《深度學習——實戰caffe》——caffe模型
深度學習模型通常由三部分參數組成:
- 可學習參數(Learnable Parameter),又稱可訓練參數、神經網絡權系數、權重,其數值由模型初始化參數、誤差反向傳播過程控制,一般不可人工干預。
- 結構參數(Archetecture Parameter),包括卷積層、全連接層、下采樣層數目、卷積核數目、卷積核大小等描述網絡結構參數,一旦設定好,網絡訓練階段不能更改;值得注意的是,訓練階段的參數和預測階段的參數很可能不同。
- 訓練超參數(Hyper-Parameter),用來控制網絡訓練的收斂的參數,訓練階段可以自動的或手動調節獲得更好的效果,預測階段不需該參數。
可學習參數在內存中使用Blob對象保持,必要時以二進制ProtoBuffer文件(*.caffemodel)形態序列化并存儲于磁盤之上,便于進一步微調(funetune,又稱為精調)、共享、性能評估(benchmark)。
結構參數使用ProtoBuffer文本格式(*.prototxt)描述,網絡初始化通過該描述文件構建Net對象、Layer對象形成有向無環圖結構,在Layer和Layer之間、Net輸入源和輸出均為持有數據和中間結果的Blob對象。
訓練超參數同樣使用ProtoBuffer文本格式(*.prototxt)描述,訓練階段利用該描述文件構建求解器(Solver)對象,該對象按照一定的規則在訓練網絡時自動調節這些超參數值。
下面我們一一展開介紹。
今天我們將前面介紹的MNIST手寫識別例子中的LeNet-5模型稍加修改,變成如下圖的邏輯回歸(Logistic Regression,LR)分類器。
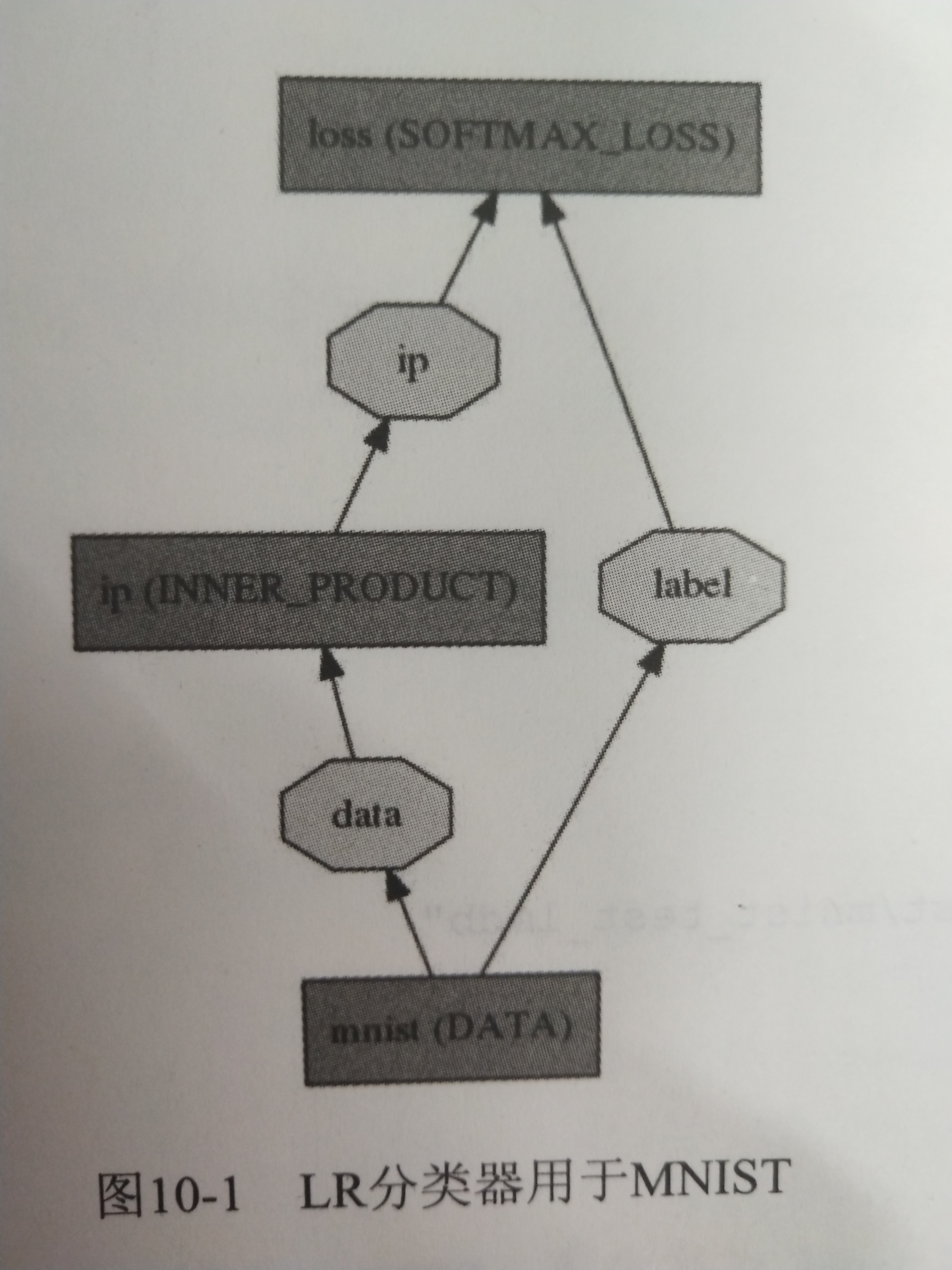
prototxt表示
復制一份examples/mnist/lenet_train_test.prototxt,重命名為lenet_lr.prototxt,修改內容如下:
name: "LeNet"
layer {
name: "mnist"
type: "Data"
top: "data"
top: "label"
include {
phase: TRAIN
}
transform_param {
scale: 0.00390625
}
data_param {
source: "examples/mnist/mnist_train_lmdb"
batch_size: 64
backend: LMDB
}
}
layer {
name: "mnist"
type: "Data"
top: "data"
top: "label"
include {
phase: TEST
}
transform_param {
scale: 0.00390625
}
data_param {
source: "examples/mnist/mnist_test_lmdb"
batch_size: 100
backend: LMDB
}
}
layer {
name: "ip"
type: "InnerProduct"
bottom: "data"
top: "ip"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
inner_product_param {
