《深度學習——實戰caffe》——caffe數據結構
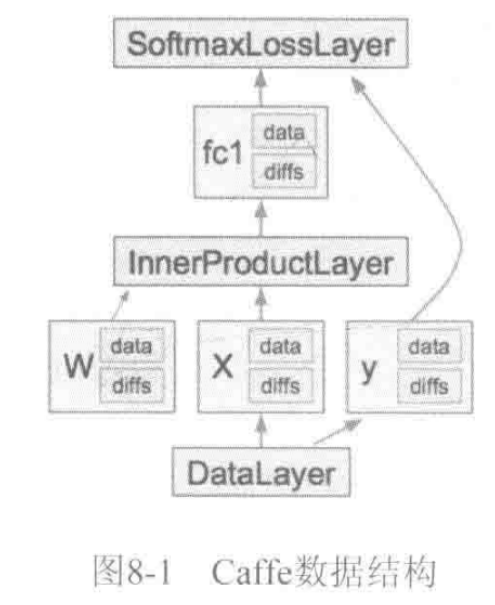
caffe的萬丈高樓(Net)是由圖紙(prototxt),用blob這些磚塊筑成一層層(Layer),最后通過SGD方法(Solver)進行簡裝修(train)、精裝修(finetune)實現的。
- Blob數據結構介紹
Blob提供了統一的存儲器接口,TensorFlow中的Tensor也有對應的Blob數據結構。
Caffe的基本存儲單元是Blob,使用Blob格式的4維數組用于存儲和交換數據,維度從低到高為(width_,height_,channels_,num_),用于存儲數據或權值(data)和權值增量(diff),其中width_和height_分別表示圖像的寬和高,channels_表示顏色通道RGB,num_表示第幾個顏色通道。在進行網絡計算時,每層的輸出/輸入都需要通過Blob對象緩沖。
//使用的是一個Blob的容器是因為某些Layer包含多組學習參數
vector<shared_ptr<Blob<Dtype>>> blobs_;- 1
- 2
- Blob數據結構描述
src/caffe/proto/caffe.proto文件中,Blob描述如下:
// packed表示這些值在內存中緊密排布,沒有空洞
message BlobShape{
//只包括若干int64類型值,分別表示Blob每個維度的大小
repeated int64 dim = 1 [packed = true];
}
message BlobProto{
//包含一個BlobShape對象
optional BlobShape shape = 7;
//包含若干浮點元素,存儲數據或者權值,元素數目由shape或者(num, channels, height, width)確定
repeated float data = 5 [packed = true];
//包含若干浮點元素,存儲增量信息,維度與data數組一致
repeated float diff = 6 [packed = true];
//與data類似,類型為double
repeated double double_data = 7 [packed = true];
//與diff類似,類型為double
repeated double double_diff = 8 [packed = true];
//維度信息可選值,新版Caffe推薦使用shape,而不用后面的值
optional int32 num = 1 [default = 0];
optional int32 channels = 2 [default = 0];
optional int32 height = 3 [default = 0];
optional int32 width = 4 [default = 0];
}
- 函數介紹
Dtype data_at(const int n, const int c, const int h,const int w) const:通過n,c,h,w 4個參數來來獲取該向量位置上的值。
Dtype diff_at(const int n, const int c, const int h,const int w) const
