caffe 基本數據結構blob
blob是caffe中的基本數據結構,簡單理解就是一個“4維數組”。但是,這個4維數組有什么意義?
BTW,TensorFlow這款google出的框架,帶出了tensor(張量)的概念。雖然是數學概念,個人還是傾向于簡單理解為“多維數組”,那么放在這里,caffe的blob就相當于一個特殊的tensor了。而矩陣就是二維的張量。
anyway,看看blob的4個維度都代表什么:
num: 圖像數量
channel:通道數量
width:圖像寬度
height:圖像高度caffe中默認使用的SGD隨機梯度下降,其實是mini-batch SGD
每個batch,就是一堆圖片。這一個batch的圖片,就存儲在一個blob中。
當然,blob并不是這么受限的、專門給batch內的圖片做存儲用的。實際上,參數、梯度,也可以用blob存儲的。只要是caffe的網絡中傳遞的數據,都可以用blob存儲。
而且,blob實際上也并不一定是4維的。它在實現上其實就是1維的指針,而我們作為用戶感受到的“多個維度”是通過shape來操作的。
========= 2016-10-26 20:32:45更新 ==========
在用faster-rcnn訓練的時候使用了ZF網絡,對于ZF網絡中的卷積、池化的計算,這里想自己算一算,結果發現對于卷積網的計算細節還是不太懂,于是找到這篇博客。

一開始對于博客中的推導,1、2=>3這里不理解:
1、首先,輸入圖片大小是 2242243(這個3是三個通道,也就是RGB三種)
2、然后第一層的卷積核維度是 773*96 (所以大家要認識到卷積核都是4維的,在caffe的矩陣計算中都是這么實現的);
3、所以conv1得到的結果是11011096 (這個110來自于 (224-7+pad)/2 +1 ,這個pad是我們常說的填充,也就是在圖片的周圍補充像素,這樣做的目的是為了能夠整除,除以2是因為2是圖中的stride, 這個計算方法在上面建議的文檔中有說明與推導的);
第一感覺是,conv1得到的應該是110x110x3x96的結果,而不是110x110x96。后來問了別人,再看看書,發現自己忽略了一個細節,就是卷積之后有一個∑和sigmoid的兩個過程,前者是累加,后者是映射到0-1之間。具體到faster-rcnn,∑對應的就是:各個通道上對應位置做累加;而**函數使用的應該是ReLU吧。anyway,這里的累加和**函數處理后,通道數就變成了一個;也就是,對于一個濾波器,滑窗濾波+累加、**函數后,得到的一個feature map。
再具體點說,這里的濾波器(卷積核),是3維的,(Width,Height,Channel)這樣;我們用它在一個feature map上按滑窗方式做卷積,其實是所有Channel上同時做sliding window的操作;每個sliding windows位置上,所有通道卷積的結果累加起來,再送給**函數ReLU處理,就得到結果feature map中的一個像素的值。
值得注意的是,濾波器的通道數量,和要處理的feature map的通道數量,其實可以不一樣的,可以比feature map維度少一點,這相當于可以自行指定要選取feature map中的某些channel做卷積操作,相當于有一個采樣的過程,甚至可以僅僅使用一個channel的卷積結果。具體例子,可以參考《人工智能(第三版)》(王萬良著)里面的例子,結合例子中算出的“要學習的參數數量”來理解。
總結
在caffe中,Blob類型是(Width,Height,Channel,Number)四元組,表示寬度、高度、通道數量、數量(或者叫種類)
圖像本身、feature map、濾波器(kernel),都可以看做是Blob類型的具體例子
一個“層”,可以理解為執行相應操作后,得到的結果。比如,執行卷積操作,得到卷積層;執行全連接操作,得到全連接層。通常把池化層歸屬到卷積層里面。池化就是下采樣的意思,有最大池化和平均池化等。
對于一個卷積層,其處理的“輸入”是多個feature maps,也就是一個Blob實例:(H1,W1,C1,N1),比如(224,224,3,5),表示5張圖像(這里的5,可以認為是一個minibatch的batch size,即圖片數量)
卷積操作需要卷積核的參與,卷積核也是Blob的實例:(H2,W2,C2,N2),比如(7,7,3,96),表示有96個卷積核,每個卷積核是一個3維的結構,是7x7的截面、3個通道的卷積核
卷積層的輸出也是若干feature maps,也是一個Blob實例:(H3,W3,C3,N3),是根據輸入的feature maps和指定的卷積核計算出來的。按上面的例子,得到feature map的Blob描述為(110,110,96,5),表示有5個feature maps,每個feature map是110x110x96大小。
通常可以這樣理解:卷積核的個數,作為結果feature maps中的通道數量。
參考
http://blog.csdn.net/u014114990/article/details/51125776
=========== 2016-10-27 21:06:24 再次update ===========
其實上面的理解簡直是過于瑣碎、過于不到位。其實CNN的數據流動,包括前向傳播和反向傳播,都是blob經過一層,得到一個新的blob,這個層通常是卷積操作。這個卷積是3D卷積,是空間的卷積!簡言之,每次把空間的一個長方體內部的元素值累加,即得到結果feature map中的一個像素值(通常是滑窗操作,所以說是得到一個像素值):
feature map --(3D卷積)--> 新的feature map
智能推薦

