XML解析器:DOM、SAX、DOM4J
※ XML學習 W3CSchool.chm文件
※ XML解析器
JAXP介紹(Java API for XMLProcessing)
JAXP 是J2SE的一部分,它由javax.xml、org.w3c.dom 、org.xml.sax 包及其子包組成.
在 javax.xml.parsers 包中,定義了幾個工廠類,程序員調用這些工廠類,可以得到對xml文檔進行解析的 DOM 或 SAX 的解析器對象。
(一)SAX解析
SAX:基于事件處理的機制
sax解析xml文件時,
遇到開始標簽,結束標簽,
開始解析文件,文件解析結束,字符內容,
空白字符等都會觸發各自的方法。
優點:
適合解析大文件,對內存要求不高
輕量級的解析數據方式,效率更高
缺點:
不能隨機解析
不能修改XML文件,只能進行查詢
(二)DOM解析:
采用dom解析,會將xml文檔全部載入到內存當中,然后將xml文檔
中的所有內容轉換為tree上的節點(對象)。
優點:
可以隨機解析
可以修改文件
可以創建xml文件
缺點:
適合解析小文件,對內存要求高
獲得JAXP中的DOM解析器步驟
1調用 DocumentBuilderFactory.newInstance() 方法得到創建 DOM 解析器的工廠。
2調用工廠對象的 newDocumentBuilder方法得到 DOM 解析器對象。
3調用 DOM 解析器對象的 parse() 方法解析 XML 文檔,得到代表整個文檔的 Document 對象,進行可以利用DOM特性對整個XML文檔進行操作了。
JAXP的dom解析
例如:
//獲得生產DocumentBuilder對象的工廠實例
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
//設置是否支持名稱空間 默認是不支持
factory.setNamespaceAware(true);
//通過工廠獲得一個DocumentBuilder對象
DocumentBuilder builder = factory.newDocumentBuilder();
//獲得Document對象,可以表示一個xml文檔
Document document = builder.parse(fileName);
//獲得根元素
//注意Document和Element都是Node的子接口
Element root = document.getDocumentElement();
//獲得根元素下面的所有子元素
//注意回車換行也算是一個節點(文本節點)
//xml文件中主要是文本節點和元素節點
//元素節點中還包含屬性節點
//我們要解析的值就在這些節點中
//這一步之后就是循環解析節點中的數據
NodeList rootChildNodes = root.getChildNodes();在使用 DOM 解析 XML 文檔時,需要讀取整個 XML 文檔,在內存中構建代表整個 DOM 樹的Doucment對象,從而再對XML文檔進行操作。此種情況下,如果 XML 文檔特別大,就會消耗計算機的大量內存,嚴重情況下可能還會導致內存溢出。
SAX解析允許在讀取文檔的時候,即對文檔進行處理,而不必等到整個文檔裝載完才會文檔進行操作。
sax解析器在發現xml文檔中的內容時就會調用你重新之后的方法. 如何處理這些內容,由程序員自己決定。
在基于sax 的程序中,有五個最常用sax事件
startDocument() —> 解析器發現了文檔的開始標簽
endDocument() —> 解析器發現了文檔結束標簽
startElement() —> 解析器發現了一個起始標簽
character() —> 解析器發現了標簽里面的文本值
endElement() —> 解析器發現了一個結束標簽
SAX采用事件處理的方式解析XML文件,利用 SAX 解析 XML 文檔,涉及兩個部分:解析器和事件處理器:
解析器可以使用JAXP的API創建,創建出SAX解析器后,就可以指定解析器去解析某個XML文檔。
解析器采用SAX方式在解析某個XML文檔時,它只要解析到XML文檔的一個組成部分,都會去調用事件處理器的一個方法,解析器在調用事件處理器的方法時,會把當前解析到的xml文件內容作為方法的參數傳遞給事件處理器。
事件處理器由程序員編寫,程序員通過事件處理器中方法的參數,就可以很輕松地得到sax解析器解析到的數據,從而可以決定如何對數據進行處理。
使用SAXParserFactory創建SAX解析工廠
SAXParserFactory spf = SAXParserFactory.newInstance();
通過SAX解析工廠得到解析器對象
SAXParser sp = spf.newSAXParser();
將解析對象和事件處理器對象關聯
sp.parse(“src/class.xml”, new DefaultHandler(){…});
Dom4j是一個簡單、靈活的開放源代碼的庫。Dom4j是由早期開發JDOM的人分離出來而后獨立開發的。與JDOM不同的是,dom4j使用接口和抽象基類,雖然Dom4j的API相對要復雜一些,但它提供了比JDOM更好的靈活性。
Dom4j是一個非常優秀的Java XML API,具有性能優異、功能強大和極易使用的特點。現在很多軟件采用的Dom4j,例如Hibernate,包括sun公司自己的JAXP也用了Dom4j。
使用Dom4j開發,需下載dom4j相應的jar文件。
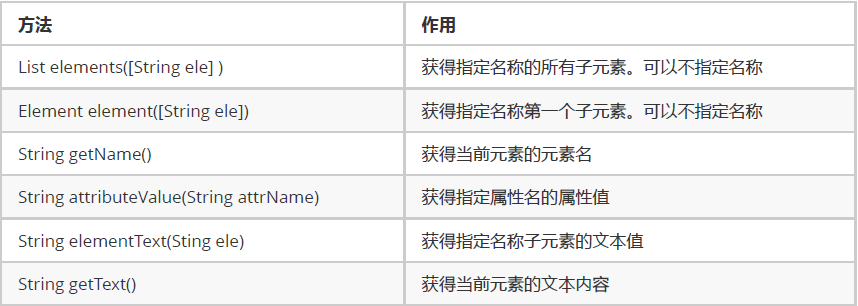
