SQLite3源碼學習(15) 零-內存分配器buddy算法
1.概述
SQLite開發者稱它為"memsys5",這個內存分配器的實現不依賴于malloc,實現在mem5.c里,使用時需要打開SQLITE_ENABLE_MEMSYS5編譯選項,應用程序在啟動時還要調用以下接口:
sqlite3_config(SQLITE_CONFIG_HEAP, pBuf, szBuf, mnReq);
其中pBuf為初始內存,szBuf為初始內存大小,mnReq為最小的內存申請請求。
對于動態內存分配問題、內存分配失敗問題,J.M.Robson進行過系統的研究,其結果發表在如下論文中:J. M. Robson. "Bounds for Some Functions Concerning Dynamic Storage Allocation". Journal of the Association for Computing Machinery, Volume 21, Number 8, July 1974, pages 491-499.
我們使用下面的記號(與Robson的記號類似,但不完全等同):
N:內存分配系統為了保證不會出現分配失敗而需要的原始內存數量。
M: 應用程序曾經在任何時間點取出的最大內存數量。
n: 最大內存分配與最小分配的比值。我們假設每個內存分配大小都是最小分配大小的整數倍。
Robson證明了下面的結果:
N = M*(1 + (log2 n)/2) - n + 1
通俗地講,Robson證明表明,為了防止內存分配失敗,任何內存分配器必須使用一個大小為N的內存池,它超過曾經使用的最大內存M乘以一個取決于n的倍數。也就是說,除非所有的內存分配都是同樣的大小,否則系統需要訪問比曾經使用的更大的內存。此外我們看到,需要的剩余內存隨著比值n的增加會迅速的增長,因此我們應該保持所有的內存分配盡可能大小相同。
Robson證明是構造性的。他提出一個算法來計算一個分配和釋放操作系列由于內存碎片(可用內存大于1字節但小N字節)將導致分配失敗。Robson還證明如果可用內存為N或更多的字節,一個“2的冪,首次命中”的內存分配器絕不會出現內存分配失敗。
上面介紹的內容取自官網的文章“Dynamic Memory Allocation In SQLite”,memsys5使用的buddy算法正是一個“2的冪,首次命中”的內存分配器,所以不會出現內存分配失敗。
2.初始化
本文以szBuf為100000,mnReq為10來說明memsys5的實現,TCL腳本可以使用如下語句來測試:
sqlite3_shutdown
sqlite3_config_heap 100000 10
初始化時調用memsys5Init(),在memsys5中每次申請的內存必須是2的冪次方大小,所以最小的分配值mem5.szAtom應該是16而不是10:
static int memsys5Log(int iValue){
int iLog;
for(iLog=0; (iLog<(int)((sizeof(int)*8)-1)) && (1<<iLog)<iValue; iLog++);
return iLog;
}
nMinLog = memsys5Log(sqlite3GlobalConfig.mnReq);// mnReq為10,那么nMinLog算出來是4
mem5.szAtom = (1<<nMinLog);// mem5.szAtom是16然后再把總的內存大小分割成n個block
nByte = sqlite3GlobalConfig.nHeap;
zByte = (u8*)sqlite3GlobalConfig.pHeap;
mem5.nBlock = (nByte / (mem5.szAtom+sizeof(u8)));
mem5.zPool = zByte;
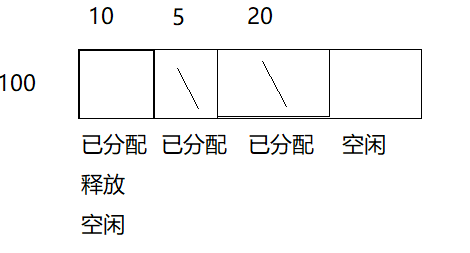