Dtype asum_data() const:絕對值之和,即L1-范式
Dtype asum_diff() const
Dtype sumsq_data() const:平方和,即L2-范式
Dtype sumsq_diff() const
void scale_data(Dtype scale_factor):data乘以一個標量
void scale_diff(Dtype scale_factor)
void ShareData(const Blob& other):共享一個Blob的data
void ShareDiff(const Blob& other)
const Dtype* cpu_data() const:只讀CPU上的數據
const Dtype* gpu_data() const
void set_cpu_data(Dtype* data):設置CPU上的數據
const Dtype* cpu_diff() const:只讀CPU上的偏差
const Dtype* gpu_diff() const
Dtype* mutable_cpu_data():讀寫cpu上的數據
Dtype* mutable_gpu_data()
Dtype* mutable_cpu_diff():讀寫CPU上計算偏差
Dtype* mutable_gpu_diff()
void Update():更新變量值,使數據同步。
void FromProto(const BlobProto& proto, bool reshape=true):反序列化函數,從BlobProto中恢復一個Blob對象
void ToProto(BlobProto* proto, bool write_diff=false) const:序列化函數,將內存中的Blob對象保存到BlobProto中
ToProto()和FromProto()可將Blob內部值保存到磁盤中或者從磁盤中載入到內存。 - 使用ProtoBuffer而不使用結構體的原因:
1)結構體的序列化/反序列化操作需要額外的編程實現,難以做到結構標準化;2)結構體中包含變長數據(一般用指向某個內存地址的指針)時,需要更加細致的工作保證數據的完整性。
ProtoBuffer將編程最容易出現問題的地方加以隱藏,讓機器自動處理,提高了程序的健壯性。 - Blob模板類
在include/caffe/blob.hpp中申明了Blob模板類,并封裝了SyncedMemory類,const int kMaxBlobAxes = 32定義了Blob最大維數目。
//狀態機變量:未初始化、CPU數據有效、GPU數據有效、已同步
enum SyncedHead {UNINITIALIZED, HEAD_AT_CPU, HEAD_AT_GPU, SYNCED}
<span style="color:#333333;">#include <vector>
#include <iostream>
#include <caffe/blob.hpp>
using namespace caffe;
using namespace std;
int main(void)
{
Blob<float> a;
cout<<"Size :"<<a.shape_string()<<endl;