DOM4j中,獲得Document對象的方式有三種:
開發dom4j要加入新jar包,并且在倒包時要導入dom4j的包
1.讀取XML文件,獲得document對象
SAXReader reader = new SAXReader();
Document document = reader.read(new File(“src/input.xml"));2.解析XML形式的文本,得到document對象.
String text = "<members></members>";
Document document = DocumentHelper.parseText(text);3.主動創建document對象.
Document document = DocumentHelper.createDocument();
//創建根節點
Element root = document.addElement("members");※ 解析器原理
xml文件中儲存的是對象類中構建對象的數據,怎樣對xml文件中數據進行增刪改查呢?為了獲得xml文件的信息,建立解析器。
<!--stu.xml文件-->
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<students>
<student id="1">
<name>tom</name>
<age>33</age>
</student>
<student id="2">
<name>jake</name>
<age>23</age>
</student>
<student id="3">
<name>lili</name>
<age>65</age>
</student>
</students>
//對應的Java對象類
package com.xml.dom;
public class Student {
private long id;
private String name;
private int age;
public Student() {
}
@Override
public String toString() {
return "Student [id=" + id + ", name=" + name + ", age=" + age + "]";
}
public Student(long id, String name, int age) {
this.id = id;
this.name = name;
this.age = age;
}
public long getId() {
return id;
}
public void setId(long id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
//原理解析
//類似數組查詢先找到要的信息,在進行修改
package com.xml.dom;
import java.util.Arrays;
public class Test {
public static void main(String[] args) {
//構建一個數組
String str="id=\"23\"";
// 判斷數組是否包含id
// System.out.println(str.contains("id"));
//以引號分割字符串,\轉移字符
String[] strs=str.split("\"");
System.out.println(Arrays.toString(strs));//[id=, 23]
}
}
※ DOM解析器構建,完成XML文件增、刪、改、查
※ 將XML文件信息分析成“樹”

package com.xml.dom;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.transform.OutputKeys;
import javax.xml.transform.Transformer;
import javax.xml.transform.TransformerConfigurationException;
import javax.xml.transform.TransformerException;
import javax.xml.transform.TransformerFactory;
import javax.xml.transform.dom.DOMSource;
import javax.xml.transform.stream.StreamResult;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.NamedNodeMap;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import org.xml.sax.SAXException;
public class DomParseTest {
//主方法
public static void main(String[] args) {
//List<Student> list=new DomParseTest().getAllStudent();
//for(Student s:list){
//System.out.println(s);
//}
//new DomParseTest().addStudent(
//new Student(4, "wangwu", 67));
new DomParseTest().deleteStudent(4);
