Python爬蟲入門實例五之淘寶商品信息定向爬取(優化版)
標簽: Python爬蟲實例 python 正則表達式 爬蟲
文章目錄
寫在前面
??這個例子是筆者今天在中國大學MOOC(嵩天 北京理工大學)上學習的時候寫下來的。但是很快寫完之后我就發現不對勁,因為照著老師的代碼寫完后運行并不能爬取到信息,經過我的一番折騰,基本解決了問題,并且做了一些優化,寫這篇博客記錄一下,下圖是最終的爬取結果。
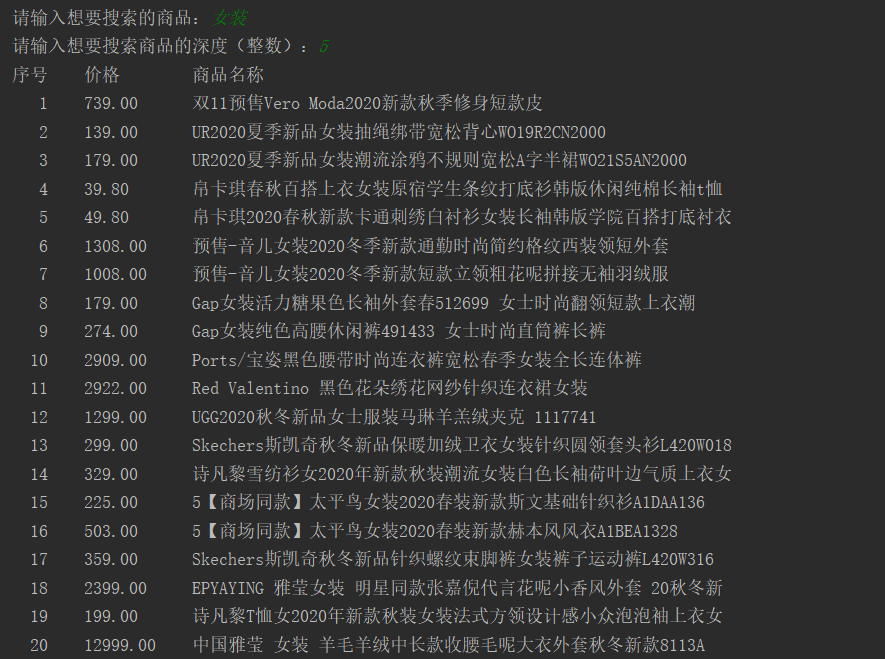
一、爬取原頁面
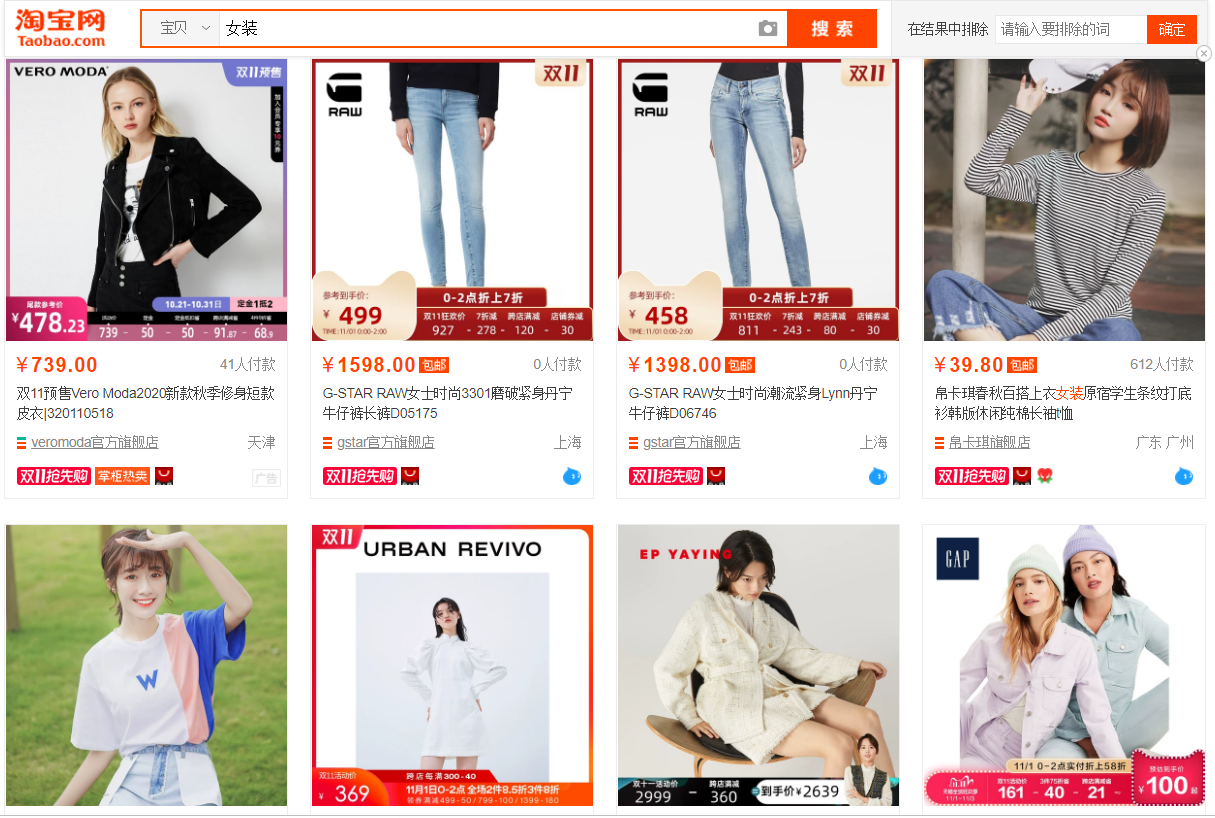
??爬取頁面為淘寶網站,以女裝為例,原圖如下,由于淘寶商品排名實時更新,所以爬取結果順序與網站順序可能會存在不同。本實例爬取的內容為商品的價格和名稱,并為其添加序號。
二、編程思路
??這一部分嵩天老師在課中給出了講解,這里我整理分享給大家。
1.功能描述
目標:獲取淘寶搜索頁面的信息,提取其中的名稱和價格。
理解:
(1).獲得淘寶的搜索接口
(2).對翻頁的處理
技術路線:requests-re
2.程序的結構設計
步驟一:提交商品搜索請求,循環獲取頁面
步驟二:對于每個頁面,提取商品名稱和價格信息
步驟三:將信息輸出到屏幕上
對應上述三個步驟分別定義三個函數:
(1)getHTMLText()獲得頁面
(2)parsePage()對每一個獲得的頁面進行解析
