Hadoop 3.0環境搭建
標簽: 大數據
Hadoop目錄結構

準備工作:
1、安裝Linux、關閉防火墻、配置主機名、安裝JDK
2、解壓 tar -zxvf 包名
3、設置環境變量:
vi ~/.bash_profile
HADOOP_HOME=/root/training/hadoop-3.1.2
export HADOOP_HOME
PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export PATH
#注意:偽分布模式和全分布模式,需要設置以下環境變量(運行的用戶):
export HDFS_DATANODE_USER=root
export HDFS_DATANODE_SECURE_USER=root
export HDFS_NAMENODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
生效環境變量:
source ~/.bash_profile
安裝模式:
一、本地安裝
注意:本地安裝沒有HDFS、也沒有Yarn只能測試MapReduce程序(本質:就是一個Java程序)
只需要配置hadoop-env.sh Java 環境就行
export JAVA_HOME=/root/training/jdk1.8.0_181
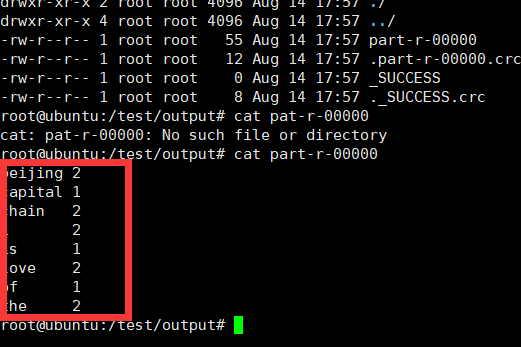
WordCount例子在hadoop-3.1.2/share/hadoop/mapreduce目錄下
例如執行Wordcount程序:
hadoop jar hadoop-mapreduce-examples-3.1.2.jar wordcount /temp/input/ /temp/output/wc
二、偽分布安裝
特點:在單機上,模擬一個分布式的環境,具備Hadoop的所有的功能
HDFS:NameNode主節點、 DataNode從節點、SecondaryNameNode
Yarn:ResourceManager主節點、NodeManager從節點
(1)、配置HDFS
1、在Hadoop-env.sh 配置Java_home 的目錄