}
/*
*構建解析器并獲得XML文件整個“樹”
*/
public List<Student> getAllStudent(){
List<Student> stus=new ArrayList<>();
//構建產生解析器的工廠
DocumentBuilderFactory dbf=
DocumentBuilderFactory.newInstance();
//構建解析器
try {
DocumentBuilder builder=
dbf.newDocumentBuilder();
//解析器讀取文件,把xml文件內容裝載到內存轉化為tree
// builder.parse(new File(""));
// builder.parse(new FileInputStream(""))
Document doc=
builder.parse("src/com/xml/dom/stu.xml");
//獲取一級標簽(根標簽)
Element root=doc.getDocumentElement();
// System.out.println(root);
//獲取標簽的名字
// System.out.println(root.getNodeName());
//獲取二級標簽
NodeList list=root.getChildNodes();
//獲取集合中節點的的個數
//System.out.println(list.getLength());
//基于角標獲取集合中的節點
// System.out.println(list.item(0));
// System.out.println(list.item(1));
// System.out.println(list.item(2));
// System.out.println(list.item(3));
// System.out.println(list.item(4));
for(int i=0;i<list.getLength();i++){
Node node=list.item(i);
//node.getNodeType()獲取單前節點的類型
//ELEMENT_NODE表示元素節點(標簽)
//ATTRIBUTE_NODE屬性節點
//TEXT_NODE文本節點
if(node.getNodeType()==Node.ELEMENT_NODE){
Student stu=new Student();
//獲取標簽中的所有的屬性
NamedNodeMap map=node.getAttributes();
//基于屬性名字獲取特定的屬性
Node attrnode=map.getNamedItem("id");
setStu(attrnode, stu);
// System.out.println(
// attrnode.getNodeName()+"="+attrnode.getNodeValue());
//獲取三級標簽
NodeList sanList=node.getChildNodes();
for(int j=0;j<sanList.getLength();j++){
Node san=sanList.item(j);
if(san.getNodeType()==Node.ELEMENT_NODE){
setStu(san, stu);
}
}
stus.add(stu);
}
}
} catch (ParserConfigurationException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (SAXException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return stus;
}
/*
*設置對象的屬性(查詢)
*/
public void setStu(Node node,Student stu){
if(node.getNodeType()==Node.ATTRIBUTE_NODE){
//取屬性節點的值
String id=node.getNodeValue();
stu.setId(Long.parseLong(id));
}else if(node.getNodeName().equals("name")){
//獲取文本節點內容
String name=node.getTextContent();
stu.setName(name);
}else if(node.getNodeName().equals("age")){
String age=node.getTextContent();
stu.setAge(Integer.parseInt(age));
}
}
/*
*增加對象方法
*/
public void addStudent(Student stu){
DocumentBuilderFactory dbf=
DocumentBuilderFactory.newInstance();
try {
DocumentBuilder builder=
dbf.newDocumentBuilder();
Document doc=
builder.parse("src/com/xml/dom/stu.xml");
Element root=doc.getDocumentElement();
//構建元素節點
Element stunode=doc.createElement("student");
//給元素設置屬性