(3)printGoodsList()將商品的信息輸出到屏幕上
三、編程過程
1.解決翻頁問題
??首先我們來看一下前三頁分別的URL

??對淘寶每一頁商品數量的觀察我們可以發現,每一頁有44個商品,結合上面的結果我們可以猜測,變量s表示的是第二頁,第三頁…頁的起始商品的編號。基于這種規則,我們就可以構建不同頁的URL鏈接。
代碼如下:
for i in range(depth):#對每次翻頁后的URL鏈接進行設計
url = start_url + '&s='+str(44*i)
html = getHTMLText(url)
parsePage(infoList,html)
2.編寫getHTMLText()函數
def getHTMLText(url):#獲得頁面
try:
kv = {'user-agent': 'Mozilla/5.0',
'cookie':' '#請自行獲取
}
r = requests.get(url,headers=kv,timeout = 30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
print("獲取頁面失敗")
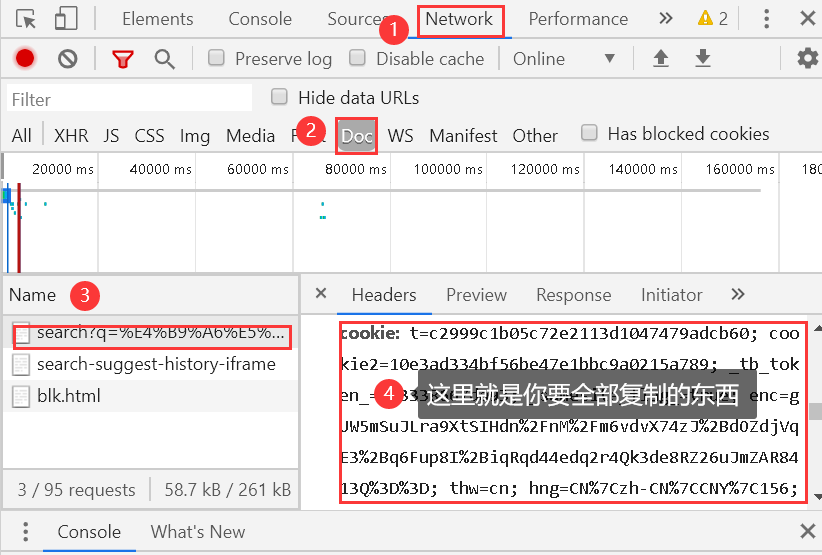
關于cookie的獲取方法,可以參考我的這篇博客
鏈接: https://blog.csdn.net/weixin_44578172/article/details/109353017.