深度學習21天實戰caffe學習筆記《7 :Caffe數據結構》
Caffe數據結構 一、基本概念 二、Blob:Caffe的基本存儲單元 blob: 四維數組,維度從低到高(width_,height_,channels_,num_); 用于存儲和交換數據;存儲數據或者權值(data)和權值增量(diff); 提供統一的存儲器接口,持有一批圖像或其他數據、權值、權值更新值; 進行網絡計算時,每層的輸入、輸出都需要通過Blob對象緩沖。 (1)基本用法 可自動同...

Caffe網絡結構實現
對于神經網絡實現手寫數字識別(MNIST)網絡結構通過在線可視化工具查看和修改: (http://ethereon.github.io/netscope/#/editor ) 一、卷積層(Convolution) 輸入為28*28的圖像,經過5*5的卷積之后,得到一個(28-5+1)*(28-5+1) = 24*24的map。 每個map是不同卷積核在前一層每個map上進行卷積,并將每個對應位置上...
caffe網絡結構解析
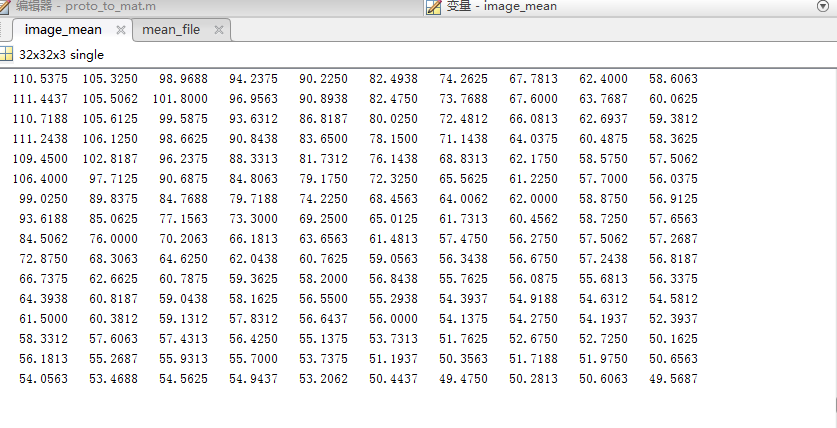
一、均值文件是什么: 下面是make_imagenet_mean.sh里面的內容 可以看出用compute_image_mean.exe執行了均值文件計算,而且只計算了my_train_leveldb 的均值,這是訓練數據。 均值文件是通過訓練集計算出來的,測試集不需要計算出均值文件。在訓練階段和測試階段都是用的訓練集的均值文件。 均值的理論概念參考:http://ufldl.stanford.e...

Caffe學習(五)——Blob,Layer,Net介紹
簡介 深度網絡(Net)是由許多互相連接的層(layers)組合成的組合模型,Caffe定義的網絡模型就是這樣逐層(layers)連接。 Net包含了整個自頂向下的網絡,網絡由各個Layer組合而成; Layer指處理數據的單層運算算子(比如卷積運算、pooling運算等); Blob是網絡運行時數據存儲、傳遞和操作的接口; 以examples/mnist/lenet_train_test.pro...
caffe訓練測試(用caffe訓練自己的數據)
初試caffe訓練,這里不是跑的caffe里自帶的例子,是訓練測試自己的數據集,歡迎指正~ps:這邊就不介紹caffe的安裝配置了,直接進入主題啦~ 1大量樣本的準備 既然要做訓練的話沒有大量的圖片樣本是不行滴,這個階段耗費很久的時間,說到這里要吐血了,三個人,對采集的視頻中的每幀圖片進行截圖,不夸張的說總共截的圖片大概有近百萬張,當然啦還要對圖片進行篩選不好的樣本不要,否則會影響測試效果!我們一...
猜你喜歡
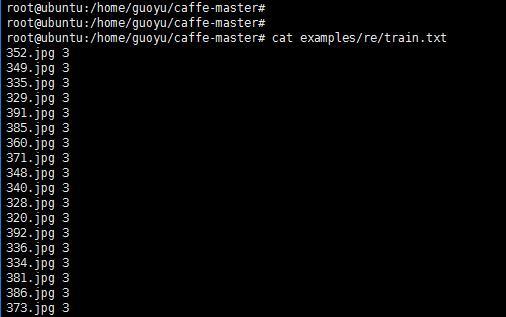
Caffe入門(2)-Caffe讀取并轉換圖片數據
本教程用于從文件夾中讀取訓練數據(圖片)并轉換為caffe需要的mdb格式,隨后將其用于后續的訓練和測試。 一、原始數據 這里選用徐其華(denny402)收集的數據,共有500張圖片,分為大巴車、恐龍、大象、鮮花和馬五個類,每個類100張。網盤地址為-網盤地址。編號分別以3,4,5,6,7開頭,各為一類。我從其中每類選出20張作為測試,其余80張作為訓練。因此最終訓練圖片400張,測試圖片100...

