scrapy 爬蟲框架簡介
scrapy介紹
Scrapy,Python開發的一個快速、高層次的屏幕抓取和web抓取框架,用于抓取web站點并從頁面中提取結構化的數據。Scrapy用途廣泛,可以用于數據挖掘、監測和自動化測試。
Scrapy吸引人的地方在于它是一個框架,任何人都可以根據需求方便的修改。它也提供了多種類型爬蟲的基類,如BaseSpider、sitemap爬蟲等,最新版本又提供了web2.0爬蟲的支持。
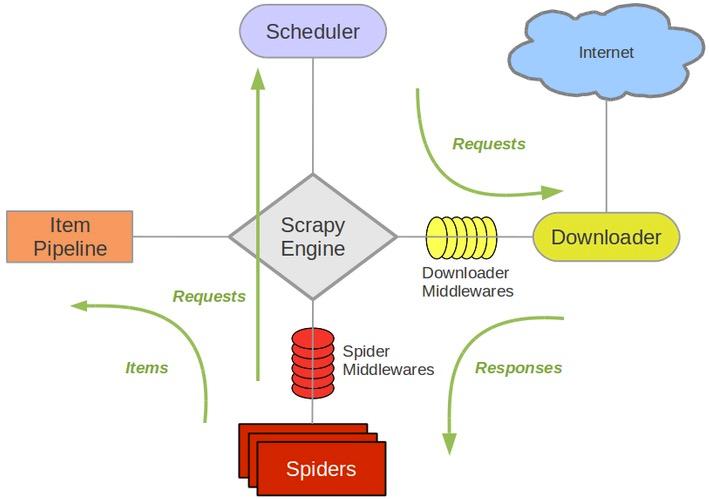
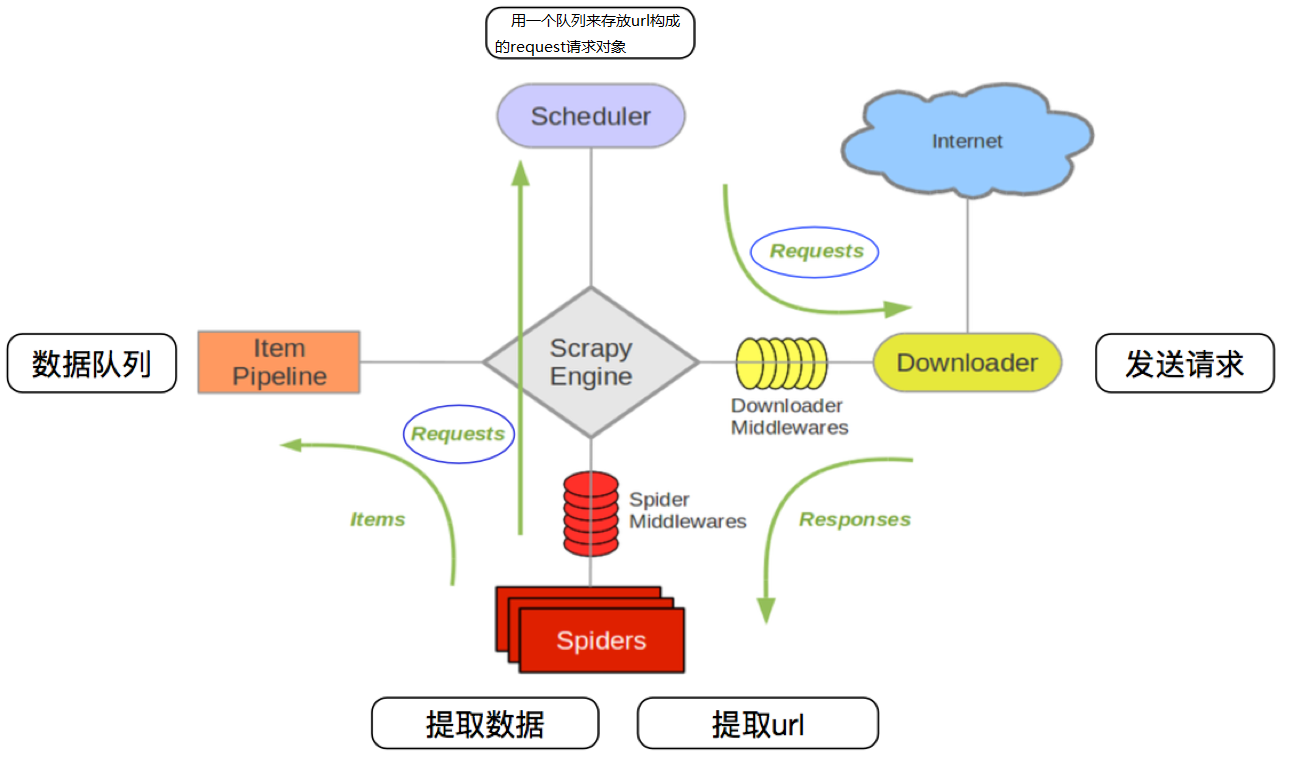
scrapy data flow(流程圖)
Scrapy使用了Twisted作為框架,Twisted有些特殊的地方是它是事件驅動的,并且比較適合異步的代碼。對于會阻塞線程的操作包含訪問文件、數據庫或者Web、產生新的進程并需要處理新進程的輸出(如運行shell命令)、執行系統層次操作的代碼(如等待系統隊列),Twisted提供了允許執行上面的操作但不會阻塞代碼執行的方法。
下面的圖表顯示了Scrapy架構組件,以及運行scrapy時的數據流程,圖中紅色箭頭標出。
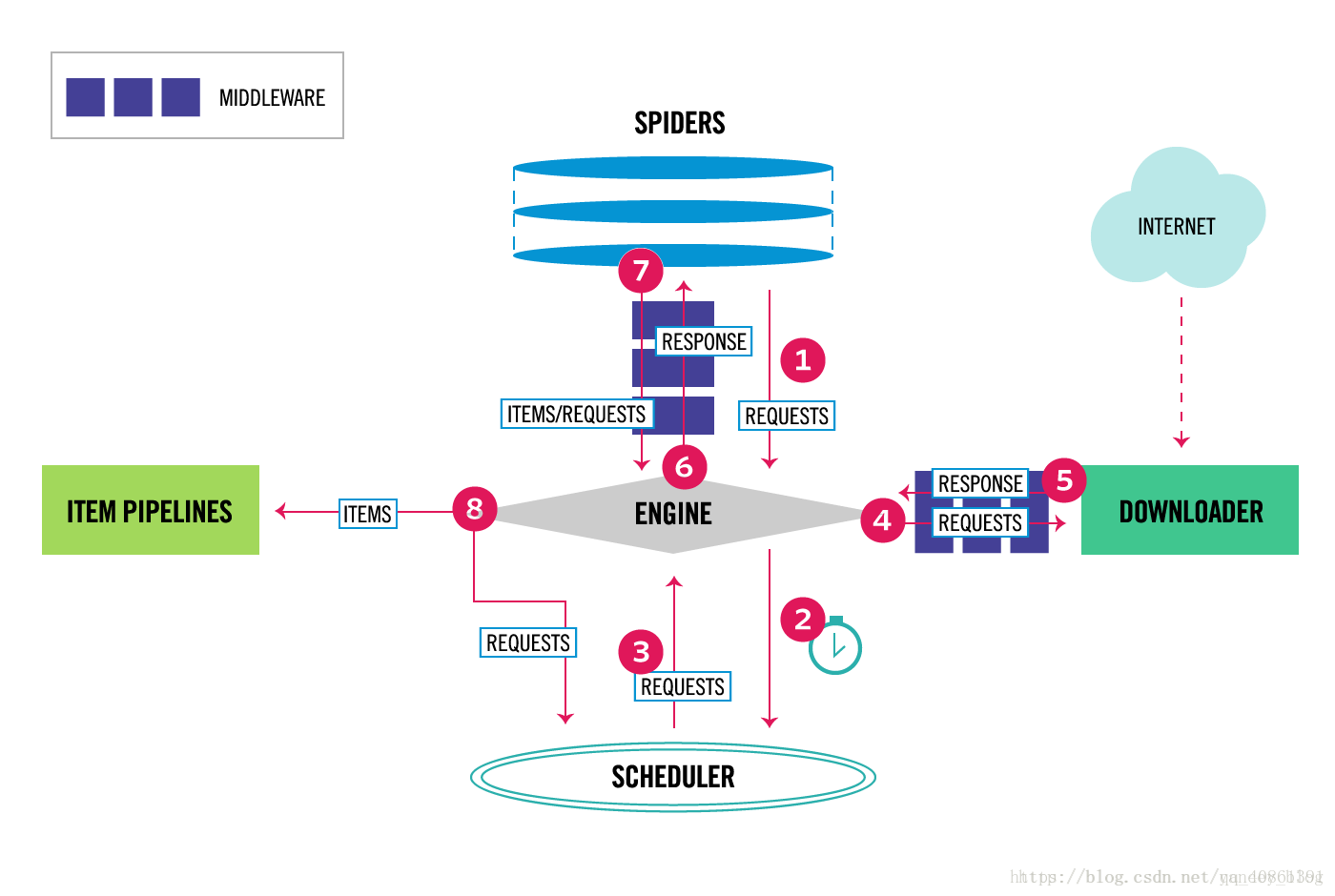
Scrapy數據流是由執行的核心引擎(engine)控制,流程是這樣的:
- 爬蟲引擎獲得初始請求開始爬取
- 爬蟲引擎開始請求調度程序,并準備對下一次的請求進行爬取。
- 爬蟲調度器返回下一個請求給爬蟲引擎。
- 引擎請求發送到下載器,通過下載中間件下載網絡數據
- 一旦下載器完成頁面下載,將下載結果返回給爬蟲引擎。