stunode.setAttribute("id", stu.getId()+"");
Element namenode=doc.createElement("name");
namenode.setTextContent(stu.getName());
Element agenode=doc.createElement("age");
agenode.setTextContent(stu.getAge()+"");
//節點的掛載
stunode.appendChild(namenode);
stunode.appendChild(agenode);
root.appendChild(stunode);
//把內存中的樹轉化為流寫入文件
/*
*轉換器的作用就是把新生成的“樹”轉化為XML文件保存
*/
//構建轉換器工廠
TransformerFactory tff=
TransformerFactory.newInstance();
//構建轉換器
Transformer tf=tff.newTransformer();
//設置流寫入文件的編碼
tf.setOutputProperty(OutputKeys.ENCODING, "UTF-8");
//設置回車換行
tf.setOutputProperty(OutputKeys.INDENT, "yes");
//將dom以流的方式轉入文件
tf.transform(new DOMSource(doc),
new StreamResult("src/com/xml/dom/stu.xml"));
} catch (ParserConfigurationException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (SAXException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (TransformerConfigurationException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (TransformerException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
/*
*刪除對象方法
*/
public void deleteStudent(long id){
DocumentBuilderFactory dbf=
DocumentBuilderFactory.newInstance();
try {
DocumentBuilder builder=
dbf.newDocumentBuilder();
Document doc=
builder.parse("src/com/xml/dom/stu.xml");
//基于標簽名獲取所有叫該名字的標簽節點
NodeList stulist=
doc.getElementsByTagName("student");
for(int i=0;i<stulist.getLength();i++){
Node stun=stulist.item(i);
NamedNodeMap map=stun.getAttributes();
Node attr=map.getNamedItem("id");
String ids=attr.getNodeValue();
if(id==Long.parseLong(ids)){
//獲取父節點
Node parent=stun.getParentNode();
parent.removeChild(stun);
}
}
//構建轉換器工廠
TransformerFactory tff=
TransformerFactory.newInstance();
//構建轉換器
Transformer tf=tff.newTransformer();
//設置流寫入文件的編碼
tf.setOutputProperty(OutputKeys.ENCODING, "UTF-8");
//設置回車換行
tf.setOutputProperty(OutputKeys.INDENT, "yes");
//將dom以流的方式轉入文件
tf.transform(new DOMSource(doc),
new StreamResult("src/com/xml/dom/stu.xml"));
} catch (ParserConfigurationException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (SAXException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (TransformerConfigurationException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (TransformerException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
/*
*更新對象方法
*/
public void updateStudent(Student stu){
DocumentBuilderFactory factory=
DocumentBuilderFactory.newInstance();
try {
DocumentBuilder builder=
factory.newDocumentBuilder();
