DC學院爬蟲學習筆記(一):什么是爬蟲?
在DC學院買的第一門課程——數據分析,終于搞定了!
今天是大年初六了,跟高中同學聚了一下,再過幾天就要回學校了(ノへ ̄、)
感覺爬蟲這塊知識還欠缺,一咬牙,也買下了爬蟲的課,老樣子,主要是記錄下老師每節課的筆記,如果有代碼要運行,補充一些。
OK,開始爬蟲之旅!
爬蟲的定義:
網絡爬蟲(又被稱為網頁蜘蛛,網絡機器人,在FOAF社區中間,更經常的稱為網頁追逐者),是一種按照一定的規則,自動地抓取萬維網信息的程序或者腳本。
爬蟲有什么用:
市場分析:電商分析、商圈分析、一二級市場分析等
市場監控:電商、新聞、房源監控等
商機發現:招投標情報發現、客戶資料發掘、企業客戶發現等
認識網址的構成
一個網站的網址一般由域名+自己編寫的頁面所構成。我們在訪問同一網站的網頁時,域名一般是不會改變的,因此我們爬蟲所需要解析的就是網站自己所編寫的不同頁面的入口url,只有解析出來各個頁面的入口,我們才能開始我們的爬蟲。
了解網頁的兩種加載方法
- 同步加載:改變網址上的某些參數會導致網頁發生改變,例如:www.itjuzi.com/company?page=1(改變page=后面的數字,網頁會發生改變)
- 異步加載:改變網址上的參數不會使網頁發生改變,例如:www.lagou.com/gongsi/(翻頁后網址不會發生變化)
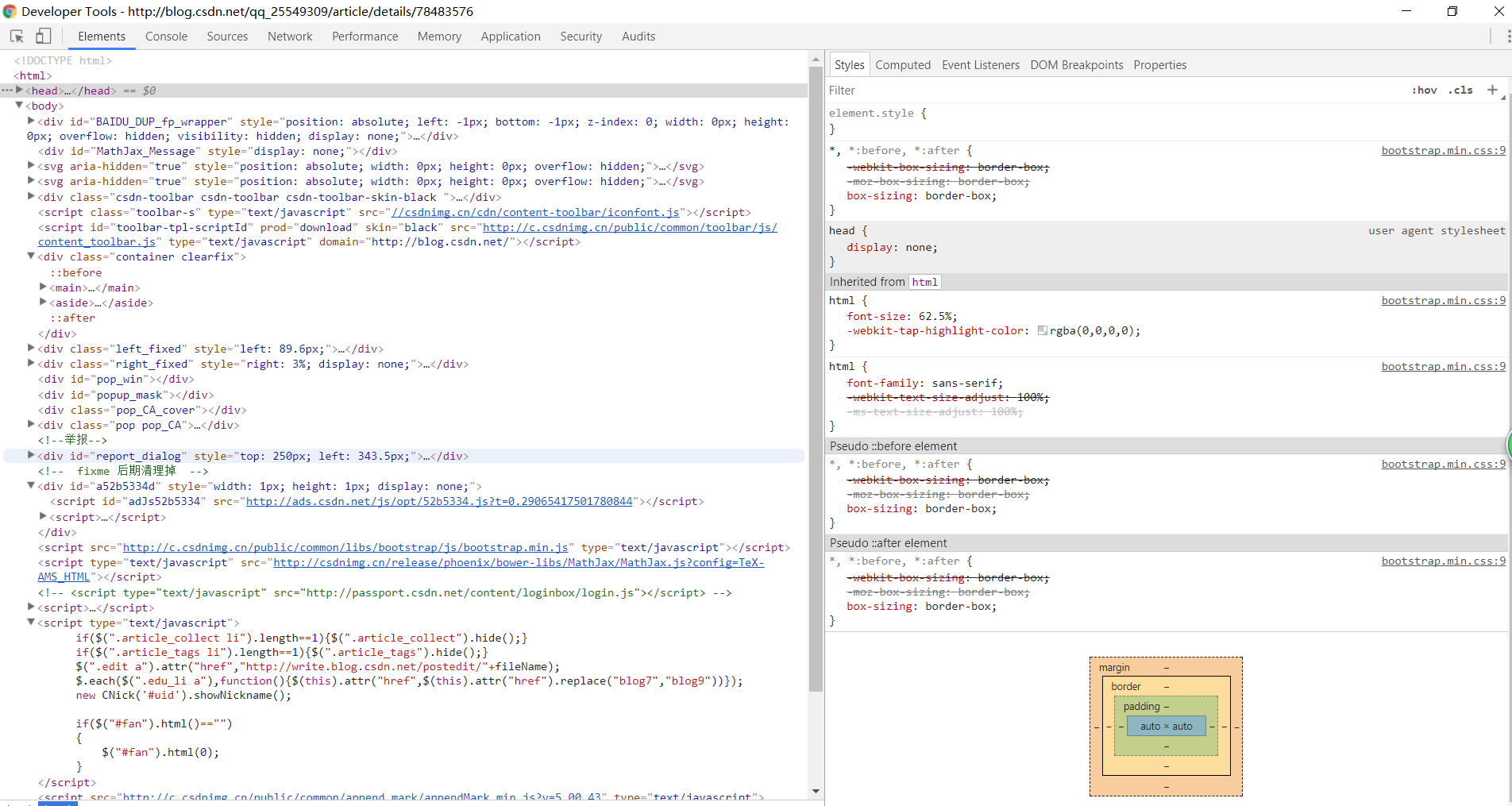
認識網頁源碼的構成
在網頁中右鍵點擊查看網頁源碼,可以查看到網頁的源代碼信息。
源代碼一般由三個部分組成,分別是:
- html:描述網頁的內容結構
- css:描述網頁的排版布局
- JavaScript:描述網頁的事件處理,即鼠標或鍵盤在網頁元素上的動作后的程序
查看網頁請求
以chrome瀏覽器為例,在網頁上點擊鼠標右鍵,檢查(或者直接F12),選擇network,刷新頁面,選擇ALL下面的第一個鏈接,這樣就可以看到網頁的各種請求信息。
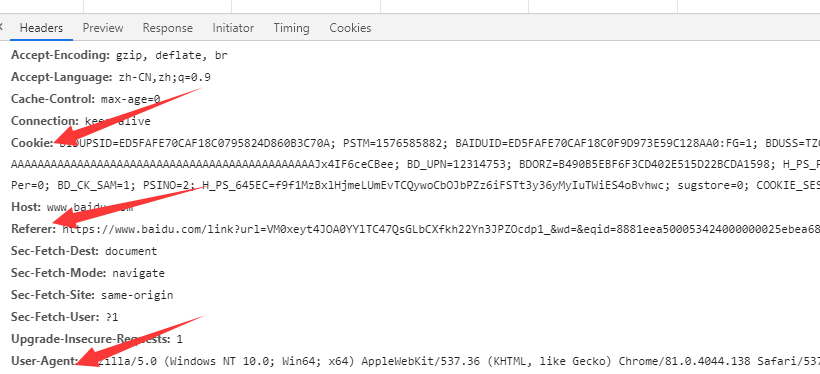
請求頭(Request Headers)信息詳解:
Accept: text/html,image/*(瀏覽器可以接收的類型)
Accept-Charset: ISO-8859-1(瀏覽器可以接收的編碼類型)
Accept-Encoding: gzip,compress(瀏覽器可以接收壓縮編碼類型)
Accept-Language: en-us,zh-cn(瀏覽器可以接收的語言和國家類型)
Host: www.it315.org:80(瀏覽器請求的主機和端口)