- 引擎將下載器的響應通過中間件返回給爬蟲進行處理。
- 爬蟲處理響應,并通過中間件返回處理后的items,以及新的請求給引擎
- 引擎發送處理后的items到項目的管道,然后把處理結果返回給調度器,調度器計劃處理下一個請求抓取
- 重復該過程,直到爬取完所有的url請求
上圖展示了scrapy的所有組件工作流程,下面單獨介紹各個組件:
爬蟲引擎(ENGINE)
爬蟲引擎負責控制各個組件之間的數據流,當某些操作觸發事件后都是通過engine來處理。下載器
通過engine請求下載王叔數據并將結果響應給engine。調度器
調度接收來engine的請求并將請求放入隊列中,并通過事件返回給engineSpider
Spider發出請求,并且處理engine返回給它下載器響應的數據,以items和規則內的數據請求(url)返回給engine管道項目(item pipeline)
負責處理engine返回spider解析后的數據,并且將數據持久化,例如將數據存入數據庫或者文件。- 下載中間件
下載中間件是engine和下載器交互組件,以鉤子(插件)的形式存在,可以代替接收請求、處理數據的下載以及將結果響應給engine。 - spider中間件
spider中間件是engine和spider之間的交互組件,以鉤子(插件)的形式存在,可以代替處理response以及返回給engine items及新的請求集。
如何創建scrapy環境和項目
# 創建虛擬的環境
virtualenv --no-site-packages 環境名
# 進入虛擬環境文件夾
cd 虛擬環境文件夾
# 運行虛擬環境
cd Scrapits
