, 3, np.nan],
'Y':[5, np.nan, 7, np.nan],
'Z':[9, np.nan, 11, np.nan]})
df1
|
X |
Y |
Z |
| 0 |
1.0 |
5.0 |
9.0 |
| 1 |
NaN |
NaN |
NaN |
| 2 |
3.0 |
7.0 |
11.0 |
| 3 |
NaN |
NaN |
NaN |
df2 = DataFrame({'Z':[np.nan, 10, np.nan, 12],
'A':[1,2,3,4],})
df2
|
Z |
A |
| 0 |
NaN |
1 |
| 1 |
10.0 |
2 |
| 2 |
NaN |
3 |
| 3 |
12.0 |
4 |
df1.combine_first(df2)
|
A |
X |
Y |
Z |
| 0 |
1.0 |
1.0 |
5.0 |
9.0 |
| 1 |
2.0 |
NaN |
NaN |
10.0 |
| 2 |
3.0 |
3.0 |
7.0 |
11.0 |
| 3 |
4.0 |
NaN |
NaN |
12.0 |
六、通過apply進行數據預處理
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
df = pd.read_csv('data.csv')
df.head()
|
time |
data |
| 0 |
1124352.0 |
AA: BB: CC: DD |
| 1 |
1124352.0 |
AA: BB: CC: DD |
| 2 |
1124352.0 |
AA: BB: CC: DD |
| 3 |
1124353.0 |
AA: BB: CC: DD |
| 4 |
1124353.0 |
AA: BB: CC: DD |
df.size
190
s1 = Series(['a']*190)
df['A'] = s1
df.head()
|
time |
data |
A |
| 0 |
1124352.0 |
AA: BB: CC: DD |
a |
| 1 |
1124352.0 |
AA: BB: CC: DD |
a |
| 2 |
1124352.0 |
AA: BB: CC: DD |
a |
| 3 |
1124353.0 |
AA: BB: CC: DD |
a |
| 4 |
1124353.0 |
AA: BB: CC: DD |
a |
df['A'] = df['A'].apply(str.upper)
df.head()
|
time |
data |
A |
| 0 |
1124352.0 |
AA: BB: CC: DD |
A |
| 1 |
1124352.0 |
AA: BB: CC: DD |
A |
| 2 |
1124352.0 |
AA: BB: CC: DD |
A |
| 3 |
1124353.0 |
AA: BB: CC: DD |
A |
| 4 |
1124353.0 |
AA: BB: CC: DD |
A |
將data分割多列
df['data'][0].split(' ')
[”, ‘AA:’, ‘BB:’, ‘CC:’, ‘DD’]
list_1 = df['data'][0].strip().split(' ')
list_1
[‘AA:’, ‘BB:’, ‘CC:’, ‘DD’]
要求:將第2列和第4列取出重新放入data列
使用 head() 需要注意,如果對 df 操作時使用1了 head()會使只操作了前幾行
使用 head() 來查看就好
list_1[1],list_1[3]
(‘BB:’, ‘DD’)
def foo(line):
items = line.strip().split(' ')
return Series([items[1],items[3]])
df_tmp = df['data'].apply(foo)
df_tmp.head()
|
0 |
1 |
| 0 |
BB: |
DD |
| 1 |
BB: |
DD |
| 2 |
BB: |
DD |
| 3 |
BB: |
DD |
| 4 |
BB: |
DD |
df_tmp = df_tmp.rename(columns={0:"B",1:"D"})
df_tmp.head()
|
B |
D |
| 0 |
BB: |
DD |
| 1 |
BB: |
DD |
| 2 |
BB: |
DD |
| 3 |
BB: |
DD |
| 4 |
BB: |
DD |
df.head()
|
time |
data |
A |
| 0 |
1124352.0 |
AA: BB: CC: DD |
A |
| 1 |
1124352.0 |
AA: BB: CC: DD |
A |
| 2 |
1124352.0 |
AA: BB: CC: DD |
A |
| 3 |
1124353.0 |
AA: BB: CC: DD |
A |
| 4 |
1124353.0 |
AA: BB: CC: DD |
A |
df_new = df.combine_first(df_tmp)
df_new.head()
|
A |
B |
D |
data |
time |
| 0 |
A |
BB: |
DD |
AA: BB: CC: DD |
1124352.0 |
| 1 |
A |
BB: |
DD |
AA: BB: CC: DD |
1124352.0 |
| 2 |
A |
BB: |
DD |
AA: BB: CC: DD |
1124352.0 |
| 3 |
A |
BB: |
DD |
AA: BB: CC: DD |
1124353.0 |
| 4 |
A |
BB: |
DD |
AA: BB: CC: DD |
1124353.0 |
del df_new['A']
del df_new['data']
df_new.head()
|
B |
D |
time |
| 0 |
BB: |
DD |
1124352.0 |
| 1 |
BB: |
DD |
1124352.0 |
| 2 |
BB: |
DD |
1124352.0 |
| 3 |
BB: |
DD |
1124353.0 |
| 4 |
BB: |
DD |
1124353.0 |
df_new.to_csv('df_new.csv')
——–
七、通過去重清洗數據
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
df = pd.read_csv('data.csv')
df.head()
|
time |
data |
| 0 |
1124352 |
AA: BB: CC: DD |
| 1 |
1124352 |
AA: BB: CC: DD |
| 2 |
1124352 |
AA: BB: CC: DD |
| 3 |
1124353 |
AA: BB: CC: DD |
| 4 |
1124353 |
FF: BB: CC: DD |
df.size
190
len(df)