num_output: 10
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "accuracy"
type: "Accuracy"
bottom: "ip"
bottom: "label"
top: "accuracy"
include {
phase: TEST
}
}
layer {
name: "loss"
type: "SoftmaxWithLoss"
bottom: "ip"
bottom: "label"
top: "loss"
}復制一份examples/mnist/lenet_solver.prototxt,重命名為lenet_lr_solver.prototxt,修改內容如下:
# The train/test net protocol buffer definition
net: "examples/mnist/lenet_lr.prototxt"
# test_iter specifies how many forward passes the test should carry out.
# In the case of MNIST, we have test batch size 100 and 100 test iterations,
# covering the full 10,000 testing images.
test_iter: 100
# Carry out testing every 500 training iterations.
test_interval: 500
# The base learning rate, momentum and the weight decay of the network.
base_lr: 0.01
momentum: 0.9
weight_decay: 0.0005
# The learning rate policy
lr_policy: "inv"
gamma: 0.0001
power: 0.75
# Display every 100 iterations
display: 100
# The maximum number of iterations
max_iter: 10000
# snapshot intermediate results
snapshot: 5000
snapshot_prefix: "examples/mnist/lenet"
# solver mode: CPU or GPU
solver_mode: CPU運行訓練,在命令行輸入:
./build/tools/caffe train --solver=example/mnist/lenet_lr_solver.prototxt智能推薦

《深度學習——實戰caffe》——初識數據可視化
首先將caffe的根目錄作為當前目錄,然后加載caffe程序自帶的小貓圖片,并顯示。 圖片大小為360x480,三通道 打開examples/net_surgery/conv.prototxt文件,修改兩個地方 一是將input_shape由原來的是(1,1,100,100)修改為(1,3,100,100),即由單通道灰度圖變為三通道彩色圖。 二是將過濾器個數(num_output)由3修改為16...