activate
# 可以更新pip
python -m pip install -U pip
# 在虛擬環境里 windows下安裝Twisted-18.4.0-cp36-cp36m-win32.wh
pip insttall E:\Twisted-18.4.0-cp36-cp36m-win32.wh
# 在虛擬環境中安裝scrapy
pip install scrapy
# 創建自己的項目,(可以單獨創建項目文件夾) 在虛擬環境中切換到創建的文件下
scrapy startproject 項目名字
# 創建spider(蜘蛛)
scrapy genspider 蜘蛛名字 允許訪問的地址
例如:
scrapy genspider movie movie.douban.com
scrapy項目結構
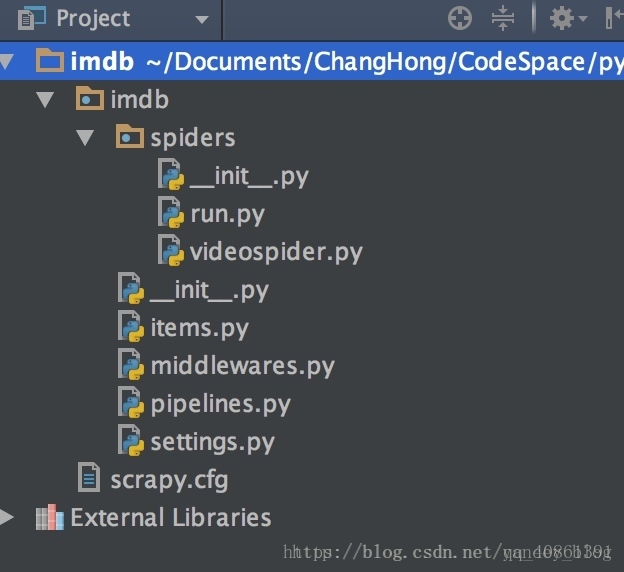
- items.py 負責數據模型的建立
- middlewares.py 中間件
- pipelines.py 負責對spider返回數據的處理。
- settings.py 負責對整個爬蟲的配置。
- spiders目錄 負責存放繼承自scrapy的爬蟲類。
- scrapy.cfg scrapy基礎配置
智能推薦
Scrapy框架爬蟲案例
運行環境 要爬取的部分為 通過查看源代碼,需要解析的代碼就是這么一部分 創建項目 首先創建項目,cmd輸入命令 創建項目成功,項目目錄結構如下圖 爬蟲定義 在spiders文件夾下創建...
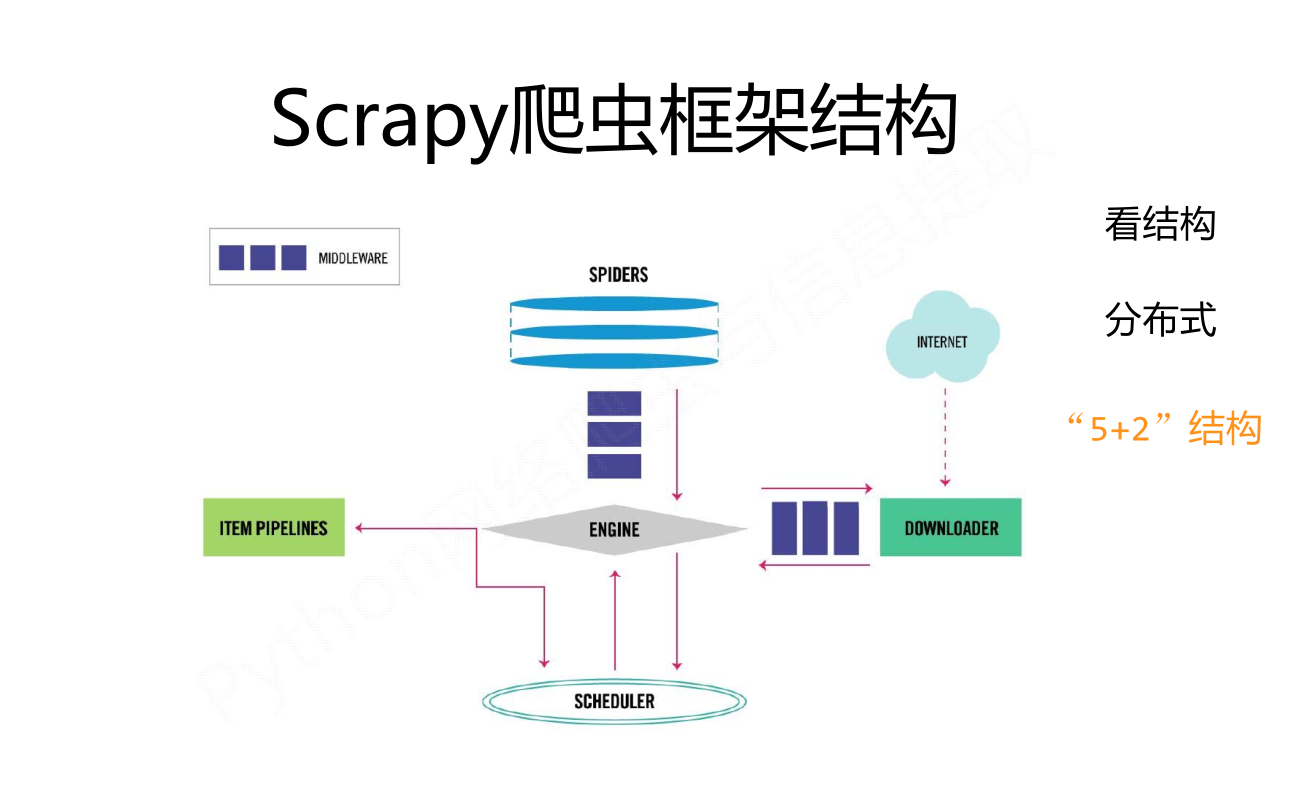
scrapy爬蟲框架