If-Modified-Since: Tue, 11 Jul 2000 18:23:51 GMT(某個頁面緩存時間)
Referer: http://www.it315.org/index.jsp(請求來自于哪個頁面)
User-Agent: Mozilla/4.0 (compatible; MSIE 5.5; Windows NT 5.0)(瀏覽器相關信息)
Cookie:(瀏覽器暫存服務器發送的信息)
Connection: close(1.0)/Keep-Alive(1.1)(HTTP請求的版本的特點)
Date: Tue, 11 Jul 2000 18:23:51 GMT(請求網站的時間)響應頭(Response Headers)信息詳解:
Location: http://www.it315.org/index.jsp(控制瀏覽器顯示哪個頁面)
Server:apache tomcat(服務器的類型)
Content-Encoding: gzip(服務器發送的壓縮編碼方式)
Content-Length: 80(服務器發送顯示的字節碼長度)
Content-Language: zh-cn(服務器發送內容的語言和國家名)
Content-Type: image/jpeg; charset=UTF-8(服務器發送內容的類型和編碼類型)
Last-Modified: Tue, 11 Jul 2000 18:23:51 GMT(服務器最后一次修改的時間)
Refresh: 1;url=http://www.it315.org(控制瀏覽器1秒鐘后轉發URL所指向的頁面)
Content-Disposition: attachment; filename=aaa.jpg(服務器控制瀏覽器發下載方式打開文件)
Transfer-Encoding: chunked(服務器分塊傳遞數據到客戶端)
Set-Cookie:SS=Q0=5Lb_nQ; path=/search(服務器發送Cookie相關的信息)
Expires: -1(服務器控制瀏覽器不要緩存網頁,默認是緩存)
Cache-Control: no-cache(服務器控制瀏覽器不要緩存網頁)
Pragma: no-cache(服務器控制瀏覽器不要緩存網頁)
Connection: close/Keep-Alive(HTTP請求的版本的特點)
Date: Tue, 11 Jul 2000 18:23:51 GMT(響應網站的時間)理解網頁請求過程
從瀏覽器輸入網址、回車后,到用戶看到網頁內容,經過的步驟如下:
(1)dns解析,獲取ip地址;
(2)建立TCP連接,3次握手;
(3)發送HTTP請求報文;
(4)服務器接收請求并作處理;
