Python學習筆記之——列表, 元組
標簽: Python列表
目錄
列表
列表推導
列表推導,創建列表的快捷方式, list comprehension , listcomps
生成器表達式( generator expression) 則稱為 genexps
for 循環
>>> symbols = '$¢£¥€¤'
>>> codes = []
>>> for symbol in symbols:
... codes.append(ord(symbol))
...
>>> codes
[36, 194, 162, 194, 163, 194, 165, 226, 130, 172, 194, 164]
>>> symbol
'\xa4'
列表推導
>>> codes = [ord(symbol) for symbol in symbols]
>>> codes
[36, 194, 162, 194, 163, 194, 165, 226, 130, 172, 194, 164]
>>> symbol
'\xa4'
列表推導濫用
links = [
{
"url": url,
"method": "GET",
"postdata": '',
"header": {
"Cookie": cookies
}
}
for url in urls if url not in filtered_urls
]
通常原則: 只用列表推導建立新的列表,并且盡量保持簡短。
變量泄漏
for循環進行的時候,如果有變量名與for中臨時變量名相同,for循環執行的時候會覆蓋原有值。
python2 存在, python3 已解決
# python2
>>> word = "hello"
>>> words = [word for word in "Hello World!"]
>>> words
['H', 'e', 'l', 'l', 'o', ' ', 'W', 'o', 'r', 'l', 'd', '!']
>>> word
'!'
# python3
>>> word = "hello"
>>> words = [word for word in "Hello World!"]
>>> words
['H', 'e', 'l', 'l', 'o', ' ', 'W', 'o', 'r', 'l', 'd', '!']
>>> word
'hello'
列表推導快于for循環 https://github.com/fluentpython/example-code/blob/master/02-array-seq/listcomp_speed.py
列表推導與笛卡爾積
背景:假如需要一個列表,列表里是3種不同尺寸的T恤,每個尺寸有2個顏色(列表推導+循環嵌套):
>>> colors = ["black", "white"]
>>> sizes = ["S", "M", "L"]
# 先以顏色排序,后以尺寸排序
>>> tshirts = [(color, size) for color in colors for size in sizes]
>>> tshirts
[('black', 'S'), ('black', 'M'), ('black', 'L'), ('white', 'S'), ('white', 'M'), ('white', 'L')]
# 先以尺寸排序,后以顏色排序
>>> tshirts = [(size, color) for size in sizes for color in colors]
>>> tshirts
[('S', 'black'), ('S', 'white'), ('M', 'black'), ('M', 'white'), ('L', 'black'), ('L', 'white')]
生成器表達式
與列表推導一次性生成整個列表不同,生成器表達式可以逐個地產出元素,相對節省內存;
>>> symbols = '$¢£¥€¤'
# 如果生成器表達式是一個函數調用過程中為唯一參數,則不需要額外括號
>>> tuple(ord(symbol) for symbol in symbols)
(36, 162, 163, 165, 8364, 164)
>>> import array
# 兩個參數,需要括號
>>> array.array("I", (ord(symbol) for symbol in symbols))
array('I', [36, 162, 163, 165, 8364, 164])
使用生成器表達式計算笛卡爾積
生成器表達式只有在迭代時才會生成元素, 如在for循環中,只有for循環執行時才會生成元素;
未迭代時,只是一個生成器對象,不會生成元素;
>>> colors = ["black", "white"]
>>> sizes = ["S", "M", "L"]
# 生成器表達式會在每次for循環運行時才生成組合
>>> for tshirt in ((color, size) for color in colors for size in sizes):
... print(tshirt)
...
('black', 'S')
('black', 'M')
('black', 'L')
('white', 'S')
('white', 'M')
('white', 'L')
# 如果不迭代,就是一個生成器對象
>>> ((color, size) for color in colors for size in sizes)
<generator object <genexpr> at 0x10fbdab40>
生成器表達式 VS 生成器函數
顧名思義,一個是表達式,一個是函數,殊途同歸,都是產生了一個生成器對象。
>>> def gen():
... for size in sizes:
... for color in colors:
... yield (size, color)
...
# 生成器函數本身就是一個函數
>>> gen
<function gen at 0x10fbd1c08>
# 生成器函數返回一個生成器
>>> gen()
<generator object gen at 0x10fbdab40>
# 迭代生成器產出元素
>>> for item in gen():
... print(item)
...