一、scrapy爬蟲框架 1、scrapy的基本介紹 scrapy的安裝:pip install scrapy 測試:scrapy -h Scrapy不是一個函數功能庫,而是一個爬蟲框架 爬蟲框架是實現爬蟲功能的一個軟件結構和功能組件集合。 爬蟲框架是一個半成品,能夠幫助用戶實現專業網絡爬蟲。 1-1 Scrapy框架組成部分(5個模塊) 模塊 說明 Engine 控制價所有模塊之間的數據流。根據...
Scrapy爬蟲框架
本文參考傳智播客的Scrapy框架**** 視頻課程鏈接:http://study.163.com/course/courseMain.htm?courseId=1004236002 Scrapy 爬蟲初探 1、概述 Scrapy是用純Python實現的一個為了爬取網站數據、提取結構性數據而編寫的應用框架 用戶只需要定制開發幾個模塊就可以輕松的實現一個爬蟲,用來抓取網頁內容以及各種圖片 Scrap...

初試爬蟲框架scrapy
最近簡單了解了下scrapy,這是一個python的爬蟲框架,使用起來比較簡單。我的學習時間比較短,所以就不深入,但也要做個記錄,以后如果用到比較容易想起來。 安裝 我的centos是6.5版本的,自帶的python是2.6.6版本的,因為yum是python的腳本,所以不能直接升級成python3,那就在Windows下玩吧。 Windows下直接下載python3的安裝包就行了,安裝時勾選上將...
猜你喜歡
爬蟲(九)--scrapy框架
