【XML】java解析XML(通過Jsoup實現)
標簽: java XML xml java解析XML 通過Jsoup實現 Jsoup
1. 解析
-
解析:操作xml文檔,將文檔中的數據讀取到內存中
-
操作xml文檔
1. 解析(讀取):將文檔中的數據讀取到內存中
2. 寫入:將內存中的數據保存到xml文檔中。持久化的存儲 -
解析xml的方式:
1. DOM:將標記語言文檔一次性加載進內存,在內存中形成一顆dom樹
* 優點:操作方便,可以對文檔進行CRUD的所有操作
* 缺點:占內存
2. SAX:逐行讀取,基于事件驅動的。
* 優點:不占內存。
* 缺點:只能讀取,不能增刪改 -
xml常見的解析器:
- JAXP:sun公司提供的解析器,支持dom和sax兩種思想
- DOM4J:一款非常優秀的解析器
- Jsoup:jsoup 是一款Java 的HTML解析器,可直接解析某個URL地址、HTML文本內容。它提供了一套非常省力的API,可通過DOM,CSS以及類似于jQuery的操作方法來取出和操作數據。
- PULL:Android操作系統內置的解析器,sax方式的。
2. Jsoup
-
Jsoup:jsoup 是一款Java 的HTML解析器,可直接解析某個URL地址、HTML文本內容。它提供了一套非常省力的API,可通過DOM,CSS以及類似于jQuery的操作方法來取出和操作數據。
-
步驟:
1. 導入jar包
2. 獲取Document對象
3. 獲取對應的標簽Element對象
4. 獲取數據 -
XML文件(student.xml)
<?xml version="1.0" encoding="UTF-8" ?>
<students>
<student number="siyi_0001">
<name id="1">
<xing>張</xing>
<ming>三</ming>
</name>
<age>18</age>
<sex>male</sex>
</student>
<student number="siyi_0002">
<name>jack</name>
<age>18</age>
<sex>male</sex>
</student>
</students>
- Demo1
package jsoup;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.File;
import java.io.IOException;
public class JsoupDemo1 {
public static void main(String[] args) throws IOException {
//2.獲取Document對象,根據XML文檔獲取
//2.1獲取student.xml的path
String path = JsoupDemo1.class.getClassLoader().getResource("student.xml").getPath();