3.編寫parsePage()函數
(1).內容解析編程思路
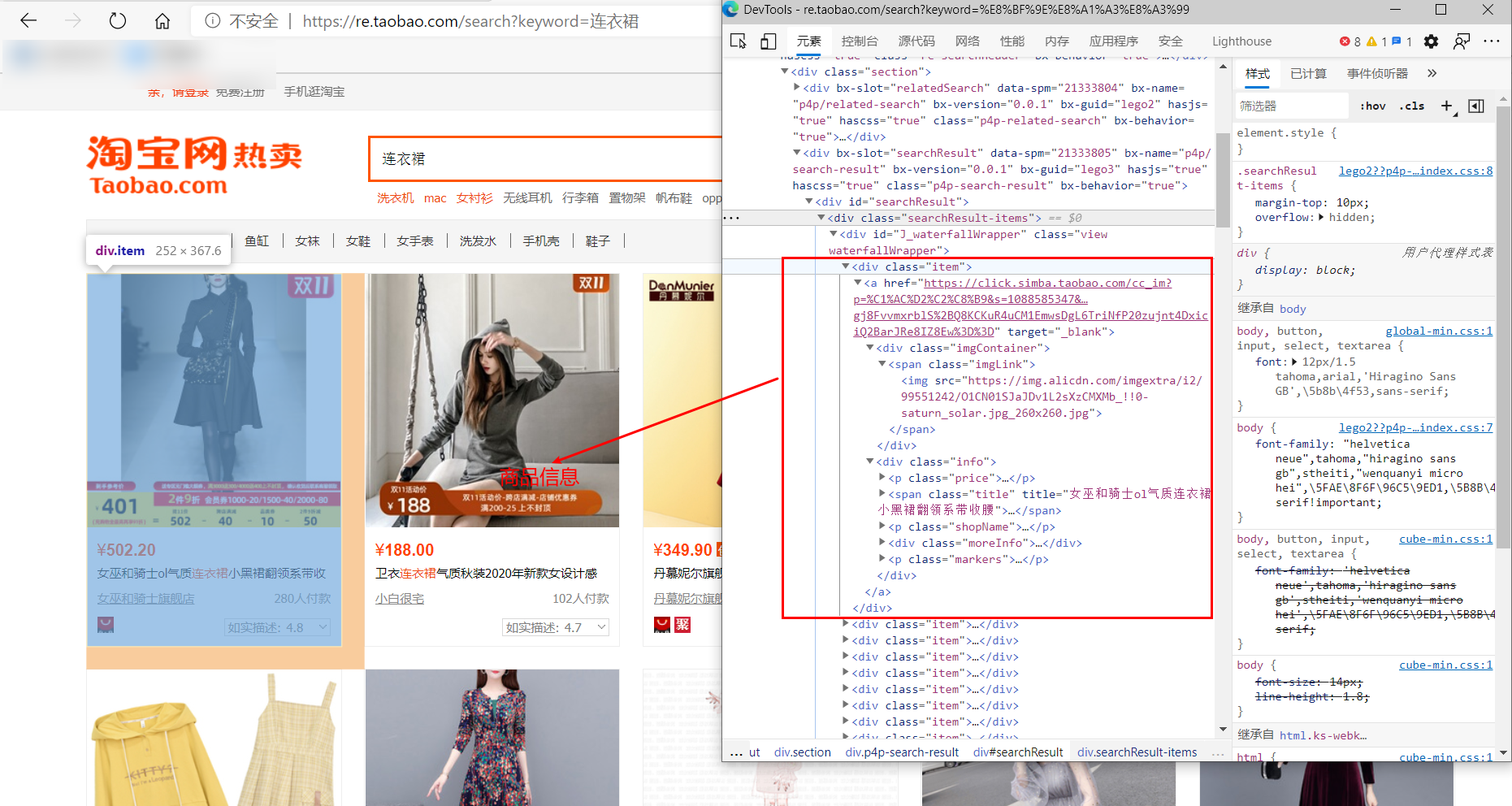
??首先查看女裝搜索結果頁面的源代碼

??通過對源代碼的觀察我們發現,淘寶中所有商品的價格和名稱是存在相應的鍵值對中的即:“view_price”:“價格”,“view_title”:“名稱”。所以我們想要獲得這兩個信息,只需要在獲得的文本中檢索到view_price和view_title并把后續的相關內容提取出來即可,這里采用正則表達式的方法。
(2).函數代碼
def parsePage(ilt,html):#對每一個獲得的頁面進行解析
#兩個變量分別是結果的列表類型和相關的HTML頁面的信息
try:
re1 = re.compile(r'\"view_price\"\:\"[\d\.]*\"')#編譯商品價格正則表達式
re2 = re.compile(r'\"raw_title\"\:\".*?\"')#編譯商品名稱正則表達式
plt = re1.findall(html)
tlt = re2.findall(html)
#plt = re.findall(r'\"view_price\"\:\"[\d\.]*\"', html)
#tlt = re.findall(r'\"raw_title\"\:\".*?\"', html)
for i in range(len(plt)):
price = eval(plt[i].split(':')[1])#去掉view_price字段,只要價格部分,eval將獲取到的最外層/內層的單引號或雙引號去掉
title = eval(tlt[i].split(':')[1])#去掉raw_title字段,只要名稱部分
ilt.append([price,title])
except:
print("網頁解析失敗")
4.編寫printGoodsList()
def printGoodsList(ilt):#將商品的信息輸出到屏幕上
try:
tplt = "{:4}\t{:8}\t{:16}" #定義打印模板
print(tplt.format("序號","價格","商品名稱"))
count = 0
for s in ilt:
count = count + 1
print(tplt.format(count,s[0],s[1]))
except:
print("輸出失敗")
四、完整代碼
'''
功能描述
目標:獲取淘寶搜索頁面的信息,提取其中的名稱和價格。
理解:
1.獲得淘寶的搜索接口
2.對翻頁的處理
技術路線:requests-re
程序的結構設計
步驟1:提交商品搜索請求,循環獲取頁面
步驟2:對于每個頁面,提取商品名稱和價格信息
步驟3:將信息輸出到屏幕上
'''
import requests
import re
def getHTMLText(url):#獲得頁面
try:
kv = {'user-agent': 'Mozilla/5.0',
'cookie':' '#請自行獲取
}
r = requests.get(url,headers=kv,timeout = 30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
print("獲取頁面失敗")
def parsePage(ilt,html):#對每一個獲得的頁面進行解析