《深度學習——實戰caffe》——caffemodel可視化
通過前面的學習,我們已經能夠正常訓練各種數據了。設置好solver.prototxt后,我們可以把訓練好的模型保存起來,如lenet_iter_10000.caffemodel。訓練多少次就自動保存一下,這個是通過snapshot進行設置的,保存文件的路徑及文件名前綴是由snapshot_prefix來設定的。這個文件里面存放的就是各層的參數,即net.params,里面沒有數據(net.blob...
深度學習Caffe實戰筆記(1)環境搭建
(1)環境搭建 從知道深度學習開始,就一直想學習使用caffe,礙于各種事情一直沒有如愿,這幾天終于找了個時間搞了一下,打算把學習的過程整理成筆記,包括環境搭建、跑車牌識別數據,跑mnist數據,用Alexnet跑自己的數據,用Siamese網絡跑mnist數據,用Siamese網絡跑自己的數據以及如何調整網絡結構等等。。。。后續我會慢慢更新,筆記的主要內容是如何使用caffe,主要側重于實戰,基...
深度學習Caffe實戰筆記(21)Windows平臺 Faster-RCNN 訓練好的模型測試數據
前一篇博客介紹了如何利用Faster-RCNN訓練自己的數據集,訓練好會得到一個模型,這篇博客介紹如何利用訓練好的模型進行測試數據。 1、訓練好的模型存放位置 訓練好的模型存放在faster_rcnn-master\output\faster_rcnn_final\faster_rcnn_VOC2007_ZF,把script_faster_rcnn_demo.m文件拷貝到faster_rcnn-m...
caffe學習——caffe安裝
一,引言 安裝環境:VMware里裝的ubuntu14.04,(由于是虛擬機,好像只能裝cpu版的caffe,反正是學習嗎,暫時不追求速度了) 二,安裝步驟 1.安裝一些依賴庫 2.安裝Python 的一些依賴庫 ATLAS是python下的一個線性代數庫,是基于線性代數庫lapack的; 安裝gfortran,后面編譯過程中會用到 BLAS,全稱Basic Linear Algebr...
猜你喜歡

caffe深度學習【十三】:Caffe的 solver 參數詳解
簡述: 相信跑過caffe框架的同學都知道 一般進行訓練,我們都需要如下幾個文件/文件夾: 1)models文件夾 就是存放訓練得到的模型,也就是保存網絡中的各種W和b的參數 2)train-SE.sh 其實就是一個腳本文件,里面寫上類似這樣的: 這樣我們就沒必要每次在終端輸入這么長的指令去執行訓練操作了,只需要進入到.sh文件所在的目錄,然后執行: 即可 3)SE-Res...
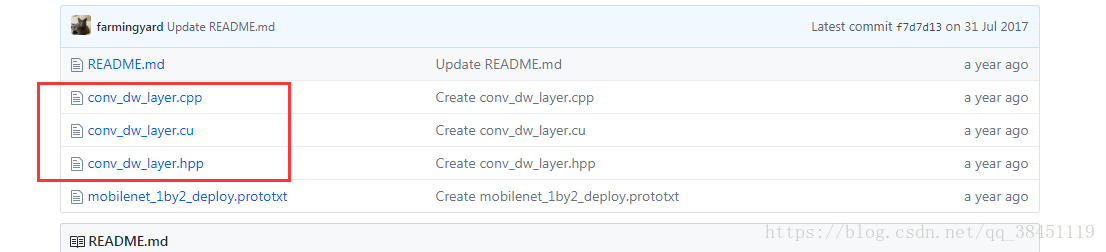
caffe深度學習【十七】配置MobileNet,caffe添加ConvolutionDepthwise層
背景: 論文入口: https://arxiv.org/abs/1704.04861 配置文件下載入口: https://github.com/farmingyard/caffe-mobilenet 在caffe版本的MobileNet 和ShuufleNet中,我們會用到ConvolutionDepthwise層,即深度可分離卷積。 Caffe原本的框架里是沒有Convolutio...