//2.2解析xml文檔,加載文檔進內存,獲取dom樹 --> Document
Document document = Jsoup.parse(new File(path), "utf-8");
//3.獲取元素對象 Element
Elements elements = document.getElementsByTag("name");
System.out.println(elements.size());
//3.1獲取第一個name的Element對象
Element element = elements.get(0);
//3.2獲取數據
String name = element.text();
System.out.println(name);
}
}
運行結果:

- Demo2
package jsoup;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import java.io.IOException;
import java.net.URL;
public class JsoupDemo2 {
public static void main(String[] args) throws IOException {
//2.1獲取student.xml的path
String path = JsoupDemo2.class.getClassLoader().getResource("student.xml").getPath();
//2.2解析xml文檔,加載文檔進內存,獲取dom樹 --> Document
/*Document document = Jsoup.parse(new File(path), "utf-8");
System.out.println(document);*/
//2. parse(String html):解析XML或html字符串
/*String str = "<?xml version=\"1.0\" encoding=\"UTF-8\" ?>\n" +
"\n" +
" <students>\n" +
" \t<student number=\"siyi_0001\">\n" +
" \t\t<name>tom</name>\n" +
" \t\t<age>18</age>\n" +
" \t\t<sex>male</sex>\n" +
" \t</student>\n" +
"\t<student number=\"siyi_0002\">\n" +
"\t\t<name>jack</name>\n" +
"\t\t<age>18</age>\n" +
"\t\t<sex>male</sex>\n" +
"\t</student>\n" +
"\n" +
" </students>";
Document document = Jsoup.parse(str);
System.out.println(document);*/