a.Reshape(1,2,3,4);
cout<<"Size :"<<a.shape_string()<<endl;
float *p = a.mutable_cpu_data();
for(int i = 0; i < a.count(); i ++)
{
p[i] = i;
}
for(int u = 0; u < a.num(); u ++)
{
for(int v = 0; v < a.channels(); v ++)
{
for(int w = 0; w < a.height(); w ++)
{
for(int x = 0; x < a.width(); x ++)
{
cout<<"a["<<u<<"]["<< v << "][" << w << "][" << x << "] =" << a.data_at(u,v,w,x)<< endl;
}
}
}
}
return 0;
}
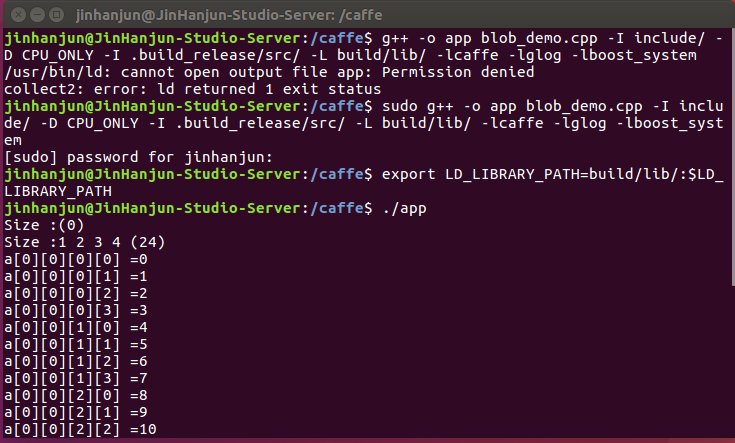
</span>編譯:
sudo g++ -o app blob_demo.cpp -I include/ -D CPU_ONLY -I .build_release/src/ -L build/lib/ -lcaffe -lglog -lboost_system
就生成了可執行文件app
export LD_LIBRARY_PATH=build/lib/:$LD_LIBRARY_PATH
./app
智能推薦
深度學習21天實戰caffe學習筆記《16:Caffe遷移和部署》
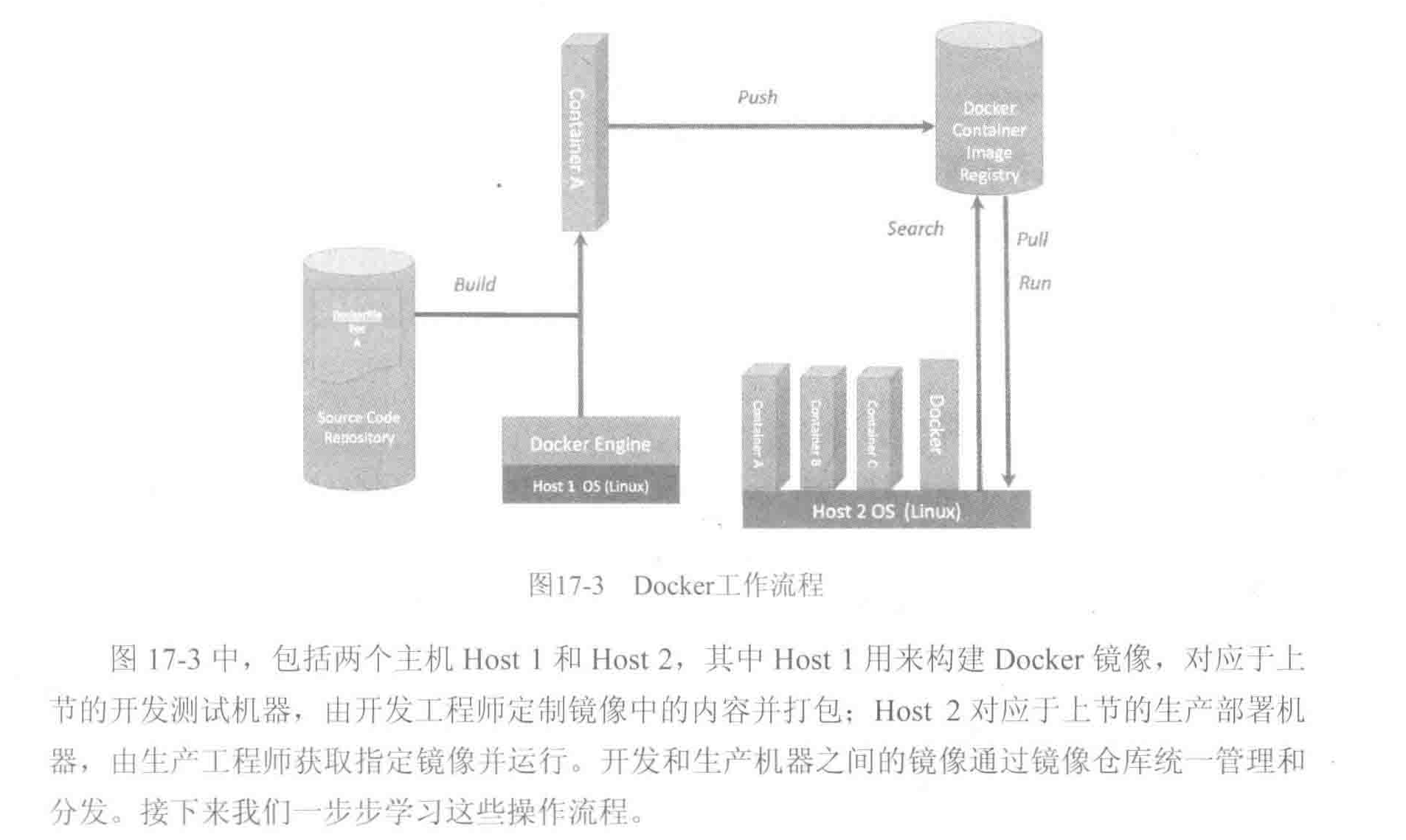
Caffe的遷移和部署 1、從開發測試到生產部署 : 離線訓練、在線識別 開發:離線訓練階段 數據專家選擇訓練數據,算法專家設計模型參數,開發專家優化和調試訓練過程,得到滿足發布的模型,在caffe中表現為*.caffemodel文件; 部署:在線識別階段 利用發布模型到線上或者某個嵌入式平臺生產機器,接入線上其他服務(存儲、數據庫),獲取在線數據并用上述模型處理,將結果返回客戶端。并且將異常結果...
深度學習21天實戰caffe學習筆記《3 :準備Caffe環境》
準備Caffe環境 【如果是其他環境下的配置就請繞道嘍,我也沒有專門去試一試各個環境下的配置,請諒解~】 官網 http://caffe.berkeleyvision.org/installation.html; 首先在這里介紹一下我的硬件環境: Ubuntu 14.04 ---------[ win10遠程連接ssh(putty)+VNC ]: http://www.ubuntu.com/dow...

《深度學習——實戰caffe》——模型各層數據和參數可視化
先用caffe對cifar10進行訓練,將訓練的結果模型進行保存,得到一個caffemodel,然后從測試圖片中選出一張進行測試,并進行可視化。 代碼: 1. 結果如下: (1, 3, 32, 32) 2. 就會顯示圖片 3. 結果如下: (360, 480, 3) 4. 結果如下: [('data', (1, 3, 32, 32)), ('conv1', (1, 32, 32, 32)), ('...