mem5.aCtrl = (u8 *)&mem5.zPool[mem5.nBlock*mem5.szAtom];這里假設nByte是100000,那么mem5.nBlock就是5882,這里5882*16大小的內存用作內存池,還有5882個大小的內存放在mem5.aCtrl用作分配和釋放的管理。
接著對這5882個block再按2的最大冪次方進行分割,如5882分割出4096,剩余1784,1784再分割出1024,如此循環往復:
#define LOGMAX 30
for(ii=0; ii<=LOGMAX; ii++){
mem5.aiFreelist[ii] = -1;
}
iOffset = 0;
for(ii=LOGMAX; ii>=0; ii--){
int nAlloc = (1<<ii);
if( (iOffset+nAlloc)<=mem5.nBlock ){
mem5.aCtrl[iOffset] = ii | CTRL_FREE;//記錄分割后該地址的塊大小并標記為未使用
memsys5Link(iOffset, ii);//把地址記錄到aiFreelist
iOffset += nAlloc;
}
assert((iOffset+nAlloc)>mem5.nBlock);
}分割示意圖如下
![clip_image002[4]](https://img-blog.csdn.net/20180303202217007 "clip_image002[4]")
這樣分割后,就可以用2的冪來代表內存大小了,如4096是12,1024是10,然后我們用aiFreelist來表示某個大小的塊在內存中的位置,如aiFreelist[12]=0, aiFreelist[1]=5880,如果有多個內存塊的大小相同把相同大小的塊用鏈表連接起來。
typedef struct Mem5Link Mem5Link;
struct Mem5Link {
int next; /* Index of next free chunk */
int prev; /* Index of previous free chunk */
};
#define MEM5LINK(idx) ((Mem5Link *)(&mem5.zPool[(idx)*mem5.szAtom]))
/*
** Link the chunk at mem5.aPool[i] so that is on the iLogsize
** free list.
*/
static void memsys5Link(int i, int iLogsize){
int x;
assert( sqlite3_mutex_held(mem5.mutex) );
assert( i>=0 && i<mem5.nBlock );
assert( iLogsize>=0 && iLogsize<=LOGMAX );
assert( (mem5.aCtrl[i] & CTRL_LOGSIZE)==iLogsize );
//i為塊在內存中的地址,iLogsize為塊大小的2次冪
x = MEM5LINK(i)->next = mem5.aiFreelist[iLogsize];
MEM5LINK(i)->prev = -1;//新塊作為頭結點
if( x>=0 ){
assert( x<mem5.nBlock );
MEM5LINK(x)->prev = i;//該大小的塊已經存在,加入鏈表
}
mem5.aiFreelist[iLogsize] = i;//記錄塊大小為2^Logsize的地址
}3.內存申請
假設申請內存大小為64,首先定位滿足64字節大小的內存塊:
for(iFullSz=mem5.szAtom,iLogsize=0; iFullSz<nByte; iFullSz*=2,iLogsize++){}得到iFullSz為64,即4個mem5.szAtom,所以冪iLogsize為2,由上面的分割可知存在2^2個block大小的塊,那么繼續搜索2^3大小的塊,直到找到為止