//3.parse(URL url,int timeoutMillis):通過網絡路徑獲取指定的html或xml的文檔對象
URL url = new URL("https://baike.baidu.com/item/jsoup/9012509?fr=aladdin");//代表網絡種的一個資源
Document document = Jsoup.parse(url,5000);
System.out.println(document);
}
}
運行結果(百度百科標簽太多,就不全截屏了):
- Demo3
package jsoup;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.File;
import java.io.IOException;
import java.net.URL;
public class JsoupDemo3 {
public static void main(String[] args) throws IOException {
//1.獲取student.xml的path
String path = JsoupDemo3.class.getClassLoader().getResource("student.xml").getPath();
//2.獲取Document對象
Document document = Jsoup.parse(new File(path), "utf-8");
//3.獲取元素對象
//3.1獲取所有student對象
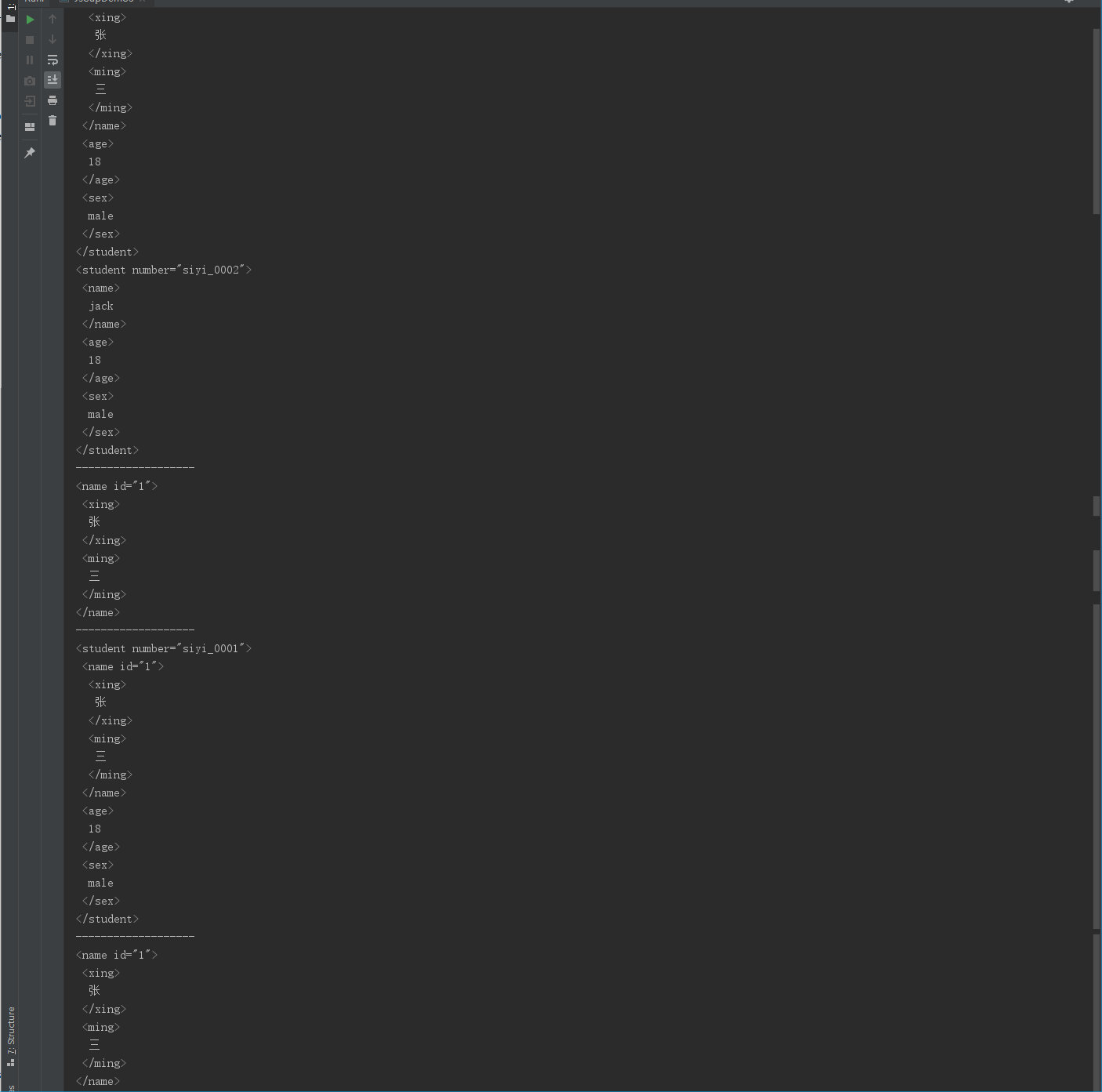
Elements elements = document.getElementsByTag("student");
System.out.println(elements);
System.out.println("-------------------");
//3.2獲取屬性名為id的元素對象
Elements elements1 = document.getElementsByAttribute("id");
System.out.println(elements1);
System.out.println("-------------------");
//3.3獲取屬性值為heima_0001的元素對象
Elements elementsByAttributeValue = document.getElementsByAttributeValue("number", "siyi_0001");
System.out.println(elementsByAttributeValue);
System.out.println("-------------------");
Element elementById = document.getElementById("1");
System.out.println(elementById);