('S', 'black')
('S', 'white')
('M', 'black')
('M', 'white')
('L', 'black')
('L', 'white')
元組
元組不僅僅是不可變列表
除了用作不可變列表之外,還可以用于沒有字段名的記錄。 有字段名的記錄——collections.nametuple。
元組其實是對數據的記錄:元組中的每個元素都包含了位置與數據共兩個信息。
排序后的元組也就丟失了位置信息,失去了數據的意義。
>>> request = ("GET", "https://www.baidu.com", headers, data)
>>> request2 = ("POST", "http://example.com", headers, data)
# 位置和值是元組的主要信息
>>> method, url, header, data = request
>>> print("method: %s, url: %s" % (method, url))
method: GET, url: https://www.baidu.com
# 排序后失去原有記錄意義
>>> sorted(request)
['', '', 'GET', 'https://www.baidu.com']
元組拆包
元組拆包可以應用到任何可迭代對象上,唯一的硬性要求是被可迭代對象中的元素個數必須要跟接受這些元素的元組的空檔數一致。 除非用星號* 標識多余元素(python3)。
示例
# 字符串格式化, 元組拆包
>>> print("name: %s, value: %s" % ("country", "china"))
name: country, value: china
# 平行賦值
>>> a, b = "a", "b"
>>> a
'a'
>>> b
'b'
>>> a, b
('a', 'b')
# 交換值
>>> a, b = b, a
>>> a, b
('b', 'a')
# 用占位符 _ 填充位置
>>> import os
>>> _, filename = os.path.split("/usr/bin/passwd")
>>> filename
'passwd'
# python3
>>> divmod(20, 8)
(2, 4)
>>> t = (20, 8)
>>> divmod(*t)
(2, 4)
用*處理剩下的元素
在Python中,函數用*args來獲取不確定數量的參數算是一種經典寫法了。
Python3中,這個概念被用于平行賦值中:
>>> a, b, *rest = range(5)
>>> a, b, rest
(0, 1, [2, 3, 4])
>>> a, b, *rest = range(3)
>>> a, b, rest
(0, 1, [2])
>>> a, b, *rest = range(2)
>>> a, b, rest
(0, 1, [])在平行賦值中, *前綴只能用在一個變量前面,但是可以放在賦值表達式中的任意位置:
# 只能出現一次
>>> a, *body, c *rest = range(5)
File "<stdin>", line 1
SyntaxError: can't assign to operator
# 其余任意位置
>>> a, *body, c = range(5)
>>> a, body, c
(0, [1, 2, 3], 4)
>>> *head, c, d, e = range(5)
>>> head, c, d, e
([0, 1], 2, 3, 4)嵌套元組拆包
接受表達式的元組可以是嵌套式的, 例如 (a, b, (c, d))。 只要這個接受元組的嵌套結構符合表達式本身的嵌套結構, Python 就可以作出正確的響應。
>>> info = ("Xin yuan shuai", 34, "male", (1984, 1, 8))
>>> name, age, gender, (year, month, date) = info
>>> name, age, gender, year, month, date
('Xin yuan shuai', 34, 'male', 1984, 1, 8)
# 表達式左右格式必須是對應的
>>> name, age, gender, year, month, date = info
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: not enough values to unpack (expected 6, got 4)
具名元組
collections.namedtuple 是一個工廠函數, 它可以用來構建一個帶字段名的元組和一個有名字的類——這個帶名字的類對調試程序有很大幫助。
用 namedtuple 構建的類的實例所消耗的內存跟元組是一樣的, 因為字段名都被存在對應的類里面。 這個實例跟普通的對象實例比起來也要小一些, 因為 Python 不會用 __dict__ 來存放這些實例的屬性。
>>> import collections
# 創建一個具名元組需要兩個參數, 一個是類名, 另一個是類的各個字段的名字。
# 后者可以是由數個字符串組成的可迭代對象, 或者是由空格分隔開的字段名組成的字符串。
>>> Student = collections.namedtuple("Student", ["name", "age", "gender", "birth", "address"])
# 存放在對應字段里的數據要以一串參數的形式傳入到構造函數中
# 注意, 元組的構造函數卻只接受單一的可迭代對象
>>> jack = Student("Jack", 22, "male", 1996, ("Beijing", "chaoyang"))
>>> jack
Student(name='Jack', age=22, gender='male', birth=1996, address=('Beijing', 'chaoyang'))
# 可以通過字段名或者位置來獲取一個字段的信息
>>> jack.name
'Jack'
>>> jack.address
('Beijing', 'chaoyang')
>>> jack[4][1]
'chaoyang'
除了從普通元組那里繼承來的屬性之外, 具名元組還有一些自己專有的屬性。 如: _fields 類屬性、 類方法_make(iterable) 和實例方法 _asdict()。
>>> Address = collections.namedtuple("Address", ("city area"))
>>> lucy_addr = Address("Beijing", "Haidian")
>>> lucy_data = ("Lucy", 23, "female", 1998, lucy_addr)
>>> lucy = Student._make(lucy_data)
>>> lucy._asdict()
OrderedDict([('name', 'Lucy'), ('age', 23), ('gender', 'female'), ('birth', 1998), ('address', Address(city='Beijing', area='Haidian'))])
>>> lucy
student(name='Lucy', age=23, gender='female', birth=1998, address=Address(city='Beijing', area='Haidian'))
>>> for key, value in lucy._asdict().items():
... print key + ":", value
...