/* Make sure mem5.aiFreelist[iLogsize] contains at least one free
** block. If not, then split a block of the next larger power of
** two in order to create a new free block of size iLogsize.
*/
for(iBin=iLogsize; iBin<=LOGMAX && mem5.aiFreelist[iBin]<0; iBin++){}找到后把這個塊標記為未使用,并分裂這個塊,一直分裂到最小的塊大小為2^ iLogsize
static void memsys5Unlink(int i, int iLogsize){
int next, prev;
assert( i>=0 && i<mem5.nBlock );
assert( iLogsize>=0 && iLogsize<=LOGMAX );
assert( (mem5.aCtrl[i] & CTRL_LOGSIZE)==iLogsize );
next = MEM5LINK(i)->next;
prev = MEM5LINK(i)->prev;
if( prev<0 ){
mem5.aiFreelist[iLogsize] = next;
}else{
MEM5LINK(prev)->next = next;
}
if( next>=0 ){
MEM5LINK(next)->prev = prev;
}
}
i = mem5.aiFreelist[iBin];
memsys5Unlink(i, iBin);//把這個塊從mem5.aiFreelist[iBin]鏈表中移除,然后再開始分裂
while( iBin>iLogsize ){
int newSize;
/*以下為分裂操作*/
iBin--;
newSize = 1 << iBin;//分成2半
mem5.aCtrl[i+newSize] = CTRL_FREE | iBin;
memsys5Link(i+newSize, iBin);//后一半標記為未使用
}![clip_image004[4]](https://img-blog.csdn.net/20180303202218143 "clip_image004[4]")
要記住把一個塊分裂成2塊后,這2個塊叫做buddy塊,釋放時如果2個buddy塊都為空閑,那么會合并成一塊。
4.內存釋放
這部分是最復雜的,用到了buddy算法,當內存多次分配后,每個原始的塊已經被分裂過很多次,釋放時要找到對應的buddy塊進行合并。合并完成的塊再插入到mem5.aiFreelist鏈表里。
釋放的塊根據一定的特征來判斷自己在分裂的前端還是分裂的后端來尋找自己的buddy。

/*
** Free an outstanding memory allocation.
*/
static void memsys5FreeUnsafe(void *pOld){
u32 size, iLogsize;
int iBlock;
/* Set iBlock to the index of the block pointed to by pOld in
** the array of mem5.szAtom byte blocks pointed to by mem5.zPool.
*/
iBlock = (int)(((u8 *)pOld-mem5.zPool)/mem5.szAtom);//獲取釋放塊的地址
/* Check that the pointer pOld points to a valid, non-free block. */
assert( iBlock>=0 && iBlock<mem5.nBlock );
assert( ((u8 *)pOld-mem5.zPool)%mem5.szAtom==0 );
assert( (mem5.aCtrl[iBlock] & CTRL_FREE)==0 );
iLogsize = mem5.aCtrl[iBlock] & CTRL_LOGSIZE;//獲取2的冪次
size = 1<<iLogsize;//獲取塊的大小
assert( iBlock+size-1<(u32)mem5.nBlock );
mem5.aCtrl[iBlock] |= CTRL_FREE;
mem5.aCtrl[iBlock+size-1] |= CTRL_FREE;
mem5.aCtrl[iBlock] = CTRL_FREE | iLogsize;//標記塊為未使用
while( ALWAYS(iLogsize<LOGMAX) ){
int iBuddy;
if( (iBlock>>iLogsize) & 1 ){//釋放的塊在后端
iBuddy = iBlock - size;//獲取前端buddy
assert( iBuddy>=0 );
}else{//釋放的塊在前端
iBuddy = iBlock + size;//獲取后端buddy
if( iBuddy>=mem5.nBlock ) break;//到內存池的邊界
}
if( mem5.aCtrl[iBuddy]!=(CTRL_FREE | iLogsize) ) break;//buddy仍未釋放
memsys5Unlink(iBuddy, iLogsize);//把buddy從aiFreelist鏈表移除
iLogsize++;//合并后大小為原來2倍
if( iBuddy<iBlock ){// iBuddy為前端
mem5.aCtrl[iBuddy] = CTRL_FREE | iLogsize;
mem5.aCtrl[iBlock] = 0;
iBlock = iBuddy;
}else{// iBlock為前端
mem5.aCtrl[iBlock] = CTRL_FREE | iLogsize;
mem5.aCtrl[iBuddy] = 0;
}
size *= 2;//合并后再繼續下一次合并
}
參考資料:
【1】SQLite剖析(9):動態內存分配
http://blog.csdn.net/zhoudaxia/article/details/8257784
智能推薦
實現內存分配器
兩種內存分配方法:邊界標識法和伙伴系統 1、邊界標識法 比較靈活,但回收不方便 boundary.h boundary.cpp test.cpp 2、伙伴系統 伙伴系統需要直到以下幾個概念: (1)伙伴:將一個大塊,分割成兩個相等的子塊,這兩個子塊互為伙伴。 (2)回收:只合并伙伴 (3)直到一個內存塊的地址,可以求出它伙伴的地址 如果內存塊p為左塊,則伙伴的地址等于p+p->size 如果...