}
}
運行結果:
- Demo4
package jsoup;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.File;
import java.io.IOException;
public class JsoupDemo4 {
public static void main(String[] args) throws IOException {
//1.獲取student.xml的path
String path = JsoupDemo4.class.getClassLoader().getResource("student.xml").getPath();
//2.獲取Document對象
Document document = Jsoup.parse(new File(path), "utf-8");
//通過document對象獲取name標簽,獲取所有的name標簽
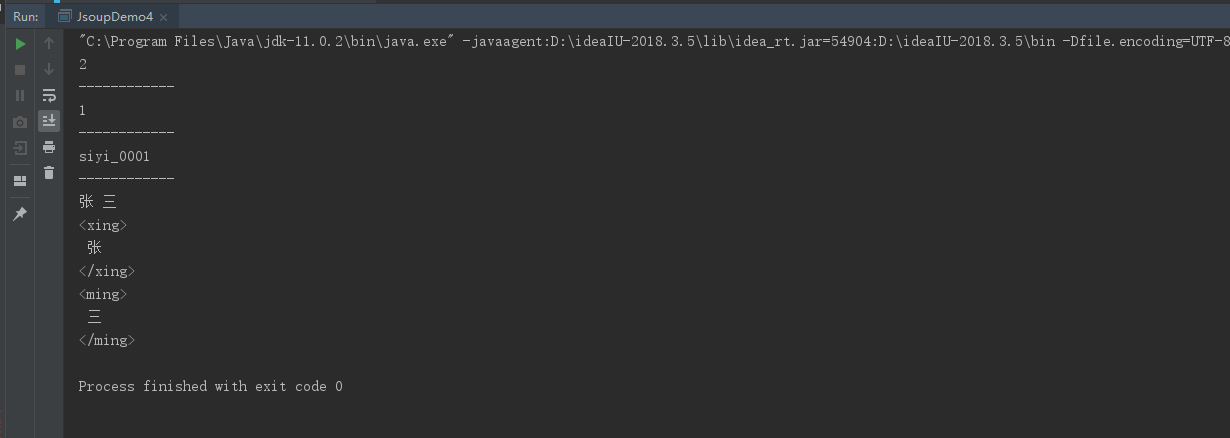
Elements elements = document.getElementsByTag("name");
System.out.println(elements.size());
System.out.println("------------");
Element ele_student = document.getElementsByTag("student").get(0);
Elements ele_name = ele_student.getElementsByTag("name");
System.out.println(ele_name.size());
System.out.println("------------");
//獲取student對象的屬性值
String number = ele_student.attr("number");
System.out.println(number);
System.out.println("------------");
//獲取文本內容
String text = ele_name.text();
String html = ele_name.html();
System.out.println(text);
System.out.println(html);
}
}
運行結果:
- Demo5
package jsoup;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.File;
import java.io.IOException;
public class JsoupDemo5 {
public static void main(String[] args) throws IOException {
//1.獲取student.xml的path