深度學習Caffe實戰筆記(2)用LeNet跑車牌識別數據
caffe實戰之“車牌識別” 上一篇博客寫了如何在cpu的情況下配置環境,配置好環境后編譯成功,就可以用caffe框架訓練卷積神經網絡了。今天介紹如何在caffe環境下,跑車牌識別的數據,利用的網絡是LeNet,這里只介紹具體caffe實戰步驟,網絡結構不做具體介紹。 1、準備數據 在caffe根目錄下的data文件夾下新建一個mine文件夾,在mine文件夾新建一個tra...
深度學習Caffe實戰筆記(3)用AlexNet跑自己的數據
上一篇博客介紹了如何在caffe框架平臺下,用LeNet網絡訓練車牌識別數據,今天介紹用AlexNet跑自己的數據,同樣基于windows平臺下,會比基于Ubuntu平臺下麻煩一些,特別是后面的Siamese網絡,說起Siamese網絡真是一把辛酸一把淚啊,先讓我哭一會,,,,,哭了5分鐘,算了,Siamese網絡的苦水等以后再倒吧,言歸正傳,開始train。 在caffe平臺下,實現用Alexn...
猜你喜歡
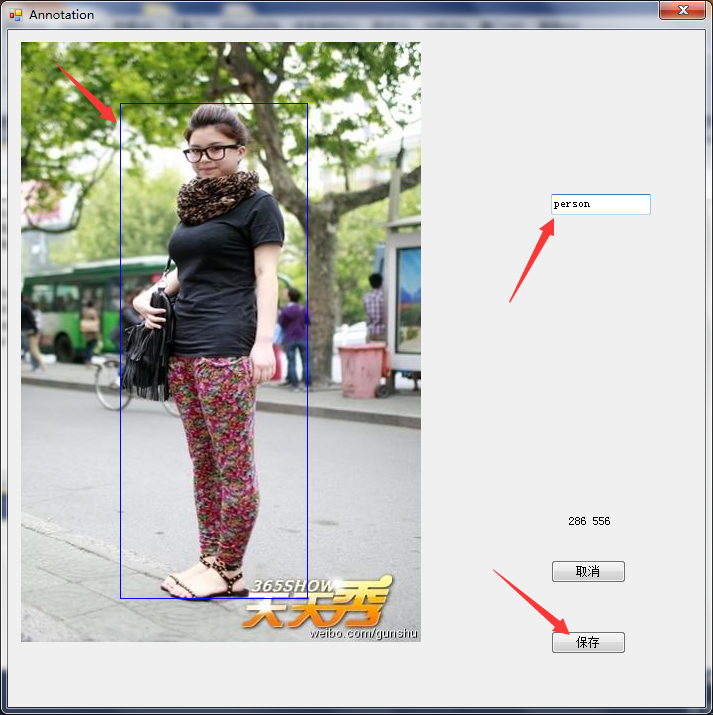
深度學習Caffe實戰筆記(19)Windows平臺 Faster-RCNN 制作自己的數據集
萬里長征第一步,就是要制作自己的數據集,過程還是比較繁瑣的,特別是標注的過程,這篇博客先介紹如果制作voc2007自己的數據集用于faster-rcnn訓練,下一篇博客介紹如何用faster-rcnn訓練自己的數據。 1、準備圖像 圖像要用.jpg或者jpeg格式的,如果是png或者其它格式,自己轉換一下就好,圖像名稱要用000001.jpg,只有和VOC2007數據集圖像名稱一致,才能最大限度的...
深度學習Caffe實戰筆記(20)Windows平臺 Faster-RCNN 訓練自己的數據集
昨天晚上博主干到12點多,終于用了一晚上時間搞定了Faster-Rcnn訓練自己的數據集,這篇博客介紹如何用faster_rcnn訓練自己的數據集,前提是已經準備好了自己的數據和配置好了faster-rcnn的環境。 制作數據集教程:http://blog.csdn.net/gybheroin/article/details/72581318 環境配置教程:http://blog.csdn.net...
深度學習Caffe實戰筆記采集數據并預處理
深度學習Caffe實戰筆記采集數據并預處理 采集數據并進行分類 針對自己的項目,將收集到的數據分為5類,并生成清單文件: 使用OpenCV 采集數據; 將拍攝的5類數據按照1:3的比例分為訓練集和測試集 ,基于python平臺腳本用來生成。 將拍攝的5類數據分別生成 list_file文件 ,基于python平臺腳本用來生成list_file文件; 標簽順序打亂 功能; 生成LMDB格式的數據集;...