Buddy分配器之釋放一頁
在上面一節我們講述了buddy分配器是如何分配一頁的,本節我們在學習buddy分配器是如何釋放一頁的 分配一頁的算法:比如當前釋放order=n的頁 獲得當前釋放order=n的頁,對應的buddy,也就是兄弟頁,俗話說先找到兄弟 找到兄弟buddy了之后,接下來就是看buddy和此頁是否可以合并 檢查buddy是否是空閑的頁(通過檢查page→private是否為0) 檢查buddy是...
c++ STL 源碼閱讀 分配器(alloctor)實現
STL源碼閱讀之-分配器(alloctor)實現 開始讀STL標準庫,看到分配器的實現,簡直佩服的五體投地,于是自己也實現了一個alloctor 首先簡單說明一下原理: 首先標準庫這樣實現是有原因的 我們平常申請內存用malloc 比如申請10個字節他不只返回10還會返回其他的東西比如記錄大小的cookie, 這樣美調用一次cookie就會產生一些不需要的浪費 如果有100萬次甚至更多就會浪費內存...
BlueStore源碼分析之Stupid分配器
前言 前面介紹了BlueStore的BitMap分配器,我們知道新版本的Bitmap分配器的優勢在于使用連續的內存空間從而盡可能更多的命中CPU Cache以提高分配器性能。在這里我們了解一下基于區間樹的Stupid分配器(類似于Linux Buddy內存管理算法),并對比分析一下其優劣。 目錄 伙伴算法 數據結構 初始化 插入刪除 空間分配 空間回收 優劣分析 伙伴算法 Linux內存管理算法為...

猜你喜歡

freemarker + ItextRender 根據模板生成PDF文件
1. 制作模板 2. 獲取模板,并將所獲取的數據加載生成html文件 2. 生成PDF文件 其中由兩個地方需要注意,都是關于獲取文件路徑的問題,由于項目部署的時候是打包成jar包形式,所以在開發過程中時直接安照傳統的獲取方法沒有一點文件,但是當打包后部署,總是出錯。于是參考網上文章,先將文件讀出來到項目的臨時目錄下,然后再按正常方式加載該臨時文件; 還有一個問題至今沒有解決,就是關于生成PDF文件...
電腦空間不夠了?教你一個小秒招快速清理 Docker 占用的磁盤空間!
Docker 很占用空間,每當我們運行容器、拉取鏡像、部署應用、構建自己的鏡像時,我們的磁盤空間會被大量占用。 如果你也被這個問題所困擾,咱們就一起看一下 Docker 是如何使用磁盤空間的,以及如何回收。 docker 占用的空間可以通過下面的命令查看: TYPE 列出了docker 使用磁盤的 4 種類型: Images:所有鏡像占用的空間,包括拉取下來的鏡像,和本地構建的。 Con...

requests實現全自動PPT模板
http://www.1ppt.com/moban/ 可以免費的下載PPT模板,當然如果要人工一個個下,還是挺麻煩的,我們可以利用requests輕松下載 訪問這個主頁,我們可以看到下面的樣式 點每一個PPT模板的圖片,我們可以進入到詳細的信息頁面,翻到下面,我們可以看到對應的下載地址 點擊這個下載的按鈕,我們便可以下載對應的PPT壓縮包 那我們就開始做吧 首先,查看網頁的源代碼,我們可以看到每一...


Linux C系統編程-線程互斥鎖(四)
互斥鎖 互斥鎖也是屬于線程之間處理同步互斥方式,有上鎖/解鎖兩種狀態。 互斥鎖函數接口 1)初始化互斥鎖 pthread_mutex_init() man 3 pthread_mutex_init (找不到的情況下首先 sudo apt-get install glibc-doc sudo apt-get install manpages-posix-dev) 動態初始化 int pthread_...