修改成下面的路徑,在第25行
export JAVA_HOME=/usr/local/java/jdk1.8.0_251
2、配置hdfs-site.xml 文件
<!-- 配置數據塊的冗余度,默認值為3 -->
<!-- 冗余度和數據節點個數保持一致,不超過3 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!--是否開啟hdfs權限檢查 -->
<!--默認是true,要想啟動成功,必須配置ssh免密登錄,可以改成false,-->
<!--使用密碼進行登錄 -->
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
3、配置core-site.xml 文件
<!--配置hdfs的主節點的地址,就是NameNode的地址 -->
<!--9000是RPC通信端口 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.92.130:9000</value>
</property>
<!--hdfs的數據塊和元信息保存在Linux系統的位置 -->
<!--默認是Linux的tmp目錄,需要修改 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop-2.7.7/temp</value>
</property>
(2)、配置Yarn
1、配置mapred-site.xml
<!--MR程序運行的容器或者框架 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
2、yarn-site.xml 文件
<!--yarn的主節點-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>192.168.92.130</value>
</property>
<!--NodeManager執行任務的方式是Shuffle洗牌-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
(3)對NameNode進行格式化
需要在剛剛我們創建的tmp(保存元信息/usr/local/hadoop-2.7.7/temp)目錄進行格式化
命令如下:
hdfs namenode -format
日志:
NFO common.Storage: Storage directory /usr/local/hadoop-2.7.7/temp/dfs/name has been successfully formatted.
表示格式化成功
(4)啟動
HDFS:start-dfs.sh
Yarn :start-yarn.sh
統一的:start-all.sh
統一停止:stop-all.sh
啟動之后要輸入四次yes和四次密碼
停止之后要輸入四次yes和四次密碼
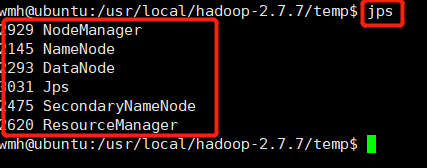
表示環境配置成功!
web console訪問:hdfs端口:50070 、yarn端口:8088
要想不輸入密碼就能登錄,這時我們需要配置免密碼的登錄:
https://blog.csdn.net/qq_45335413/article/details/107810990
三、全分布
四、HA
智能推薦
hadoop3.2環境搭建與問題整理-分布式集群模式
hadoop3環境搭建與問題整理-分布式集群模式 基本流程: 使用版本: 開始配置 準備材料 配置hadoop 遇到的問題 按照如上步驟配置啟動成功。 基本流程: linux網絡配置+環境安裝+環境變量+修改軟件配置腳本+啟動hdfs和yarn 使用版本: linux: ubuntu jdk:jdk-8u231-libux-x64 hadoop:3.2.1 開始配置 參考博客:hadoop2.7配...
CentOS7.4環境下搭建Hadoop2.8.5偽分布集群
這是一篇碰壁2天的難產文章,首先強調一點,本篇文章是針對Hadoop2.x環境的搭建,并不適應于Hadoop3.x(因為我一直用3.x版本試過,一直Error,最后我下了2.8.5版本) 圖片有不準的地方,以文字代碼啊為主,圖片只是演示過程 一、下載合適的Hadoop并解壓,安裝到linux下 1.官網地址:https://had...
Centos7環境搭建hadoop2.9.0集群全流程
1.安裝環境配置 1.1 虛擬機安裝 本案例是在虛擬機平臺搭建hadoop,由于筆記本限制僅以2臺設備構建內部局域網環境下的集群。 虛擬機版本:VMwareWorkstation_10.04_Lite_CHS_V2 系統:CentOS-7-x86_64 安裝2臺虛擬機(本來準備裝3臺,但太卡了所以最后只保留了hserver1,hserver3) 1.2 虛擬機設置固定IP 虛擬機每次...
虛擬機Hadoop-2.7.1環境搭建(CentOS-6.5)
首先,需要安裝三個虛擬機,安裝CentOS-6.5-x86_64-bin-DVD1.bin(要用64位的) 192.168.0.6 master 192.168.0.7 slaver1 192.168.0.8 slaver2 三個虛擬機盡量分開安裝,先分配較多的資源,這樣節省安裝時間,電腦配置高的,你懂得,這都不是事兒 接下來,配置ssh服務,按照文章中的順序來操作 master: slaver1...
大數據實戰 Linux Uduntu 20.04.1 server Hadoop2.8.5環境搭建
1.前期工作 詳細點擊這里,了解更多 2.時間同步 思路:讓主節點連接外網的時間,從節點僅僅連接主節點的時間,達到3臺機時間一樣的目的 2.1 主節點時間同步 2.1.1 安裝軟件包 apt-get install chrony -y 2.1.2 編輯/chrony.conf vi /etc/chrony/chrony.conf 添加 local stratum 10 allow 172.25.0...
猜你喜歡
1.1 大數據 從0到1環境搭建HADOOP偽分布式 hadoop-3.2.1
文章目錄 1、虛擬機安裝 2、虛擬機信息獲取 3、操作系統 4、shh工具 5、查看 rpm -qa | grep pdsh 木得 6、 yum安裝很多木得,先安裝rpm包 7、安裝或查看java -version 8、變更JAVA 為linux版本 支持更穩定 9、新建hadoop用戶以及用戶組,給予sudo權限 10、建個hadoop文件夾 授權給hadoop用戶 11、用hadoop用戶 操...


freemarker + ItextRender 根據模板生成PDF文件
1. 制作模板 2. 獲取模板,并將所獲取的數據加載生成html文件 2. 生成PDF文件 其中由兩個地方需要注意,都是關于獲取文件路徑的問題,由于項目部署的時候是打包成jar包形式,所以在開發過程中時直接安照傳統的獲取方法沒有一點文件,但是當打包后部署,總是出錯。于是參考網上文章,先將文件讀出來到項目的臨時目錄下,然后再按正常方式加載該臨時文件; 還有一個問題至今沒有解決,就是關于生成PDF文件...
電腦空間不夠了?教你一個小秒招快速清理 Docker 占用的磁盤空間!
Docker 很占用空間,每當我們運行容器、拉取鏡像、部署應用、構建自己的鏡像時,我們的磁盤空間會被大量占用。 如果你也被這個問題所困擾,咱們就一起看一下 Docker 是如何使用磁盤空間的,以及如何回收。 docker 占用的空間可以通過下面的命令查看: TYPE 列出了docker 使用磁盤的 4 種類型: Images:所有鏡像占用的空間,包括拉取下來的鏡像,和本地構建的。 Con...

requests實現全自動PPT模板
http://www.1ppt.com/moban/ 可以免費的下載PPT模板,當然如果要人工一個個下,還是挺麻煩的,我們可以利用requests輕松下載 訪問這個主頁,我們可以看到下面的樣式 點每一個PPT模板的圖片,我們可以進入到詳細的信息頁面,翻到下面,我們可以看到對應的下載地址 點擊這個下載的按鈕,我們便可以下載對應的PPT壓縮包 那我們就開始做吧 首先,查看網頁的源代碼,我們可以看到每一...