Java中xml解析 SAX、PULL、DOM
目錄
一,什么是XML:
定義:XML指的是可擴展標記語言,主要用來傳輸和存儲數據。
XML主要語法規則:
XML標簽需要用戶自定義
XML標簽使用時要關閉<標簽名> </標簽名>成對存在
XML標簽對區分大小寫
XML標簽必須正確的嵌套
XML文檔有且只有一個根元素
XML的屬性值要加引號
XML中的空格換行符等會被當做內容讀取
更多xml的詳情:http://www.w3school.com.cn/xml/index.asp
二,XML的解析
java的中對XML的解析有多種方式,本本文主要使用SAX,拉,DOM三種解析方式。
解析的XML文件內容為:
<?xml version="1.0" encoding="utf-8" ?>
<students>
<student id="1235">
<name>小花</name>
<age>25</age>
<salary>3500</salary>
</student>
<student id="6121">
<name>王五</name>
<age>36</age>
<salary>6000</salary>
</student>
<student id="4851">
<name>里斯</name>
<age>24</age>
<salary>4000</salary>
</student>
</students>
2.1 SAX解析
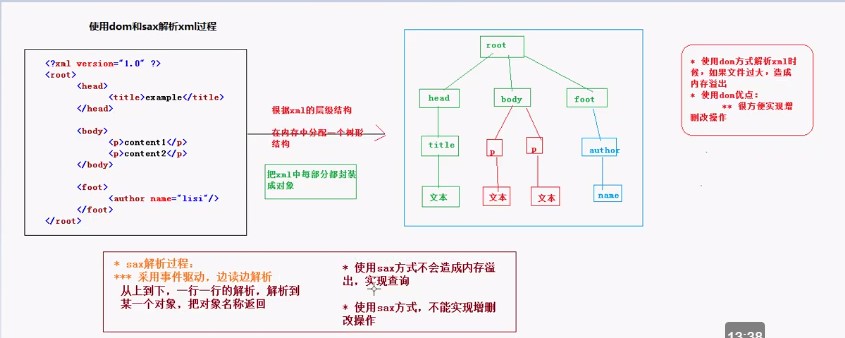
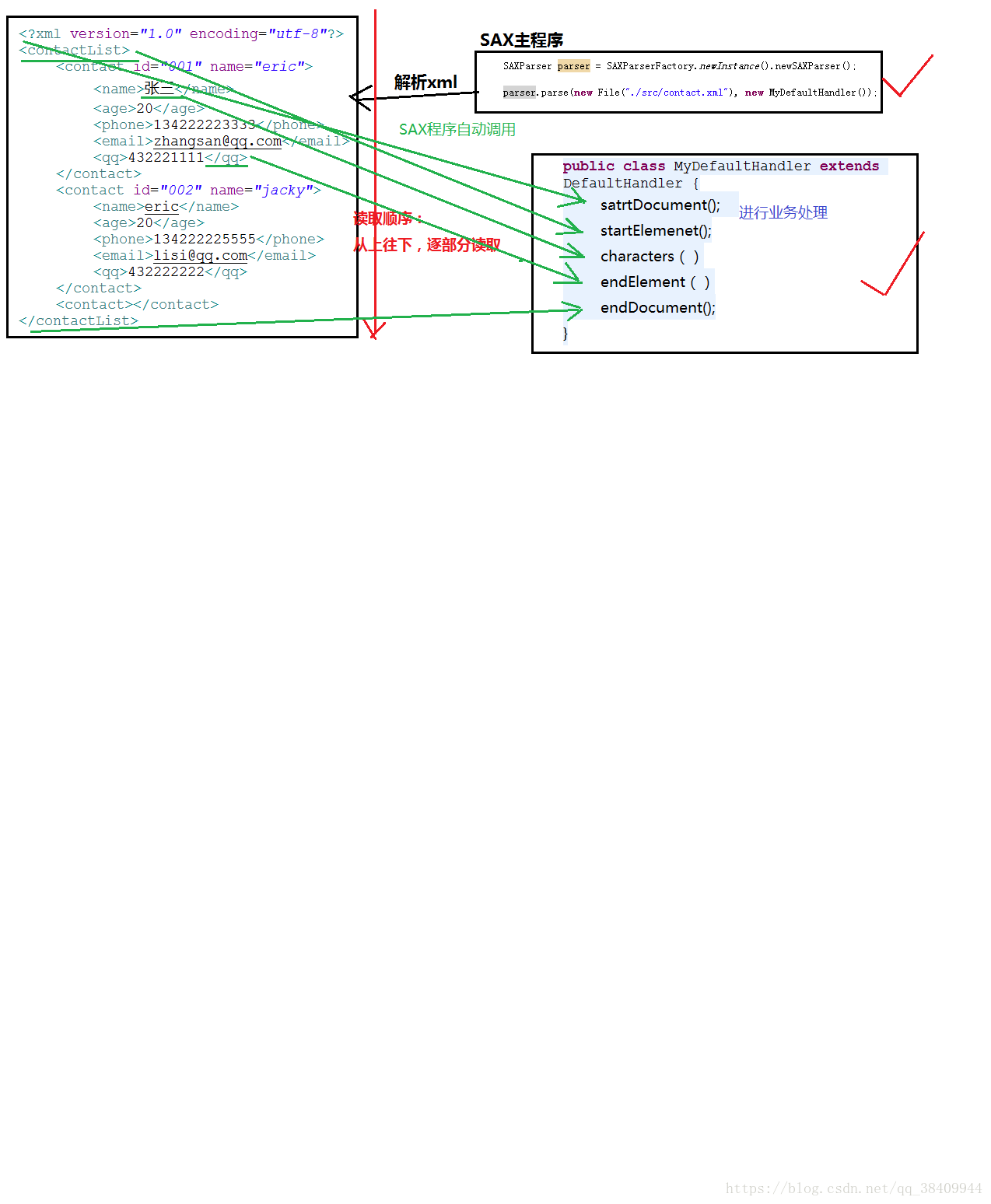
SAX解析采用事件驅動的方式進行解析,逐行讀取XML文件,并逐行解析。
public class Test {
public static void main(String[] args) throws Exception{
//創建SAX解析工廠
SAXParserFactory saxParserFactory=SAXParserFactory.newInstance();
//獲取解析器對象
SAXParser parser=saxParserFactory.newSAXParser();
//創建解析器處理對象
MyHandler myHandler=new MyHandler();
//傳入xml文件和解析器 開始解析xml
parser.parse(new File("students.xml"),myHandler);
List<Student> list=myHandler.getList();
System.out.println("------------------------");
for (Student s:list) {
System.out.println("姓名:"+s.getName()+",年齡:"+s.getAge()+",工資:"+s.getSalary());
}
}
}
public class Student {
private Integer id;
private String name;
private int age;
private int salary;
public int getSalary() {
return salary;
}
public void setSalary(int salary) {
this.salary = salary;
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
public class MyHandler extends DefaultHandler {
/***
* 將解析的內容存放到list中
*/
private List<Student> list;
/***
* 用于解析判斷
*/
private Student student;
private boolean isName;
private boolean isAge;
private boolean isSalary;
/***
* 文檔開始解析 只執行一次
*/
@Override
public void startDocument() throws SAXException {
System.out.println("xml解析開始");
list=new ArrayList<Student>();
}
/***
* 開始標簽 每次讀到一個標簽便從這個方法開始
*/
@Override
public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException {
//qName 讀到的標簽的名稱
if (qName.equals("student")){
student=new Student();//讀到student標簽 創建一個學生對象
}else if (qName.equals("name")){
isName=true;
}else if (qName.equals("age")){
isAge=true;
}else if (qName.equals("salary")){
isSalary=true;
}
}
/***
* 當讀取到標簽 標簽內有內容 遍執行此方法 獲取標簽的內容
*/
@Override
public void characters(char[] ch, int start, int length) throws SAXException {
String temp=new String(ch,start,length);
if (isName){
student.setName(temp);
isName=false;
}else if (isAge){
student.setAge(Integer.valueOf(temp));
isAge=false;
}else if (isSalary){
student.setSalary(Integer.valueOf(temp));
isSalary=false;
}
}
/***
* 每讀到一個結束的標簽 遍執行此方法
*/
@Override
public void endElement(String uri, String localName, String qName) throws SAXException {
if (qName.equals("student")){
list.add(student);//一個student 的標簽讀完 將該學生對象添加到集合中
}
}
/***
* 整個xml解析結束 只執行一次
*/
@Override
public void endDocument() throws SAXException {
System.out.println("xml文檔解析結束");
}
/***
* 獲取學生集合對象
* @return
*/
public List<Student> getList(){
return list;
}
}解析結果:

2.2 PULL解析
PULL解析與SAX解析方式相似,都是事件驅動方式。使用PULL解析需要導入的jar包。
jar包地址:https://download.csdn.net/download/sitansen/10611364
/**
* Pull解析xml
*/
public class PullTest {
static List<Student> list;
static Student student;
static String tag;//用于存放標簽
public static void main(String[] args)throws Exception{
//創建解析工廠
XmlPullParserFactory pullParserFactory=XmlPullParserFactory.newInstance();
//創建解析器對象
XmlPullParser pullParser=pullParserFactory.newPullParser();
//傳入xml文件
pullParser.setInput(new FileReader("students.xml"));
//開始解析
action(pullParser);
//獲取結果
for(Student s:list){
System.out.println("id:"+s.getId()+" ,姓名:"+s.getName()+" ,年齡:"+s.getAge()+" ,工資:"+s.getSalary());
}
}
/**
* 開始解析
* @param pullParser
* @throws Exception
*/
public static void action(XmlPullParser pullParser)throws Exception{
int eventType=pullParser.getEventType();//獲取標簽類型
while (eventType!=XmlPullParser.END_DOCUMENT){//END_DOCUMENT 用于判斷是否解析完
tag=pullParser.getName();//獲取標簽名
//解析開始
if (eventType==XmlPullParser.START_DOCUMENT){//START_DOCUMENT 文檔開始的標簽
list=new ArrayList<>();//創建一個list用于存放學生對象
}else if (eventType==XmlPullParser.START_TAG){ //開始標簽
if (tag.equals("student")){
student=new Student();
/***
* 獲取屬性id
*/
int num=pullParser.getAttributeCount();//獲取屬性的個數
for (int i=0;i<num;i++){
if (pullParser.getAttributeName(i).equals("id")){//判斷屬性名是否為id
student.setId(Integer.valueOf(pullParser.getAttributeValue(i)));
break;
}
}
}else if (tag.equals("name")){
student.setName(pullParser.nextText());//調用nextText()方法過去name標簽后的內容 以下同
}else if (tag.equals("age")){
student.setAge(Integer.valueOf(pullParser.nextText()));
}else if (tag.equals("salary")){
student.setSalary(Integer.valueOf(pullParser.nextText()));
}
}else if (eventType==XmlPullParser.END_TAG){ //student標簽結束
if (tag.equals("student")){
list.add(student);//將當前的學生對象存起來
}
}
eventType=pullParser.next();//獲取下一個標簽的類型
}
}
}
解析結果:

2.3DOM解析
DOM解析與前兩種方式不同,DOM解析采用的是將整個XML文件讀取進來,再組成一個DOM樹。根據節點與節點之間的關系來解析XML。適用于小文件的解析,大文件用DOM解析會照成資源占用過大。
/***
* 利用DOM 解析student.xml
*
*/
public class MyDomTest {
public static void main(String[] args) throws Exception{
//創建一個工廠
DocumentBuilderFactory dbf=DocumentBuilderFactory.newInstance();
//創建對象
DocumentBuilder db=dbf.newDocumentBuilder();
//加載xml文件
Document document=db.parse("students.xml");
//獲取student節點的集合
NodeList nodeList=document.getElementsByTagName("student");
System.out.println("共有學生"+nodeList.getLength()+"人");
//遍歷student節點集合
for(int i=0;i<nodeList.getLength();i++) {
System.out.println("----------第"+(i+1)+"個學生的信息----------");
//通過item方法返回集合中的第i個項
Node node=nodeList.item(i);
//獲取當前節點的屬性集合
NamedNodeMap attrs=node.getAttributes();
for(int j=0;j<attrs.getLength();j++) {
Node a=attrs.item(j);
System.out.println("屬性:"+a.getNodeName()+"\t值:"+a.getNodeValue());
}
//解析student的子節點
NodeList childNode=node.getChildNodes();
//遍歷子節點
for(int k=0;k<childNode.getLength();k++) {
if (childNode.item(k).getNodeType()==Node.ELEMENT_NODE) {
System.out.print("節點名:"+childNode.item(k).getNodeName());
System.out.print("\t值:"+childNode.item(k).getFirstChild().getNodeValue()+"\n");
}
}
}
System.out.println("解析結束");
}
}解析結果:

智能推薦

XML解析器:DOM、SAX、DOM4J
※ XML學習 W3CSchool.chm文件 W3CSchool.chm.zip ※ XML解析器 JAXP介紹(Java API for XMLProcessing) JAXP 是J2SE的一部分,它由javax.xml、org.w3c.dom 、org.xml.sax 包及其子包組成. 在 javax.xml.parsers 包中,定義了幾個工廠類,程序員調用這些工廠類,可以得到對xml文檔...
Java 解析 xml 常見的4中方式:DOM SAX JDOM DOM4J
Java 四種解析 XML 的特點 1、DOM 解析: 形成了樹結構,有助于更好的理解、掌握,且代碼容易編寫。 解析過程中,樹結構保存在內存中,方便修改。 2、SAX 解析: 采用事件驅動模式,對內存耗費比較小。 適用于只處理 XML 文件中的數據時 3、JDOM 解析: 僅使用具體類,而不使用接口。 API 大量使用了 Collections 類。 4、DOM4J 解析: JDOM 的一種智能分...
XML文檔解析技術之SAX解析與DOM解析
一、SAX解析 SAX解析xml的方式是一種快速解析xml文檔的手段,優點是效率高,適用于解析量不大的xml文檔。 使用案例: 使用sax的方式將如下的xml文檔的用戶信息解析出來。 ...
XML(三):xml的解析技術:dom和sax
1. 解析過程圖及優缺點 2.針對dom和sax的解析器 3.JAXP 使用 1)javax.xml.parsers包下有四個類: DocumentBuilder和DocumentBuilderFactory、 SaxParser和SaxParserFactory 2)步驟:...

XML介紹及DOM解析&SAX解析——學習筆記
目錄 一、XML簡介 (1)XML和HTML (2)什么是XML 二、XML元素VS節點 三、DOM方式解析XML原理 四、SAX方式解析XML原理 五、JDOM工具解析 六、DOM4J工具解析 一、XML簡介 (1)XML和HTML XML 被設計用來傳輸和存儲數據。 &nb...
猜你喜歡
XML的SAX解析以及DOM解析和SAX解析區別
前言: XML解析工具 老樣子,三個問題: SAX是什么? 也是用來解析XML的 SAX解析工具- 內置在jdk中。org.xml.sax.* SAX運用場景? SAX解析原理: 加載一點,讀取一點,處理一點。對內存要求比較低。 SAX解析工具核心: 核心的API: 參數一: File:表示 讀取的xml文件。 參數二: DefaultHandler: SAX事件處理程序。使用DefaultHan...

JAVA SAX解析XML文檔
SAX SAX(simple API for XML)是一種XML解析的方法,相比于DOM,SAX的解析更有效更快。 解析步驟 ①獲取解析工廠 ②從解析工廠獲取解析容器 ③編寫處理器 ④加載Document處理器 ⑤進行解析 詳細步驟 ①此解析模式使用了工廠設計模式,所以先需獲取工廠 工廠全路徑為:javax.xml.parsers.SAXParserFactory 另外還使用了單例設計模式,所以...
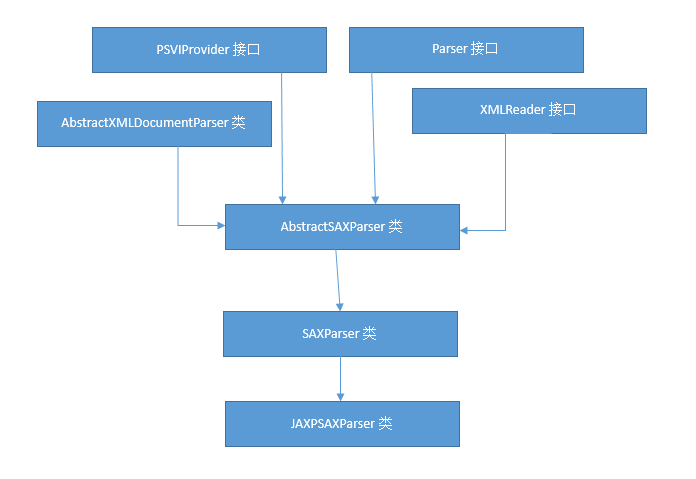
java解析xml(sax方式)
SAX的方式,大致步驟: 以下為查看相關所關聯的class: 在SAXParserImpl中的 1、 先調用父類SAXParser的parse(String uri, DefaultHandler dh) 它的邏輯代碼: 2、 再執行父類的 parse(InputSource is, DefaultHandler dh) 邏輯代碼為: XMLReader reader = JAXPSAXParse...


freemarker + ItextRender 根據模板生成PDF文件
1. 制作模板 2. 獲取模板,并將所獲取的數據加載生成html文件 2. 生成PDF文件 其中由兩個地方需要注意,都是關于獲取文件路徑的問題,由于項目部署的時候是打包成jar包形式,所以在開發過程中時直接安照傳統的獲取方法沒有一點文件,但是當打包后部署,總是出錯。于是參考網上文章,先將文件讀出來到項目的臨時目錄下,然后再按正常方式加載該臨時文件; 還有一個問題至今沒有解決,就是關于生成PDF文件...