String path = JsoupDemo5.class.getClassLoader().getResource("student.xml").getPath();
//2.獲取Document對象
Document document = Jsoup.parse(new File(path), "utf-8");
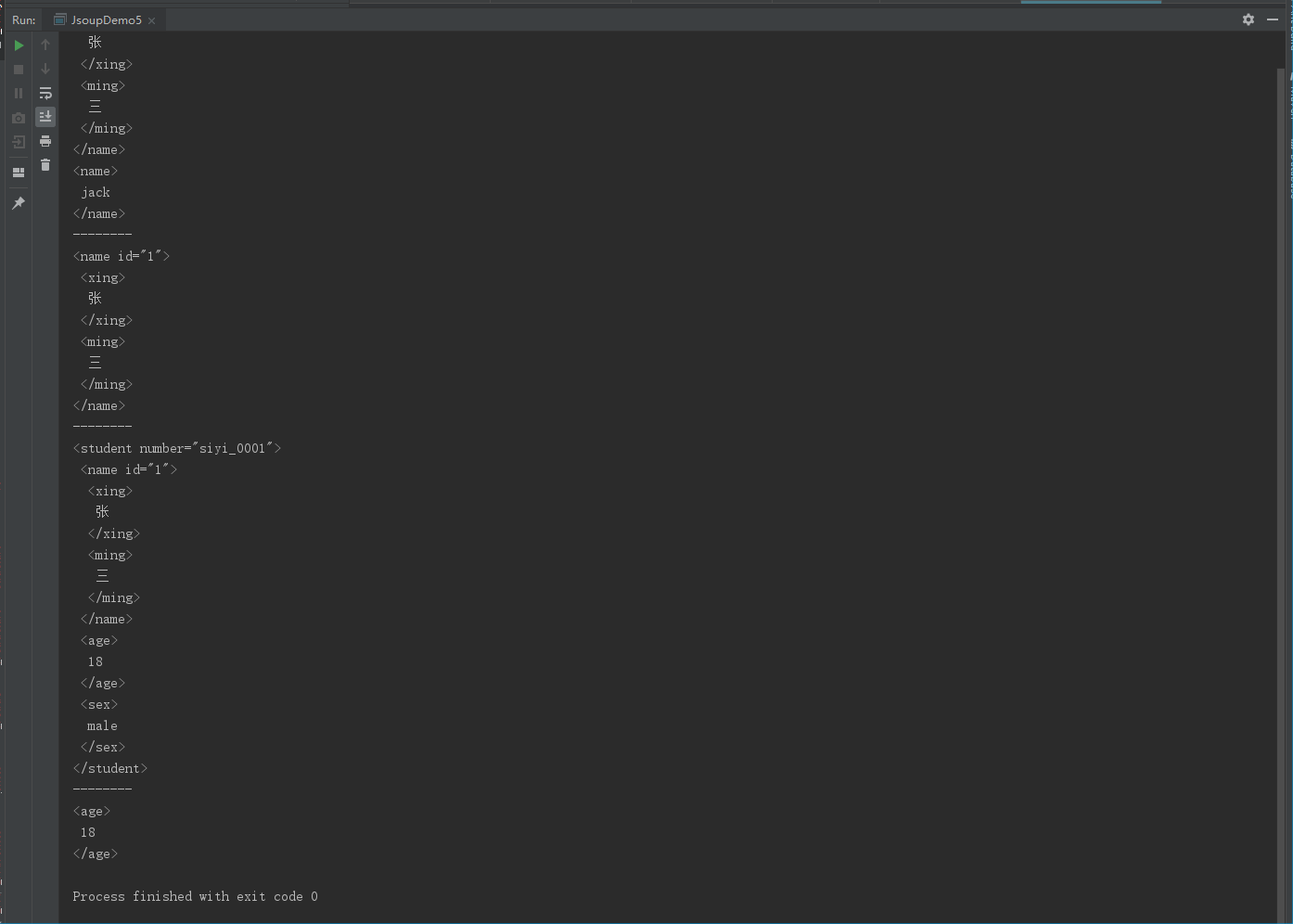
//3.查詢name標簽
Elements elements = document.select("name");
System.out.println(elements);
System.out.println("--------");
//4.查詢id值為1的元素
Elements elements1 = document.select("#1");
System.out.println(elements1);
System.out.println("--------");
//5.獲取student標簽并且number屬性值為siyi_0001的age子標簽
//5.1獲取student標簽并且number屬性值為siyi_0001
Elements elements2 = document.select("student[number='siyi_0001']");
System.out.println(elements2);
System.out.println("--------");
//5.2獲取student標簽并且number屬性值為siyi_0001的age子標簽
Elements elements3 = document.select("student[number='siyi_0001']>age");
System.out.println(elements3);
}
}
運行結果:
- Demo6
package jsoup;
import cn.wanghaomiao.xpath.exception.XpathSyntaxErrorException;
import cn.wanghaomiao.xpath.model.JXDocument;
import cn.wanghaomiao.xpath.model.JXNode;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
import java.io.File;
import java.io.IOException;
import java.util.List;
public class JsoupDemo6 {
public static void main(String[] args) throws IOException, XpathSyntaxErrorException {
//1.獲取student.xml的path
String path = JsoupDemo6.class.getClassLoader().getResource("student.xml").getPath();