#兩個變量分別是結果的列表類型和相關的HTML頁面的信息
try:
re1 = re.compile(r'\"view_price\"\:\"[\d\.]*\"')#編譯商品價格正則表達式
re2 = re.compile(r'\"raw_title\"\:\".*?\"')#編譯商品名稱正則表達式
plt = re1.findall(html)
tlt = re2.findall(html)
#plt = re.findall(r'\"view_price\"\:\"[\d\.]*\"', html)
#tlt = re.findall(r'\"raw_title\"\:\".*?\"', html)
for i in range(len(plt)):
price = eval(plt[i].split(':')[1])#去掉view_price字段,只要價格部分,eval將獲取到的最外層/內層的單引號或雙引號去掉
title = eval(tlt[i].split(':')[1])#去掉raw_title字段,只要名稱部分
ilt.append([price,title])
except:
print("網頁解析失敗")
def printGoodsList(ilt):#將商品的信息輸出到屏幕上
try:
tplt = "{:4}\t{:8}\t{:16}" #定義打印模板
print(tplt.format("序號","價格","商品名稱"))
count = 0
for s in ilt:
count = count + 1
print(tplt.format(count,s[0],s[1]))
except:
print("輸出失敗")
def main():
goods = input("請輸入想要搜索的商品:") #定義搜索關鍵詞變量
depth = input("請輸入想要搜索商品的深度(整數):") #定義爬取的深度即頁數
depth = int(depth)
start_url = 'https://s.taobao.com/search?q='+goods
infoList = [] #定義整個的輸出結果變量
for i in range(depth):#對每次翻頁后的URL鏈接進行設計
try:
url = start_url + '&s='+str(44*i)
html = getHTMLText(url)
parsePage(infoList,html)
except:
continue
printGoodsList(infoList)
#調用主函數
main()
??本篇完,如有錯誤歡迎指出~
引用源自
中國大學MOOC Python網絡爬蟲與信息提取
https://www.icourse163.org/course/BIT-1001870001
智能推薦

Python爬蟲學習筆記(實例:淘寶商品信息定向爬蟲)
代碼解析: 由于淘寶具有反爬蟲機制,所以在爬取商品信息的時候需要有以下幾點注意: 1.首先登錄淘寶網頁,然后登錄你的淘寶賬號 2.按下F12查看控制臺(我使用的是Chrome瀏覽器),點擊Network->All,刷新頁面,點擊下面Name列的第一行,右鍵Copy->Copy as cURL(bash) 3.進入一下網站:https://curl.trillworks.com/,將剛才...