Document doc=
builder.parse("src/com/xml/dom/stu.xml");
NodeList list=
doc.getElementsByTagName("student");
for(int i=0;i<list.getLength();i++){
Node node=list.item(i);
NamedNodeMap map=node.getAttributes();
Node attr=map.getNamedItem("id");
String idv=attr.getNodeValue();
if(stu.getId()==Long.parseLong(idv)){
NodeList na=node.getChildNodes();
for(int j=0;j<na.getLength();j++){
Node nav=na.item(j);
if(nav.getNodeType()==Node.ELEMENT_NODE){
// System.out.println(nav.getChildNodes().item(0));//node
// System.out.println(nav.getFirstChild());//node
//System.out.println(nav.getFirstChild().getNodeValue());
if(nav.getNodeName().equals("name")){
//nav.setTextContent(stu.getName());
nav.getFirstChild().setNodeValue(stu.getName());
}else{
//nav.setTextContent(stu.getAge()+"");
nav.getChildNodes().item(0).setNodeValue(stu.getAge()+"");
}
}
}
}
}
TransformerFactory tff=
TransformerFactory.newInstance();
Transformer tf=tff.newTransformer();
tf.transform(new DOMSource(doc),
new StreamResult("src/com/xml/dom/stu.xml"));
} catch (ParserConfigurationException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (SAXException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (TransformerConfigurationException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (TransformerException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}※ SAX解析器構建,完成XML文件增、刪、改、查
※ SAX解析原理圖:

//SAX解析器遍歷xml文件
package com.xml.sax;
import java.io.IOException;
import java.util.Arrays;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.helpers.DefaultHandler;
public class SaxparserT {
public void ParseXML(){
//構建解析器工廠
SAXParserFactory factory=
SAXParserFactory.newInstance();
//開啟命名空間
factory.setNamespaceAware(true);
try {
SAXParser sax=factory.newSAXParser();
//讀取文件,同時綁定事件處理器
sax.parse("src/com/xml/dom/stu.xml",
new DefaultHandler(){
//事件處理器的相關方法
//當開始讀取xml文檔對象的時候觸發(一次)
public void startDocument ()
throws SAXException{
System.out.println("文檔開始");
}
//當讀取完根標簽結束標簽之后觸發的方法
public void endDocument ()
throws SAXException{
System.out.println("文檔結束");
}
//該方法處理的是空白文本及標簽中間內容文本
//第一個表示整個文檔內容
//第二個參數表示文本開始的角標
//第二個參數表示文本的長度
public void characters (char ch[], int start, int length)
throws SAXException{
//System.out.println("內容:"+new String(ch,start,length));
// System.out.println(new String(ch));
// System.out.println("內容:"+new String(ch,start,length)+
// "開始位置:"+start+"---長度"+length);
}
//當讀取開始標簽的時候觸發