//2.獲取Document對象
Document document = Jsoup.parse(new File(path), "utf-8");
//3.根據document對象,創建JXDocument對象
JXDocument jxDocument = new JXDocument(document);
//結合Xpath語法查詢
//4.1查詢所有的student標簽
List<JXNode> jxNodes = jxDocument.selN("//student");
for (JXNode jxNode : jxNodes){
System.out.println(jxNode);
}
System.out.println("--------");
//4.2查詢
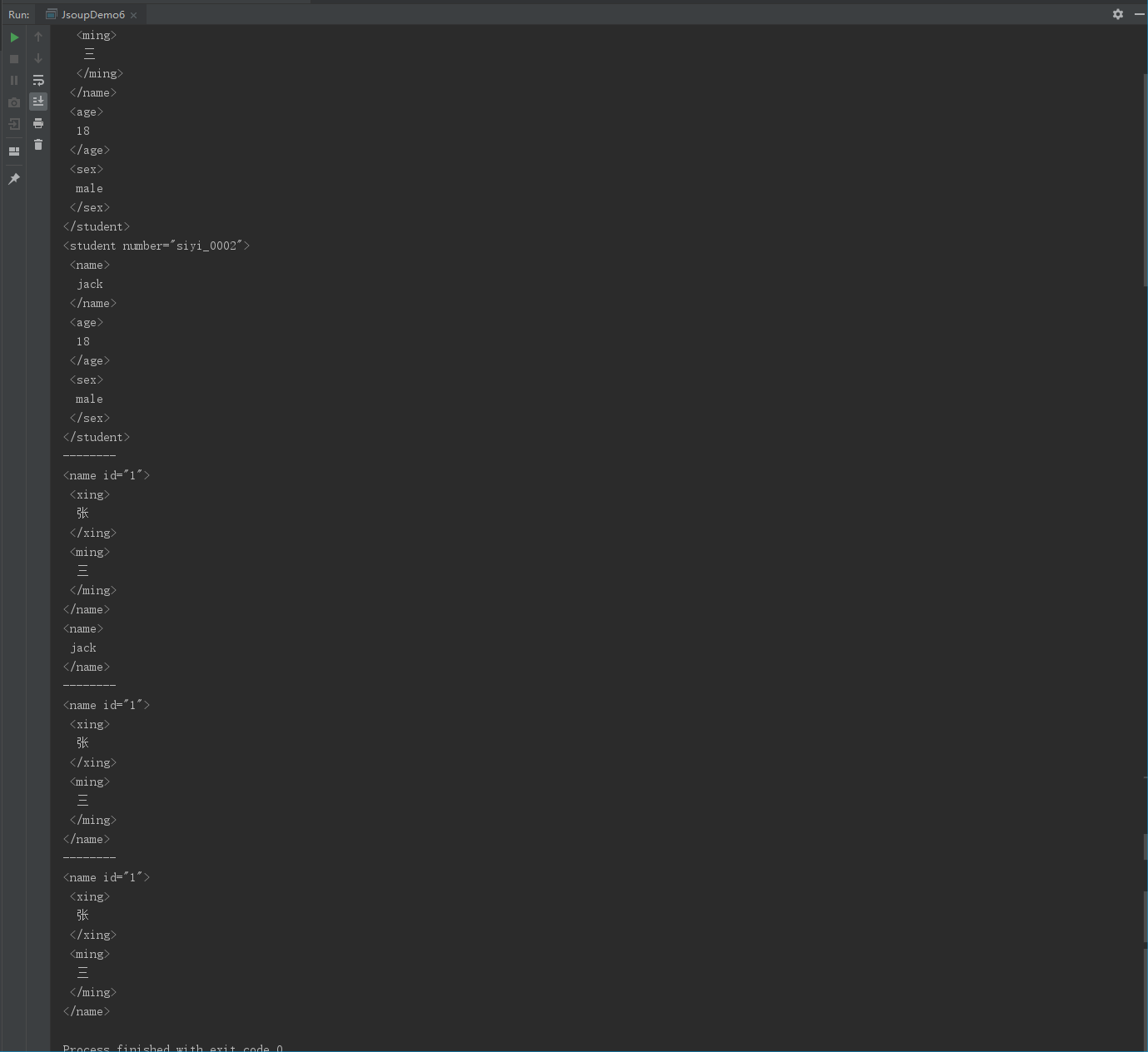
List<JXNode> jxNodes1 = jxDocument.selN("//student/name");
for (JXNode jxNode:jxNodes1) {
System.out.println(jxNode);
}
System.out.println("--------");
//4.3查詢student標簽下帶有id屬性的name標簽
List<JXNode> jxNodes2 = jxDocument.selN("//student/name[@id]");
for (JXNode jxNode:jxNodes2) {
System.out.println(jxNode);
}
System.out.println("--------");
//4.4查詢student標簽下帶有id屬性的name標簽 并且id屬性值為1
List<JXNode> jxNodes3 = jxDocument.selN("//student/name[@id='1']");
for (JXNode jxNode:jxNodes3) {
System.out.println(jxNode);
}
}
}
運行結果:
智能推薦
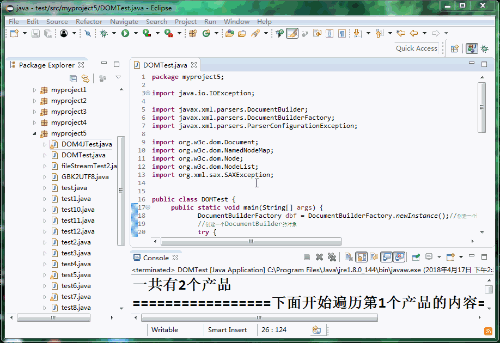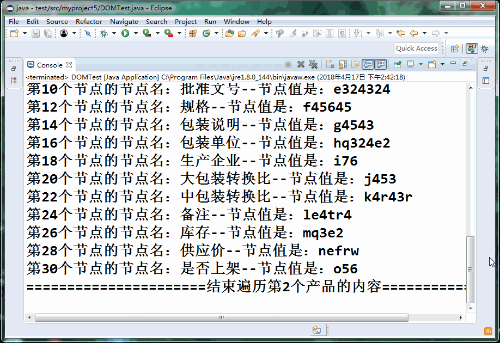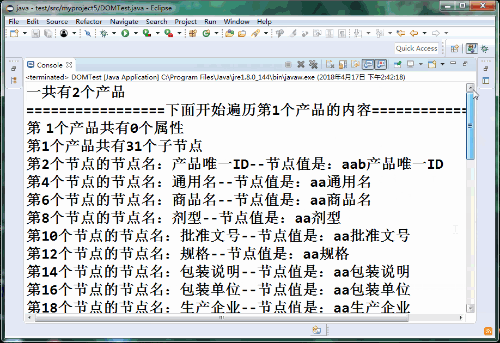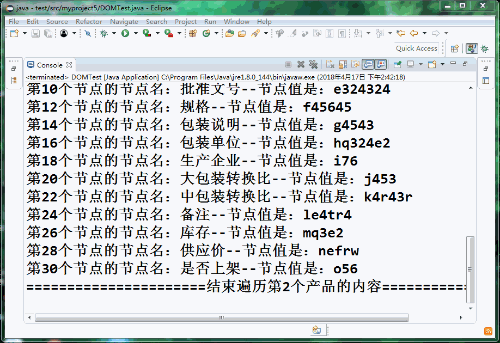
通過DOM方式解析xml
簡述:XML 指可擴展標記語言(eXtensible Markup Language)。 XML 被設計用來傳輸和存儲數據。 XML 很重要,也很容易學習。 什么是xml? XML 指可擴展標記語言(EXtensible Markup Language)。 XML 是一種很像HTML的標記語言。 XML 的設計宗旨是傳輸數據,而不是顯示數據。 XML 標簽沒有被預定義。您需要自行定義標簽。 XML...