用caffe跑自己的數據,基于WINDOWS的caffe
轉載自:http://www.cnblogs.com/love6tao/p/5743030.html 用caffe跑自己的數據,基于WINDOWS的caffe 本文詳細介紹,如何用caffe跑自己的圖像數據用于分類。 1 首先需要安裝過程見 http://www.cnblogs.com/love6tao/p/5706830.html 同時依據上面教程,生成了caffe.exe 2 構建自...

caffe詳解之數據層
數據層參數說明 三種常用的數據來源 使用LMDB 使用HDF5 使用圖片 Epochs Batch Iteration 當一個完整的數據集通過了神經網絡一次并且返回了一次,這個過程稱為一個epoch。一般情況下在迭代的過程中需要使用多次epoch防止模型欠擬合。 在不能將數據一次性通過神經網絡的時候,就需要將數據集分成幾個batch(Number of batches,簡記為batch_num)。...
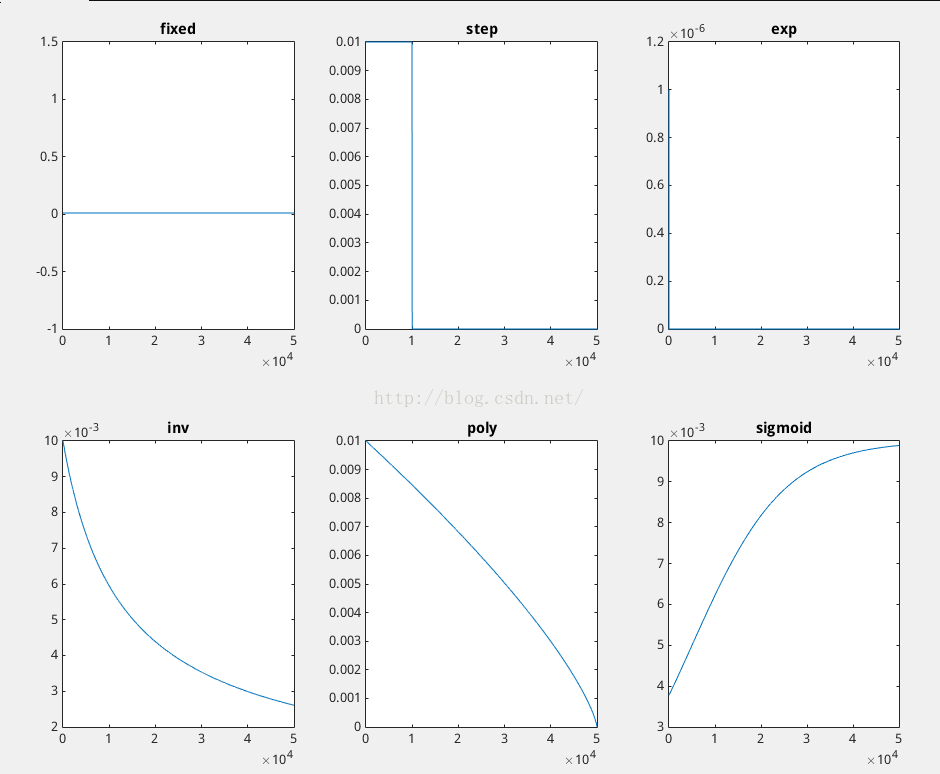
Caffe:訓練自己的數據
1、數據準備 對于訓練,需要兩個數據集:一個用于train,一個用于validation(邊訓練邊測試,用于檢測模型變化)。 具體過程參考博文caffe學習系列:訓練自己的圖片集(超詳細教程),簡要步驟如下: (1)準備好訓練和測試樣本...