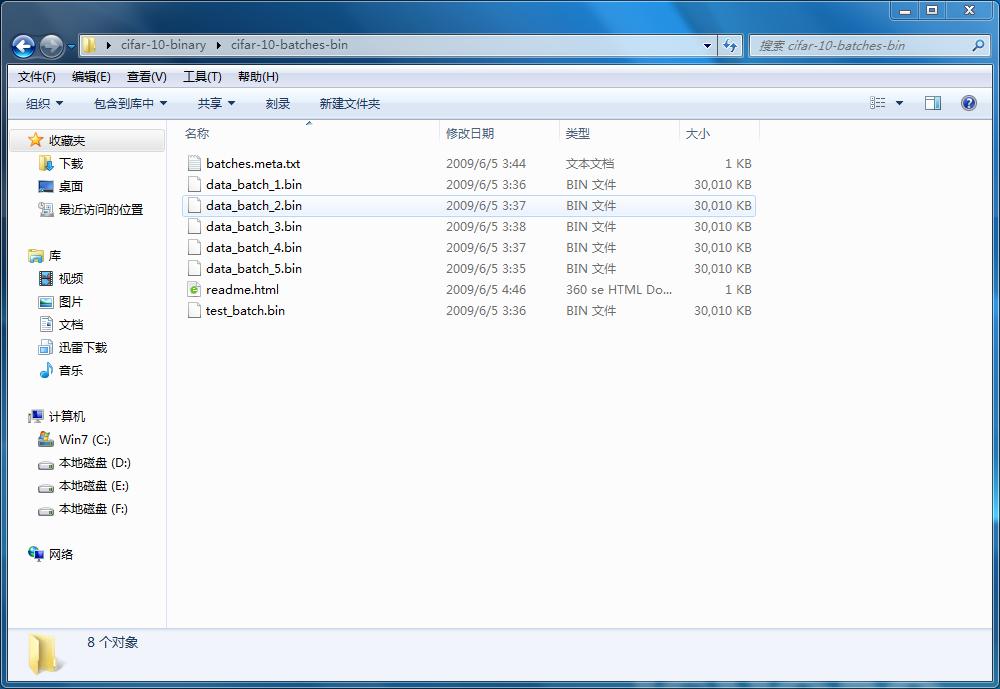
深度學習caffe(2)——caffe例程之cifar10
從看起來最好玩的cifar10開始。 1)cifar10數據集 cifar10數據集包括60000張32*32*3的圖片,這些圖片分為10類,分別是飛機、汽車、鳥、貓、狗、鹿、青蛙、馬、船、卡車。 數據集下載地址:http://www.cs.toronto.edu/~kriz/cifar.html 下載二進制文件,解壓后可以看到文件夾里有6個.bin文件,是60000張圖片,每個batch包括10...
【caffe 深度學習】2.caffe文件詳解
這篇博客主要是對上篇博客提到的文件作一個詳解。 1.MNIST數據集 下載下來的數據集被分成兩部分:60000張圖片的訓練數據集和10000張圖片的測試數據集。 每張圖片包含28*28個像素,圖片里的每個像素都是8位的,也就是說每一個像素值的強度介于0-255之間。 2.下載的原始數據集為二進...

[深度學習之caffe配置] ubuntu下配置caffe框架
平臺環境配置--筆記本電腦+雙系統的ubuntu16.04+顯卡英偉達M740 參考網站 (1)ubuntu16.04+gtx1060+cuda8.0+caffe安裝、測試經歷 http://blog.csdn.net/WoPawn/article/details/52302164 (2)Ubuntu16:cmake生成Makefile編譯caffe過程(OpenBLAS/CPU+GPU) htt...