//命名空間生效的情況下
//uri 命名空間的內容
//localName 去掉前綴之后的標簽名
//qName 標簽的完整的名字(前綴+標簽)
//命名空間不生效的情況
//uri和localName為空
//qName表示標簽的名字
public void startElement (String uri, String localName,
String qName, Attributes attributes)
throws SAXException{
// System.out.println("uri:"+uri+
// " localName:"+localName
// +" qName:"+qName);
}
//當讀取到結束標簽的時候觸發
public void endElement (String uri, String localName, String qName)
throws SAXException{
System.out.println("uri:"+uri+
" localName:"+localName
+" qName:"+qName);
}
});
} catch (ParserConfigurationException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (SAXException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
public static void main(String[] args) {
new SaxparserT().ParseXML();
}
}
//SAX解析器添加對象
package com.xml.sax;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.helpers.DefaultHandler;
import com.xml.dom.Student;
public class SaxparserT1 {
public void ParseXML(){
//構建解析器工廠
SAXParserFactory factory=
SAXParserFactory.newInstance();
try {
SAXParser sax=factory.newSAXParser();
final List<Student> list=new ArrayList<>();
//讀取文件,同時綁定事件處理器
sax.parse("src/com/xml/dom/stu.xml",
new DefaultHandler(){
private Student stu;
private boolean nameF;
private boolean ageF;
public void characters (char ch[], int start, int length)
throws SAXException{
if(nameF){
stu.setName(new String(ch,start,length));
}
if(ageF){
stu.setAge(Integer.parseInt(new String(ch,start,length)));
}
}
public void startElement (String uri, String localName,
String qName, Attributes attributes)
throws SAXException{
if(qName.equals("student")){
stu=new Student();
String id=attributes.getValue("id");
stu.setId(Long.parseLong(id));
}else if(qName.equals("name")){
nameF=true;
}else if(qName.equals("age")){
ageF=true;
}
}
public void endElement (String uri, String localName, String qName)
throws SAXException{
if(qName.equals("student")){
list.add(stu);
}else if(qName.equals("name")){
nameF=false;
}else if(qName.equals("age")){
ageF=false;
}
}
});
for(Student s:list){
System.out.println(s);
}
} catch (ParserConfigurationException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (SAXException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
public static void main(String[] args) {
new SaxparserT1().ParseXML();
}
}※ DOM4F解析器構建,完成XML文件增、刪、改、查
※ DOM4F的原理與DOM原理相同。都是構建“樹”模型。
需要導入jar包(先在項目內建立一個名為jar的Folder文件夾。直接把jar:(dom4j-1.6.1.jar)粘貼進去。然后右擊jar文件,找到Build-Path中的Add-to-Build-Path,發現JRE中多了個牛奶瓶子,說明導入成功。(jar包不能重復導入)