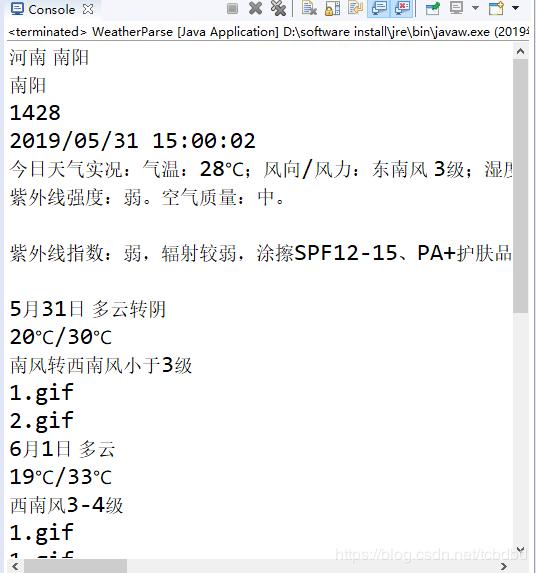
java XML解析
用到的jar包: dom4j-2.0.2 jaxen-1.1.6 1.解析weather.xml 源代碼: 解析結果: 2.解析ticket.xml: 源代碼: 解析結果:...

Java 解析XML
本文系摘抄再整理,來自http://www.w3school.com.cn/xml/xml_attributes.asp等 一、XML解析技術有兩種 DOM方式 根據XML的層級結構在內存中分配一個樹形結構,把XML的標簽,屬性和文本等元素都封裝成樹的節點對象 優點: 便于實現增 刪 改 查 缺點: XML文件過大可能造成內存溢出 SAX方式 采用事件驅動模型邊讀邊解析:從上到下一行行解析,解析到...

java解析XML文件
本文將簡單總結三種不同方式下的xml文件解析,代碼及實例截圖如下: 一、原生簡單的解析,不引入任何jar包 二、DOM解析,一次性把整個xml文檔加載進內存,然后在內存中構建一顆Document的對象樹,通過Document對象,得到樹上的節點對象,通過節點對象訪問(操作)到xml文檔的內容。這里導入dom4j的核心包dom4j-1.6.1.jar進行解析。 三、SAX解析,加載一點,讀取一點,處...
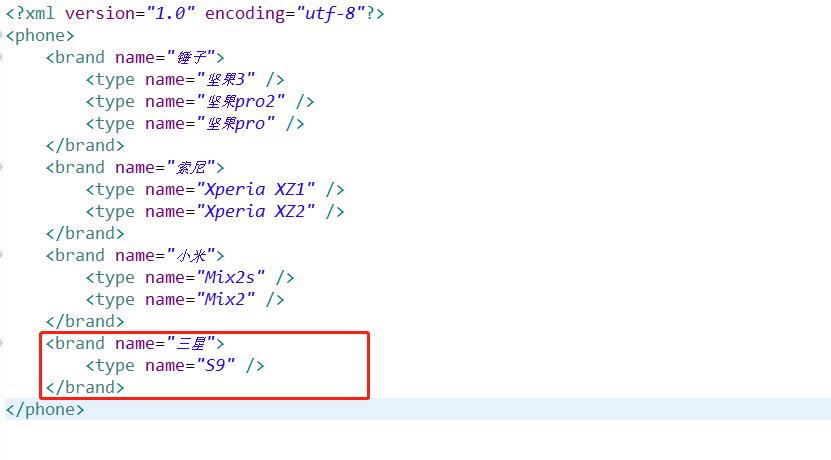
Java核心--XML解析
今天給大家分享關于XML解析的實際應用,XML簡單來說就是一種文件格式,這種格式的文件在Java程序開發中使用地非常廣泛,一般用來做配置文件。 比如需要在web.xml中配置web的相關設置,同時任何一個主流框架都需要通過配置XML文件的方式來完成業務邏輯到框架體系的對接。當然,如果使用SpringBoot這種快速開發框架,則可以大大減少對于XML文件的配置。總體來講,XML在開發中使用的頻率很高...