深度學習caffe實戰筆記(4)Windows caffe平臺下跑cifar10
上一篇博客介紹了如何用alexnet跑自己的數據,能跑自己的數據按理說再跑cifar10應該沒問題了啊,但是想想還是要把cifar10的記錄下來,因為cifar10數據格式是屬于特殊的數據格式,需要用caffe環境把數據轉換文件編譯出來,這也是后面Siamese網絡所必須的一個步驟,說到Siamese網絡,,,,我要再哭5分鐘。好,五分鐘時間到,我們開始train。另外,如果是Ubuntu系統,跑...

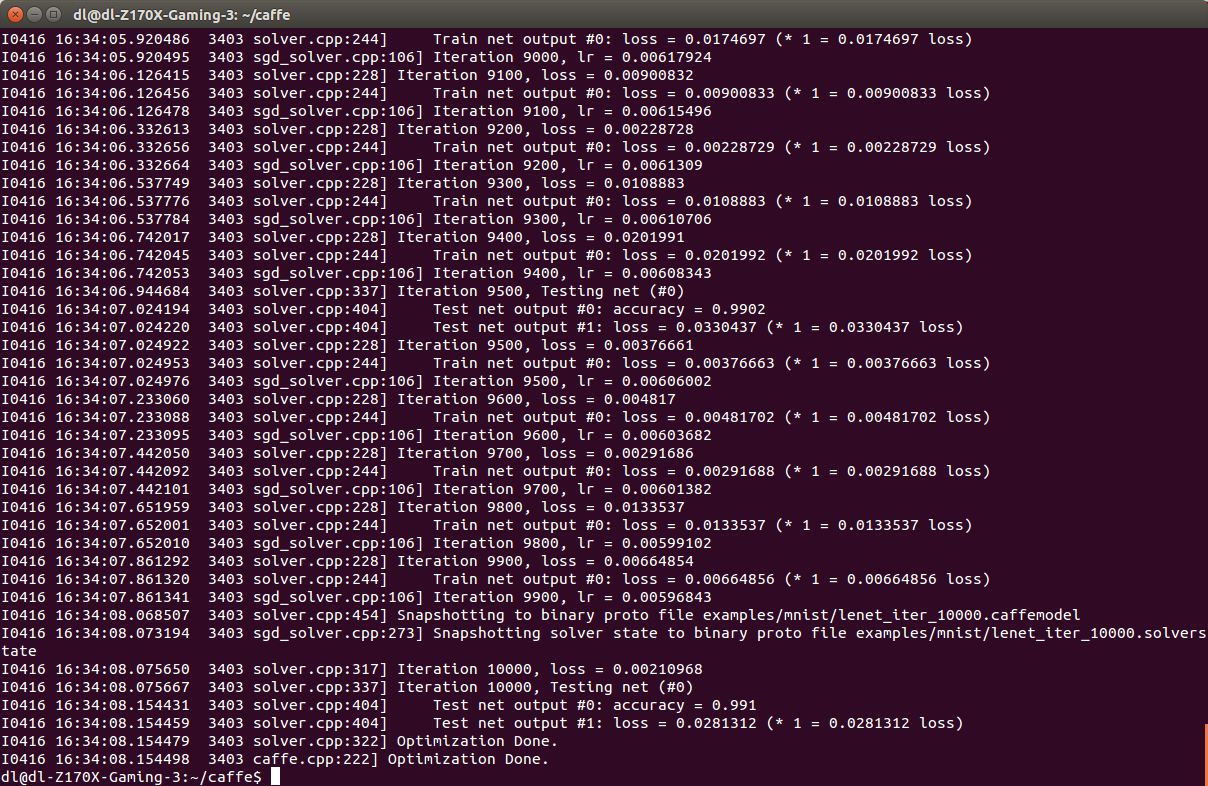
《深度學習——實戰caffe》——caffemodel可視化
通過前面的學習,我們已經能夠正常訓練各種數據了。設置好solver.prototxt后,我們可以把訓練好的模型保存起來,如lenet_iter_10000.caffemodel。訓練多少次就自動保存一下,這個是通過snapshot進行設置的,保存文件的路徑及文件名前綴是由snapshot_prefix來設定的。這個文件里面存放的就是各層的參數,即net.params,里面沒有數據(net.blob...