name: Lucy
age: 23
gender: female
birth: 1998
address: Address(city='Beijing', area='Haidian')
>>> lucy = Student(*lucy_data)
>>> lucy
student(name='Lucy', age=23, gender='female', birth=1998, address=Address(city='Beijing', area='Haidian'))
- _fields 屬性是一個包含這個類所有字段名稱的元組。
- 用 _make() 通過接受一個可迭代對象來生成這個類的一個實例, 它的作用跟 Student(*lucy_data) 是一樣的。
- _asdict() 把具名元組以 collections.OrderedDict 的形式返回, 我們可以利用它來把元組里的信息友好地呈現出來。
不可變的元組如果含有可變對象呢?
《流暢的Python》 里有個示例,如下
>>> t = (1, 2, [3, 4])
>>> id(t), id(t[2])
(4456817920, 4457204840)
>>> t[2] += [5, 6]猜猜 t 會不會變化? 請自行嘗試查看
# 會不會變化?
>>> t
>>> id(t), id(t[2])
為什么呢?
# 二者等價
>>> t[2] += [5, 6]
>>> t[2] = t[2] + [5, 6]兩個表達式是等價的,兩個列表相加不是在前一個列表的基礎之上原地相加而是生成了一個新的列表.
等式右邊是兩個列表相加,生成了一個新的列表,也就是新的列表的引用,賦值給了t[2], 而元組是不可變的,于是就既發出了異常,又增加成功。先計算增加,成功了,再計算賦值操作,失敗。
如果元組里有可變對象,在更新變對象時建議使用自增運算
>>> t[2].append(7)Python可視化 http://www.pythontutor.com/visualize.html
STEP 1

STEP2


不要把可變對象放在元組里面。
增量賦值不是一個原子操作。 我們剛才也看到了, 它雖然拋出了異常, 但還是完成了操作。
列表濫用——當列表不是首選時
tuple, nametuple, dqueue, set
智能推薦

Python列表和元組
Python文章為基礎篇,主要提供給基礎生查看資料學習使用!本博主的主要方向為網絡安全,講解黑客技術。后期在制作黑客工具時,會用到Python這門語言。所以,在此提供一些基礎的Python知識! 你應該知道,Python這門語言沒有條條框框,直接就是數據結構與算法。最重要的,Python中你要掌握數據結構:以某種方式組合起來的數據元素集合。在Python中,最基本的數據結構就是序列。 列表和元組的...
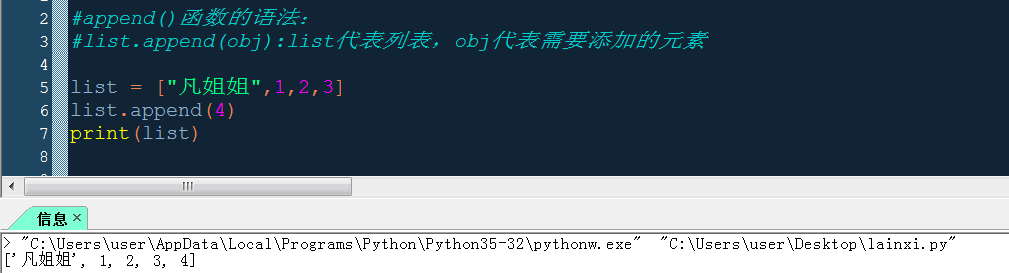
python:列表、元組
什么是列表: 列表就是用中括號括起來的一堆數據,數據之間用逗號隔開 如:list = ["凡姐姐",1,[1,2],(4,7)]。改列表中的元素包括了字符串、整數、列表、元組 生成一個列表: 1、使用list( )函數:這種方法生成的列表是:將目的序列中的每個元素都當成列表中的元素,而不是當做一個元素 2、直接寫: 更新列表: 1、元素賦值通過索引來改變列表中的特定元素。若索引...