95
len(df['time'].unique())
22
去重
df['time'].duplicated().head()
0 False
1 True
2 True
3 False
4 True
Name: time, dtype: bool
df_new = df.drop_duplicates()
df_new.head()
|
time |
data |
| 0 |
1124352 |
AA: BB: CC: DD |
| 3 |
1124353 |
AA: BB: CC: DD |
| 4 |
1124353 |
FF: BB: CC: DD |
| 6 |
1124354 |
AA: BB: CC: DD |
| 7 |
1124354 |
CC: BB : CC: DD |
df_new = df.drop_duplicates({'data'},keep='last')
df_new.head()
|
time |
data |
| 4 |
1124353 |
FF: BB: CC: DD |
| 7 |
1124354 |
CC: BB : CC: DD |
| 94 |
1124373 |
AA: BB: CC: DD |
八、時間序列的操作基礎
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
from datetime import datetime
t1 = datetime(2009,10,20)
t1
datetime.datetime(2009, 10, 20, 0, 0)
date_list = [
datetime(2016,9,1),
datetime(2016,9,10),
datetime(2017,9,1),
datetime(2017,9,10),
datetime(2017,10,1)
]
date_list
[datetime.datetime(2016, 9, 1, 0, 0),
datetime.datetime(2016, 9, 10, 0, 0),
datetime.datetime(2017, 9, 1, 0, 0),
datetime.datetime(2017, 9, 10, 0, 0),
datetime.datetime(2017, 10, 1, 0, 0)]
s1 = Series(np.random.rand(5),index=date_list)
s1
2016-09-01 0.497374
2016-09-10 0.686276
2017-09-01 0.788562
2017-09-10 0.765383
2017-10-01 0.546197
dtype: float64
s1[1]
0.6862758320157275
s1[datetime(2016,9,10)]
0.6862758320157275
s1['2016-9-10']
0.6862758320157275
s1['20160910']
0.6862758320157275
s1['2016-9']
2016-09-01 0.497374
2016-09-10 0.686276
dtype: float64
s1['2017']
2017-09-01 0.788562
2017-09-10 0.765383
2017-10-01 0.546197
dtype: float64
date_list_new = pd.date_range(start='2017-01-01',periods=10)
date_list_new
DatetimeIndex([‘2017-01-01’, ‘2017-01-02’, ‘2017-01-03’, ‘2017-01-04…)
s2 = Series(np.random.rand(10),index=date_list_new)
s2
2017-01-01 0.152626
2017-01-02 0.590219
…
Freq: D, dtype: float64
——
九、時間序列數據的采樣和畫圖
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
t_range = pd.date_range('2016-01-01','2016-12-01')
t_range
DatetimeIndex([‘2016-01-01’, ‘2016-01-02’, ‘2016-01-03’, ‘2016-01-04’,
‘2016-01-05’, ‘2016-01-06’, ‘2016-01-07’, ‘2016-01-
….)
s1 = Series(np.random.randn(len(t_range)),index=t_range)
s1.head()
2016-01-01 0.145550
2016-01-02 2.444428
...
Freq: D, dtype: float64
采樣
s1['2016-01'].mean()
-0.14446619115276657
s1_month = s1.resample('M').mean()
s1_month.head()
2016-01-31 -0.144466
2016-02-29 0.083245
2016-03-31 0.204149
Freq: M, dtype: float64
數據填充
s1_test = s1.resample('H').ffill()
s1_test.head()
2016-01-01 00:00:00 0.14555
2016-01-01 01:00:00 0.14555
2016-01-01 02:00:00 0.14555
2016-01-01 03:00:00 0.14555
2016-01-01 04:00:00 0.14555
Freq: H, dtype: float64
s1_test = s1.resample('H').bfill()
s1_test.head()
2016-01-01 00:00:00 0.145550
2016-01-01 01:00:00 2.444428
2016-01-01 02:00:00 2.444428
2016-01-01 03:00:00 2.444428
2016-01-01 04:00:00 2.444428
Freq: H, dtype: float64
簡單畫圖
t_range = pd.date_range('2016-01-01','2016-12-31',freq='H')
t_range
DatetimeIndex(['2016-01-01 00:00:00', '2016-01-01 01:00:00',
'2016-01-01 02:00:00', '2016-01-01 03:00:00',
'2016-01-01 04:00:00', '2016-01-01 05:00:00',
'2016-01-01 06:00:00', '2016-01-01 07:00:00',
'2016-01-01 08:00:00', '2016-01-01 09:00:00',
...