(5)服務器發送HTTP響應報文;
(6)斷開TCP連接,4次握手。

通用的網絡爬蟲框架
1.挑選種子URL;
2.將這些URL放入待抓取的URL隊列;
3.取出待抓取的URL,下載并存儲進已下載網頁庫中。此外,將這些URL放入待抓取URL隊列,從而進入下一循環;
4.分析已抓取隊列中的URL,并且將URL放入待抓取URL隊列,從而進入下一循環。
最后,知乎上有一個利用爬蟲技術能做到哪些很酷很有趣很有用的事情?
智能推薦
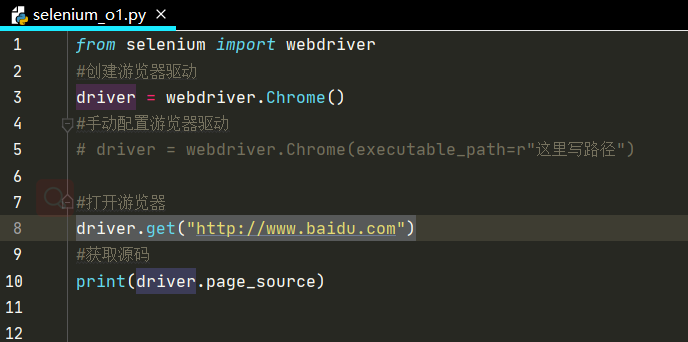
什么是爬蟲--Scrapy框架
Scrapy 框架 Scrapy架構圖 [外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-EfU6FzAA-1600343300560)(scrapy數據流向.png)] scrapy框架包含以下幾個部分 Scrapy Engine 引擎 Spiders 爬蟲 Scheduler 調度器 Downloader 下載器 Item Pipeline 項目管道 Downloa...
我是一只小小爬蟲(Python編程)--第1節 什么是爬蟲
一、爬蟲的基本概念 爬蟲:一只在網絡上爬行的“蜘蛛”,這只蜘蛛用來在網絡上爬取我們想獲取的信息,所以爬蟲的定義大概是: 請求網站并提取數據的自動化程序。 從定義中可以看出,我們首先要做的是向網站發送請求,模擬瀏覽器瀏覽網頁的模式,從而獲取數據,此時獲取的數據其實是html代碼文本以及圖片等,接下來就是篩選我們需要的數據,梳理好我們需要的數據之后,就是要分類,按需存儲我們的想...

Python爬蟲學習筆記(一)
Python基礎知識 Python學習爬蟲相對來說灰常的簡單,很容易上手,這篇文章中記錄我一些學習中的一些收獲以供自己復習,本文以唐松老師的《Python網絡爬蟲從入門到實踐》為學習材料, 編寫我的第一個爬蟲 基礎知識回顧 python基本知識與基本語句 python通過縮進識別代碼塊,一般通過Tab鍵縮進,與C++和java中的{}相區別,語言所有類型都是對象。 基本結構。 和其他高級語言沒什么...
Python爬蟲學習筆記(一)
Python爬蟲學習筆記(一) 最近在學python爬蟲,順便把一些學習記錄記下來,可能還有些表述不到位的地方,所以請大家指正下,一起學習,一起進步吧。嗯,這次是一個比較簡單的案例,也就10行代碼左右,爬取網絡源代碼,用到了requests庫,如果沒有安裝的可以用下面的命令安裝一下: 先把源代碼附上,然后我們再慢慢解說了。 這里是基礎案例,以百度為例,所以就沒有添加headers里面的信息,后面會...