網絡爬蟲爬取淘寶頁面商品信息
網絡爬蟲爬取淘寶頁面商品信息 最近在MOOC上看嵩老師的網絡爬蟲課程,按照老師的寫法并不能進行爬取,遇到了一個問題,就是關于如何“繞開”淘寶登錄界面,正確的爬取相關信息。通過百度找到了答案,在此記錄一下。 針對以上問題主要的代碼是 會在最后附上全代碼(不含cookie) 那么問題的關鍵就是cookie的獲取 (1)首先需要用到Google chrome瀏覽器登錄淘寶 (2)...
【爬蟲】爬取淘寶網的商品信息
文章目錄 一、思路 1、根據關鍵詞搜索 2、數據提取 3、數據保存 二、結果 三、源代碼 一、思路 首先,從命令行參數列表中,提取出要爬取商品的關鍵詞,根據關鍵詞拼接URL,請求相應的URL,然后利用Xpath從響應頁面中提取商品信息,最后將商品信息存儲到數據庫即可 1、根據關鍵詞搜索 通過參數傳入關鍵詞,然后進行URL拼接 2、數據提取 這里用Xpath從網頁中提取想要的商品信息,也可以使用正則...

爬蟲項目2 - 淘寶商品信息爬取
淘寶商品信息爬取 步驟 步驟 首先找到淘寶登陸界面: https://login.taobao.com/member/login.jhtml 使用selenium + beautiful進行模擬登陸+數據爬取,可以稍微延長等待時間: 完成。用途:商品動態定價分析。...
猜你喜歡

爬取淘寶商品信息(正則版)
爬取淘寶商品信息(正則版) 確定目標信息的存在形式,可以看到價格前面有標簽"view_price",標題前面有標簽"title" 程序分為四部分,分別為提取網頁HTML文本、解析頁面對目標信息進行提取、打印信息以及主函數。 具體如下:...
(廿八)Python爬蟲:使用Selenium爬取淘寶商品信息
上文學習了Selenium,本文使用它爬取淘寶搜索到的商品信息,并且將數據存儲在MongoDB中。 爬取步驟 1、進入淘寶首頁,獲取輸入框和搜索按鈕 2、進入搜索結果頁面,獲取爬取的總頁數 3、實現頁面逐頁跳轉 通過向輸入框中輸入待跳轉頁面,點擊確定按鈕進行頁面的跳轉,發生異常重新跳轉; 4、等待商品信息加載,解析商品信息 首先通過比較高亮頁碼數是否等于跳轉頁碼判斷是否跳轉成功,成功則繼續,否則重...


freemarker + ItextRender 根據模板生成PDF文件
1. 制作模板 2. 獲取模板,并將所獲取的數據加載生成html文件 2. 生成PDF文件 其中由兩個地方需要注意,都是關于獲取文件路徑的問題,由于項目部署的時候是打包成jar包形式,所以在開發過程中時直接安照傳統的獲取方法沒有一點文件,但是當打包后部署,總是出錯。于是參考網上文章,先將文件讀出來到項目的臨時目錄下,然后再按正常方式加載該臨時文件; 還有一個問題至今沒有解決,就是關于生成PDF文件...