)
stock_df = DataFrame(index=t_range)
stock_df.head(10)
|
| 2016-01-01 00:00:00 |
| 2016-01-01 01:00:00 |
| 2016-01-01 02:00:00 |
| 2016-01-01 03:00:00 |
| 2016-01-01 04:00:00 |
| 2016-01-01 05:00:00 |
stock_df['data1'] = np.random.randint(80,160,size=len(t_range))
stock_df.head(10)
|
data1 |
| 2016-01-01 00:00:00 |
147 |
| 2016-01-01 01:00:00 |
147 |
| 2016-01-01 02:00:00 |
159 |
| 2016-01-01 03:00:00 |
99 |
| 2016-01-01 04:00:00 |
119 |
| 2016-01-01 05:00:00 |
136 |
| 2016-01-01 06:00:00 |
102 |
stock_df['data2'] = np.random.randint(40,140,size=len(t_range))
stock_df.head(10)
|
data1 |
data2 |
| 2016-01-01 00:00:00 |
147 |
44 |
| 2016-01-01 01:00:00 |
147 |
93 |
| 2016-01-01 02:00:00 |
159 |
81 |
| 2016-01-01 03:00:00 |
99 |
108 |
| 2016-01-01 04:00:00 |
119 |
55 |
| 2016-01-01 05:00:00 |
136 |
106 |
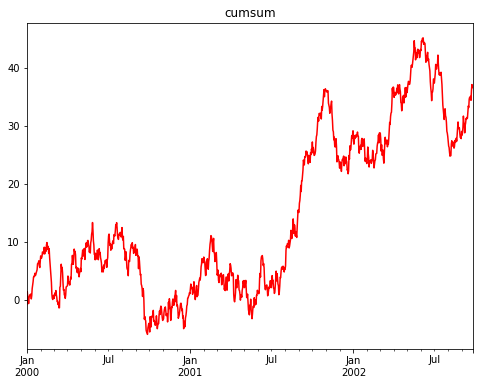
stock_df.plot()
<matplotlib.axes._subplots.AxesSubplot at 0x249d416d438>

import matplotlib.pyplot as plt
plt.show()
按周取樣再繪圖
weekly_df = DataFrame()
weekly_df['data1'] = stock_df['data1'].resample('W').mean()
weekly_df['data2'] = stock_df['data2'].resample('W').mean()
weekly_df.head()
|
data1 |
data2 |
| 2016-01-03 |
119.000000 |
85.111111 |
| 2016-01-10 |
119.095238 |
90.345238 |
weekly_df.plot()
plt.show()

十、數據分箱技術-Binning
什么是數據分箱?
例如 不同大小的蘋果分裝在不同的箱子
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
score_list = np.random.randint(0,100,size=20)
score_list
array([87, 83, 40, 14, 4, 31, 46, 17, 96, 99, 39, 4, 85, 8, 64, 82, 32,
28, 36, 40])
bins = [0,59,70,80,100]
數據分箱
score_cut = pd.cut(score_list,bins)
score_cut
[(80, 100], (80, 100], (0, 59], (0, 59], (0, 59], …, (80, 100], (0, 59], (0, 59], (0, 59], (0, 59]]
Length: 20
Categories (4, interval[int64]): [(0, 59]
pd.value_counts(score_cut)
(0, 59] 13
(80, 100] 6
(59, 70] 1
(70, 80] 0
dtype: int64
df = DataFrame()
df['score'] = score_list
df['student'] = [pd.util.testing.rands(3) for i in range(20)]
df.head()
|
score |
student |
| 0 |
87 |
w5S |
| 1 |
83 |
cQX |
| 2 |
40 |
JYH |
| 3 |
14 |
Cs3 |
| 4 |
4 |
niX |
數據分箱 cut()函數
cut(數據,區間-list,labels=[‘各區間的表示標簽’,’…’])
df['Categories'] = pd.cut(df['score'],bins,labels=['Low','OK','Good','Great'])
df.head()
|
score |
student |
Categories |
| 0 |
87 |
w5S |
Great |
| 1 |
83 |
cQX |
Great |