package com.xml.dom4j;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.UnsupportedEncodingException;
import java.util.ArrayList;
import java.util.List;
import org.dom4j.Attribute;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.OutputFormat;
import org.dom4j.io.SAXReader;
import org.dom4j.io.XMLWriter;
import com.xml.dom.Student;
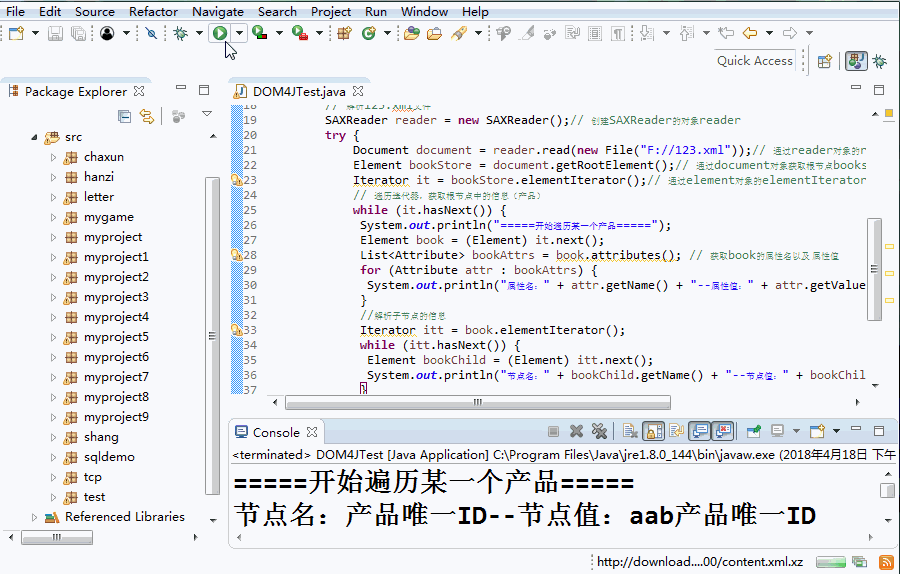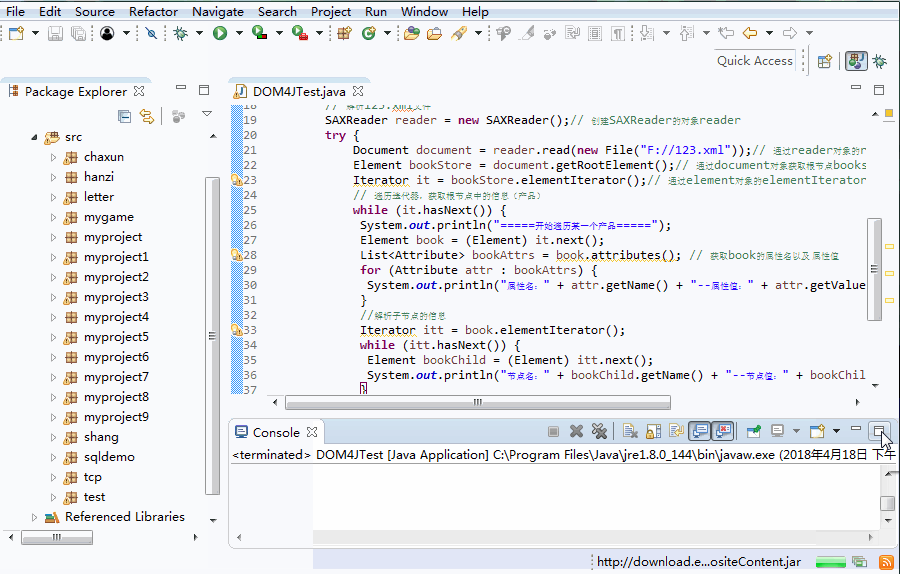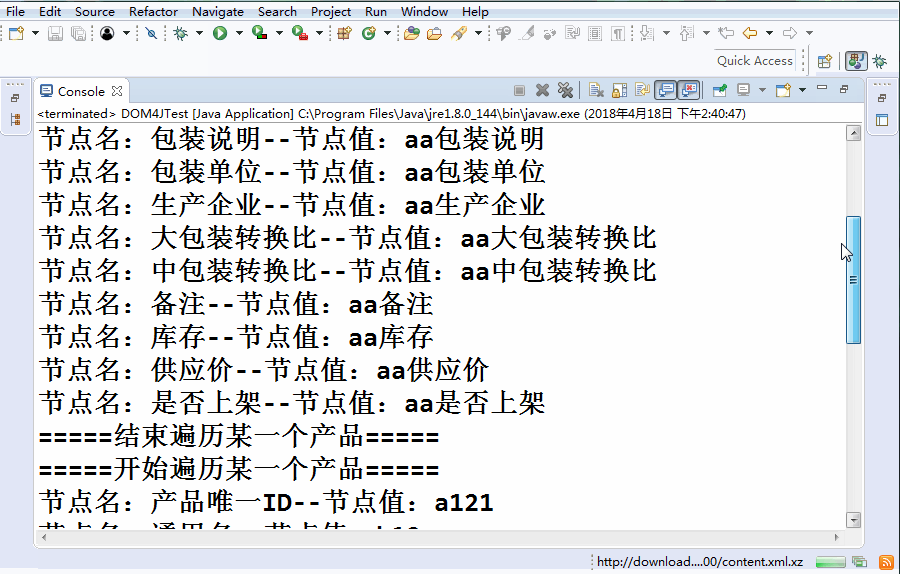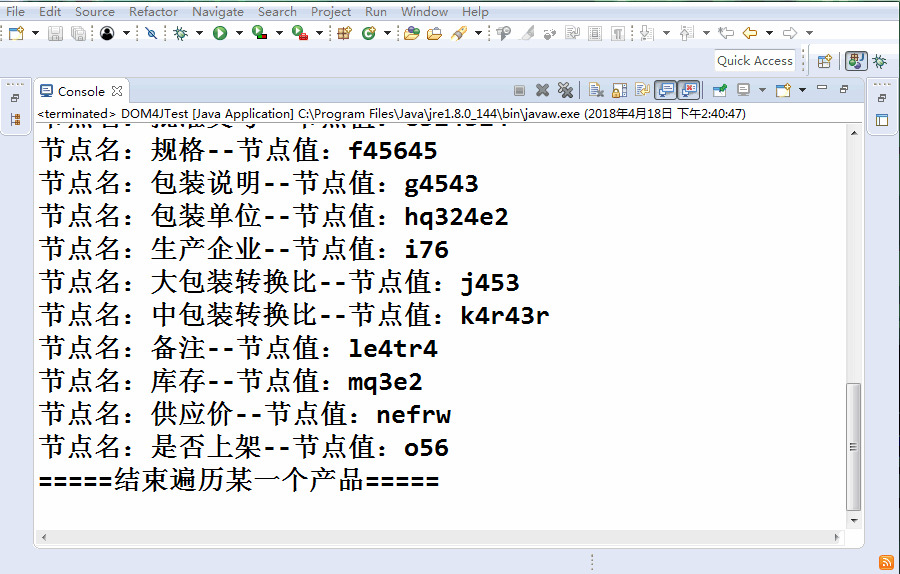
public class Dom4JTest {
public List<Student> getAllStudent(){
List<Student> list=new ArrayList<>();
//構建解析器
SAXReader dom=new SAXReader();
try {
Document doc=
dom.read("src/com/xml/dom/stu.xml");
//獲取根標簽
Element root=doc.getRootElement();
//獲取二級標簽,只獲取元素標簽,忽略掉空白的
//文本
List<Element> ers=root.elements();
for(Element er:ers){
Student stu=new Student();
//獲取名字
// String name=er.getName();
// System.out.println(name);
//獲取所有的屬性
// List<Attribute> attrs=er.attributes();
//獲取屬性的值
// System.out.println(attrs.get(0).getValue());
//獲取單個屬性
String id=er.attributeValue("id");
stu.setId(Long.parseLong(id));
List<Element> sans=er.elements();
for(Element san:sans){
if(san.getName().equals("name")){
// san.getText();
// san.getTextTrim();
// Object obj=san.getData();
stu.setName(san.getText());
}else if(san.getName().equals("age")){
stu.setAge(Integer.parseInt((String) san.getData()));
}
}
list.add(stu);
}
} catch (DocumentException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return list;
}
/*
*添加對象方法
*/
public void addStudent(Student stu){
SAXReader sax=new SAXReader();
try {
Document doc=
sax.read("src/com/xml/dom/stu.xml");
Element root=doc.getRootElement();
//添加元素的同時返回當前元素
Element stuE=root.addElement("student");
//設置元素屬性
stuE.addAttribute("id", stu.getId()+"");
Element nameE=stuE.addElement("name");
//設置文本內容
nameE.setText(stu.getName());
Element ageE=stuE.addElement("age");
ageE.setText(stu.getAge()+"");
//移除元素
//root.remove(stuE);
//第一個參數表示路徑,
//第二個參數表示格式
//不寫格式輸出的時候,新增加的內容直接一行插入
// XMLWriter writer=
// new XMLWriter(
// new FileOutputStream(
// "src/com/xml/dom/stu.xml"));
//OutputFormat format=OutputFormat.createPrettyPrint();
//docment中的tree全部轉化為一行內入寫入
OutputFormat format=OutputFormat.createCompactFormat();
XMLWriter writer=
new XMLWriter(
new FileOutputStream(
"src/com/xml/dom/stu.xml"),format);
writer.write(doc);