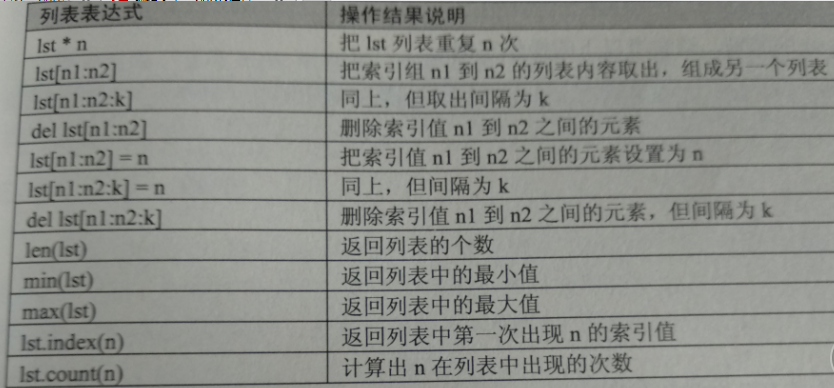
python 列表與元組
2.6以后的版本及3.X print ("*****************") Python 3.0 改進的地方: https://docs,python.org/3/whatsnew/3.0.html或https://www.python.org python 語言支持的。。。。 : https://en.wikipedia...

python列表與元組
一列表可變數據類型 列表的定義 列表的特性 列表的方法 1增加 2 刪除 4 修改直接根據索引進行修改 5查看列表信息 6 排序 7 內置方法 二元組 元組的定義 元組的特性 元組的方法 一、列表(可變數據類型) 1. 列表的定義 1 列表是打了激素的數組,數組只能存儲同種類型的數據,而列表像一個倉庫,存儲不同類型的數據. 2 序列是Python中最基本的數據結構。序列中的每個元素都分配一個數字 ...
猜你喜歡
Python三(列表&元組)
一、列表(可變數據類型) 1.列表的定義 2.列表的特性 3. 列表的方法 4. 列表的實戰 測試結果: 測試結果: 二、 元組(不可變數據類型) 1. 元組的定義: 通過type可以查看數據類型 2. 元組的特性 3. 元組的方法 二、試一試 (2017-網易-筆試編程題)-字符串練習 題目描述: 小易喜歡的單詞具有以下特性: 1.單詞每個字母都是大寫字母 2.單詞沒有連續相等的字母 3.單詞沒...
python列表與元組
列表可變數據類型 1列表的定義 2列表的特性 3列表的方法 a增加 b 刪除 c修改直接根據索引進行修改 l0value l01value d查看列表信息 e排序 f內置方法 元組不可變數據類型 元組的定義 元組的特性 元組的方法 練習 2017-網易-筆試編程題-字符串練習 2017-騰訊-在線編程題 2017-好未來-筆試編程題列表練習 2017-好未來-在線編程題 2017-去哪兒網-在線編...
Python——列表和元組
文章目錄 列表和元組 1. 序列 2. 列表:打了激素的數組 1)列表的創建與刪除 2)列表的添加 3)列表的修改 4)列表的查看 5)列表的刪除 3. 列表總結 4.元組(帶了緊箍咒的列表) 1)元組的創建,刪除及特性 特性: 注意: 2)多元賦值機制 3)環境變量交換 5.命名元組 1)用法簡介 2)定義命名元組類與應用 3)命名元組的屬性 補充: is和==的區別 補充: 深拷貝和淺拷貝 列...


freemarker + ItextRender 根據模板生成PDF文件
1. 制作模板 2. 獲取模板,并將所獲取的數據加載生成html文件 2. 生成PDF文件 其中由兩個地方需要注意,都是關于獲取文件路徑的問題,由于項目部署的時候是打包成jar包形式,所以在開發過程中時直接安照傳統的獲取方法沒有一點文件,但是當打包后部署,總是出錯。于是參考網上文章,先將文件讀出來到項目的臨時目錄下,然后再按正常方式加載該臨時文件; 還有一個問題至今沒有解決,就是關于生成PDF文件...