| 2 |
40 |
JYH |
Low |
| 3 |
14 |
Cs3 |
Low |
| 4 |
4 |
niX |
Low |
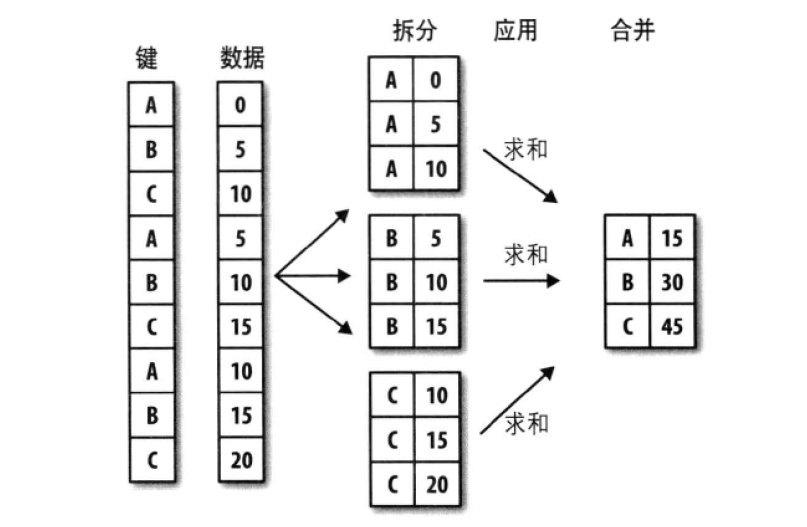
十一、數據分組技術-GroupBy
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
原理類似SQL
df = pd.read_csv('weather.csv')
df.head()
|
date |
city |
temperature |
wind |
| 0 |
2017/1/1 |
GZ |
12 |
3 |
| 1 |
2017/1/8 |
BJ |
2 |
5 |
| 2 |
2017/1/15 |
SH |
-4 |
6 |
| 3 |
2017/1/22 |
GZ |
6 |
1 |
| 4 |
2017/1/29 |
BJ |
13 |
3 |
分組
g = df.groupby(df['city'])
g
g.groups
{‘BJ’: Int64Index([1, 4, 7, 10, 13, 16, 19, 22, 25, 28], dtype=’int64’),
‘GZ’: Int64Index([0, 3, 6, 9, 12, 15, 18, 21, 24, 27], dtype=’int64’),
‘SH’: Int64Index([2, 5, 8, 11, 14, 17, 20, 23, 26], dtype=’int64’)}
g_gz = g.get_group('GZ')
g_gz.head()
|
date |
city |
temperature |
wind |
| 0 |
2017/1/1 |
GZ |
12 |
3 |
| 3 |
2017/1/22 |
GZ |
6 |
1 |
| 6 |
2017/2/12 |
GZ |
12 |
5 |
| 9 |
2017/3/5 |
GZ |
6 |
9 |
| 12 |
2017/3/26 |
GZ |
12 |
6 |
g_gz.mean()
temperature 9.0
wind 4.5
dtype: float64
g.mean()
|
temperature |
wind |
| city |
|
|
| BJ |
7.500000 |
4.5 |
| GZ |
9.000000 |
4.5 |
| SH |
-1.333333 |
4.0 |
十二、數據聚合技術Aggregation
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
df = pd.read_csv('weather.csv')
g = df.groupby('city')
聚合
mean() count() max() 等都是聚合
g.agg('min')
|
date |
temperature |
wind |
| city |
|
|
|
| BJ |
2017/1/29 |
2 |
1 |
| GZ |
2017/1/1 |
6 |
1 |
| SH |
2017/1/15 |
-4 |
1 |
自定義函數 來聚合
def foo(attr):
return attr.max() - attr.min()
g.agg(foo)
|
temperature |
wind |
| city |
|
|
| BJ |
11 |
8 |
| GZ |
6 |
8 |
| SH |
6 |
6 |
多columns分組
g_new = df.groupby(['city','wind'])
g_new.groups
{(‘BJ’, 1): Int64Index([13], dtype=’int64’),
(‘BJ’, 2): Int64Index([25], dtype=’int64’),
(‘BJ’, 3): Int64Index([4, 10], dtype=’int64’),
(‘BJ’, 4): Int64Index([7], dtype=’int64’),
……}
g_new.get_group(('BJ',3))
|
date |
city |
temperature |
wind |
| 4 |
2017/1/29 |
BJ |
13 |
3 |
| 10 |
2017/3/12 |
BJ |
13 |
3 |
對多 columns 遍歷需要注意
for (name_1,name_2),group in g_new:
print(name_1,name_2)
print(group)
BJ 1
date city temperature wind
13 2017/4/2 BJ 2 1
BJ 2
date city temperature wind
25 2017/6/25 BJ 2 2
…..
十三、透視表
透視表概念來自Excel,為了更好展示數據,對原來的行列進行了一些變化,根據這些變化,相應的數據也變化
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
無數據源 不演示了
df = pd.read_excel()
pd.pivot_table(df,index=[''],...)