猜你喜歡
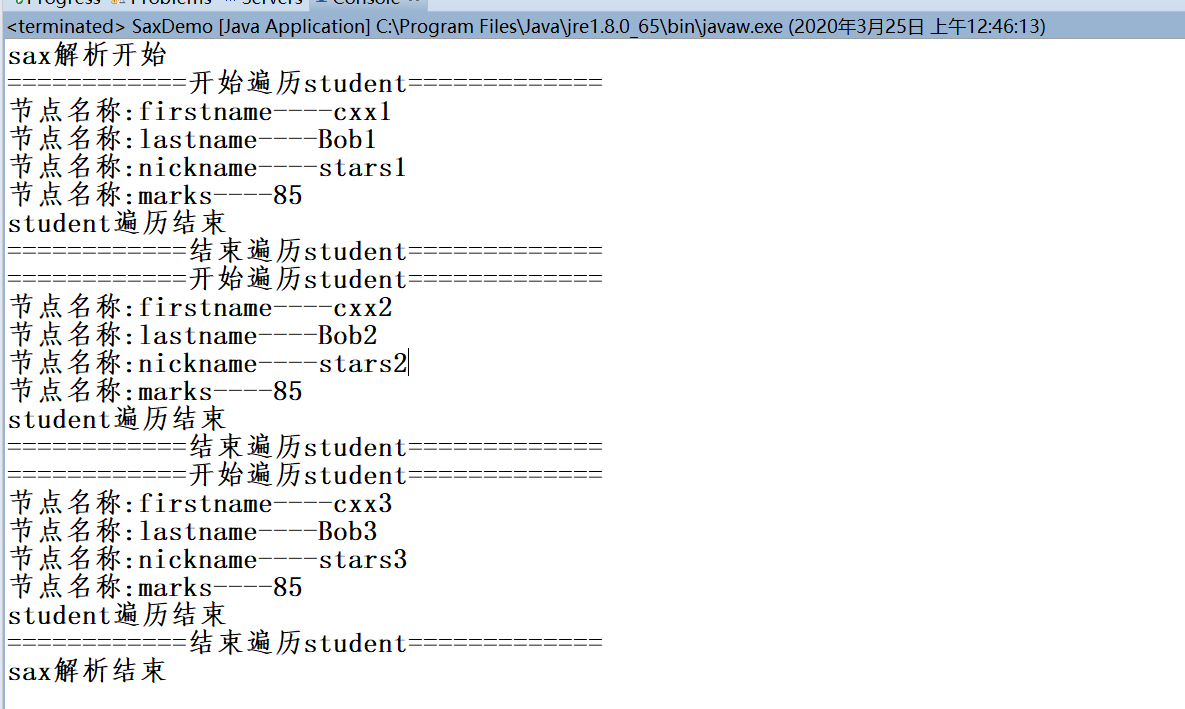
Java解析xml方法
我在模擬tomcat的過程中需要解析xml,所以在此總結下常用的sax/dom,Dom4j,jsoup等。 其實sax/dom使用有點復雜,建議使用DOM4j等技術。 這里sax和dom還有Dom4j借鑒于:https://blog.csdn.net/m0_37499059/article/details/80505567 先看xml demo.xml SAX 運行結果 DOM 運行結果 Dom4...


freemarker + ItextRender 根據模板生成PDF文件
1. 制作模板 2. 獲取模板,并將所獲取的數據加載生成html文件 2. 生成PDF文件 其中由兩個地方需要注意,都是關于獲取文件路徑的問題,由于項目部署的時候是打包成jar包形式,所以在開發過程中時直接安照傳統的獲取方法沒有一點文件,但是當打包后部署,總是出錯。于是參考網上文章,先將文件讀出來到項目的臨時目錄下,然后再按正常方式加載該臨時文件; 還有一個問題至今沒有解決,就是關于生成PDF文件...
電腦空間不夠了?教你一個小秒招快速清理 Docker 占用的磁盤空間!
Docker 很占用空間,每當我們運行容器、拉取鏡像、部署應用、構建自己的鏡像時,我們的磁盤空間會被大量占用。 如果你也被這個問題所困擾,咱們就一起看一下 Docker 是如何使用磁盤空間的,以及如何回收。 docker 占用的空間可以通過下面的命令查看: TYPE 列出了docker 使用磁盤的 4 種類型: Images:所有鏡像占用的空間,包括拉取下來的鏡像,和本地構建的。 Con...