一、scrapy框架 (一)安裝 (二)步驟 1.創建項目 2.配置 不遵循robot協議 請求頭 3.編寫想要獲取的url,并測試 啟動命令 4.設置想要提取的字段 5.實例化item對象 6.提取數據 7.存入item對象 (三)目錄結構 一定要嚴格按照這個目錄結構,不然運行命令會發生找不到命令的情況。 二、scrapy框架圖及組件 三、scrapy發送二次請求 在scrapy項目中,我們想要...
python爬蟲框架scrapy
一、使用pip3下載scrapy框架,安裝過程中會自動下載相關依賴 二、下載完成后,創建軟鏈接到/bin中 三、創建項目目錄 demo并使用scrapy初始化項目,進入到項目demo下。 四、scrapy項目結構分析 1-items.py 定義爬蟲抓取到的數據映射實體:如下圖 2-middlewares.py:定義爬蟲中間件 3-pipelines.py:定義數據管道,...
Scrapy爬蟲框架
scrapy的流程 爬蟲中起始的url構造成request對象–>爬蟲中間件–>引擎–>調度器 調度器把request–>引擎–>下載中間件—>下載器 下載器發送請求,獲取response響應---->下載中間件---->引擎—>爬蟲中間件—>...


freemarker + ItextRender 根據模板生成PDF文件
1. 制作模板 2. 獲取模板,并將所獲取的數據加載生成html文件 2. 生成PDF文件 其中由兩個地方需要注意,都是關于獲取文件路徑的問題,由于項目部署的時候是打包成jar包形式,所以在開發過程中時直接安照傳統的獲取方法沒有一點文件,但是當打包后部署,總是出錯。于是參考網上文章,先將文件讀出來到項目的臨時目錄下,然后再按正常方式加載該臨時文件; 還有一個問題至今沒有解決,就是關于生成PDF文件...