Python爬蟲 學習筆記(一)
問題 訪問國防科技大學招生網http://www.gotonudt.cn/site/gfkdbkzsxxw/lqfs/index.html,爬取各省市歷年分數線信息。 步驟 1.引入 2.捕獲網頁源代碼 這樣如果輸出data便會得到如下信息: 3.獲取所有表格信息 表格對應如下: 4.預處理 對應下表: 5.數據分析 輸出結果如下: &nbs...
猜你喜歡
DC學院學習筆記(十一):數據預處理—數據清理
終于到了數據存儲與預處理的最后一講了,感覺講得還不錯!下面來看看數據的預處理吧! 格式轉換 缺失數據 異常數據 數據標準化操作 準備知識 Pandas Pandas逐漸成為了一個非常大的庫,在數據處理問題方面表現優秀,是一個不可或缺的工具,Pandas中包含兩個主要的數據結構:Series & DataFrame 更多請看: 官方文檔 Pandas速查手冊中文版 Seaborn Seabo...
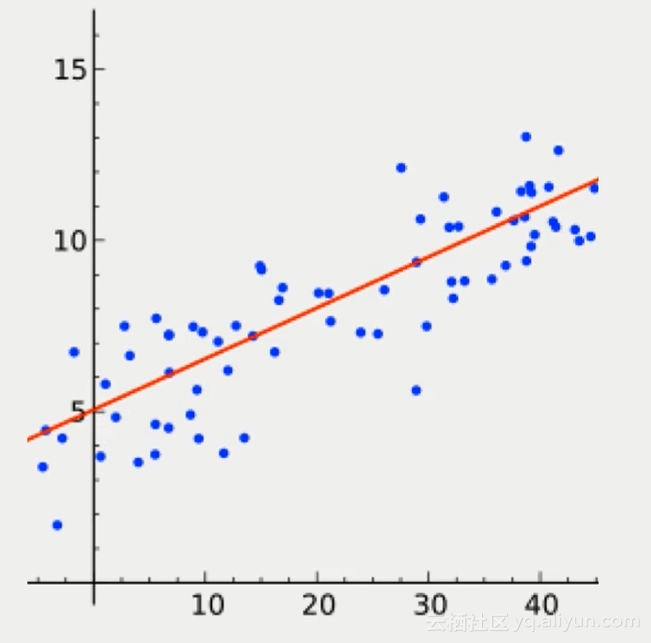
DC學院學習筆記(十六):線性回歸實戰
預測型數據分析:線性回歸 回歸:預測數值型變量 分類:預測樣本所屬類別 聚類:在未知樣本類別的情況下,根據樣本之間的相似性把樣本分成不同的類別 適用:用于股價、房價、空氣質量等數值型變量的預測 數學模型:分析兩組變量之間的關系 x:自變量(Independent variable) y:應變量(Dependent variable) 如圖是一個線性回歸的示意圖 通過x來預測y,函數:f(x) = ...
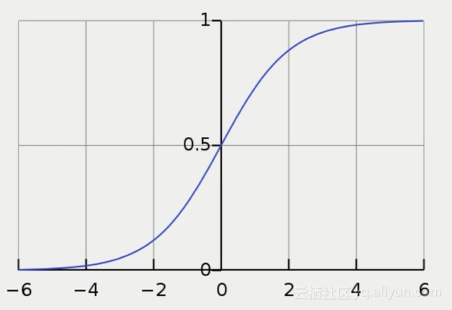
DC學院學習筆記(十七):分類及邏輯回歸
回歸和分類的區別 分類:對離散型變量進行預測(二分類、多分類) 回歸:對數值型變量進行預測 區別:回歸的y為數值連續型變量;分類的y是類別離散型變量 分類問題 1. 分類問題示例:信用卡 從x1:職業,x2:收入等等信用卡申請人不同的信息維度,來判斷y:是否發放信用卡,發放哪一類信用卡 2. 分類經典方法:logistic回歸(二分類) 雖然名字里有回歸二字,但logistic回歸解決的是分類的問...


freemarker + ItextRender 根據模板生成PDF文件
1. 制作模板 2. 獲取模板,并將所獲取的數據加載生成html文件 2. 生成PDF文件 其中由兩個地方需要注意,都是關于獲取文件路徑的問題,由于項目部署的時候是打包成jar包形式,所以在開發過程中時直接安照傳統的獲取方法沒有一點文件,但是當打包后部署,總是出錯。于是參考網上文章,先將文件讀出來到項目的臨時目錄下,然后再按正常方式加載該臨時文件; 還有一個問題至今沒有解決,就是關于生成PDF文件...