writer.flush();
writer.close();
} catch (DocumentException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (UnsupportedEncodingException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
/*
*刪除對象方法
*/
public void remove(long id){
SAXReader sax=new SAXReader();
try {
Document doc=
sax.read("src/com/xml/dom/stu.xml");
Element root=doc.getRootElement();
List<Element> ers=root.elements();
for(Element er:ers){
String ids=er.attributeValue("id");
if(id==Long.parseLong(ids)){
er.getParent().remove(er);
break;
}
}
OutputFormat format=
OutputFormat.createPrettyPrint();
XMLWriter writer=
new XMLWriter(
new FileOutputStream(
"src/com/xml/dom/stu.xml"),format);
writer.write(doc);
writer.flush();
writer.close();
} catch (DocumentException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (UnsupportedEncodingException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
public static void main(String[] args) {
new Dom4JTest().remove(3);
// new Dom4JTest().addStudent(
// new Student(3,"briup",55));
// List<Student> list=new Dom4JTest().getAllStudent();
// for(Student s:list){
// System.out.println(s);
// }
}
}智能推薦
通過DOM4J解析XML
Dom4j是一個簡單、靈活的開放源代碼的庫。Dom4j是由早期開發JDOM的人分離出來而后獨立開發的。與JDOM不同的是,dom4j使用接口和抽象基類,雖然Dom4j的API相對要復雜一些,但它提供了比JDOM更好的靈活性。 Dom4j是一個非常優秀的Java XML API,具有性能優異、功能強大和極易使用的特點。現在很多軟件采用的Dom4j,例如Hibernate,包括sun公司自己的JAXM...
xml解析: dom4j
目錄 一、XML解析 1.概述 2.解析方式和解析器 二、Dom4j的基本使用 1.解析原理 2.基本使用 2.常用方法 (1)SaxReader對象 (2)Document對象 (3)Element對象 三、dom4j練習 1.使用dom4j查詢xml 2.使用dom4j實現添加操作 3.使用dom4j實現在特定位置添加元素 4.使用dom4j實現修改節點的操作 5.使用dom4j實...
dom4j解析xml
一,dom4j簡介 dom4j是一個Java的XML API,是jdom的升級品,用來讀寫XML文件的。dom4j是一個十分優秀的JavaXML API,具有性能優異、功能強大和極其易使用的特點,它的性能超過sun公司官方的dom技術,同時它也是一個開放源代碼的軟件,可以在SourceForge上找到它。在IBM developerWorks上面還可以找到一篇文章,對主流的Java XML API...
dom4j解析XML文件
J2EE-07 java中配置文件的配置位置及讀取方式: 1.XML 2.properties 3.ini 存放位置: 1.src根目錄下 2.與讀取配置文件的類在同包 3.WEB-INF(或其子目錄下) XML的作用: 1.配置(1.XML,2.properties ,ini) 2.數據交換(1.XML,2.WEBService,3.json(json一般用的比較多)) 實現效果:’...
dom4j解析xml
準備階段 dom4j作為解析xml的一把利器,學習使用dom4j是必須的。 要想使用dom4j解析xml,就得先準備好dom4j文件。 這里給出一個github的下載地址:https://dom4j.github.io/,在下載時要根據自己的jdk版本“量力而行”。如果地址失效了,可以百度、谷歌搜索。 下載解壓后將dom4j對應的jar包加入到你的工程即可使用。 1、進入解...
猜你喜歡
XML解析之dom4j
使用dom4j解析xml dom4j是一個組織,針對xml解析,提供了解析器dom4j 導入dom4j的jar包 創建一個文件夾lib 把jar包復制到lib下 右鍵點擊jar包,選擇添加到path 看到jar包變成奶瓶的形狀就可以了 常用的類: SAXReader類 使用這個 類創建一個解析器 new SAXReader() Document read(String systemId) 使用這個...
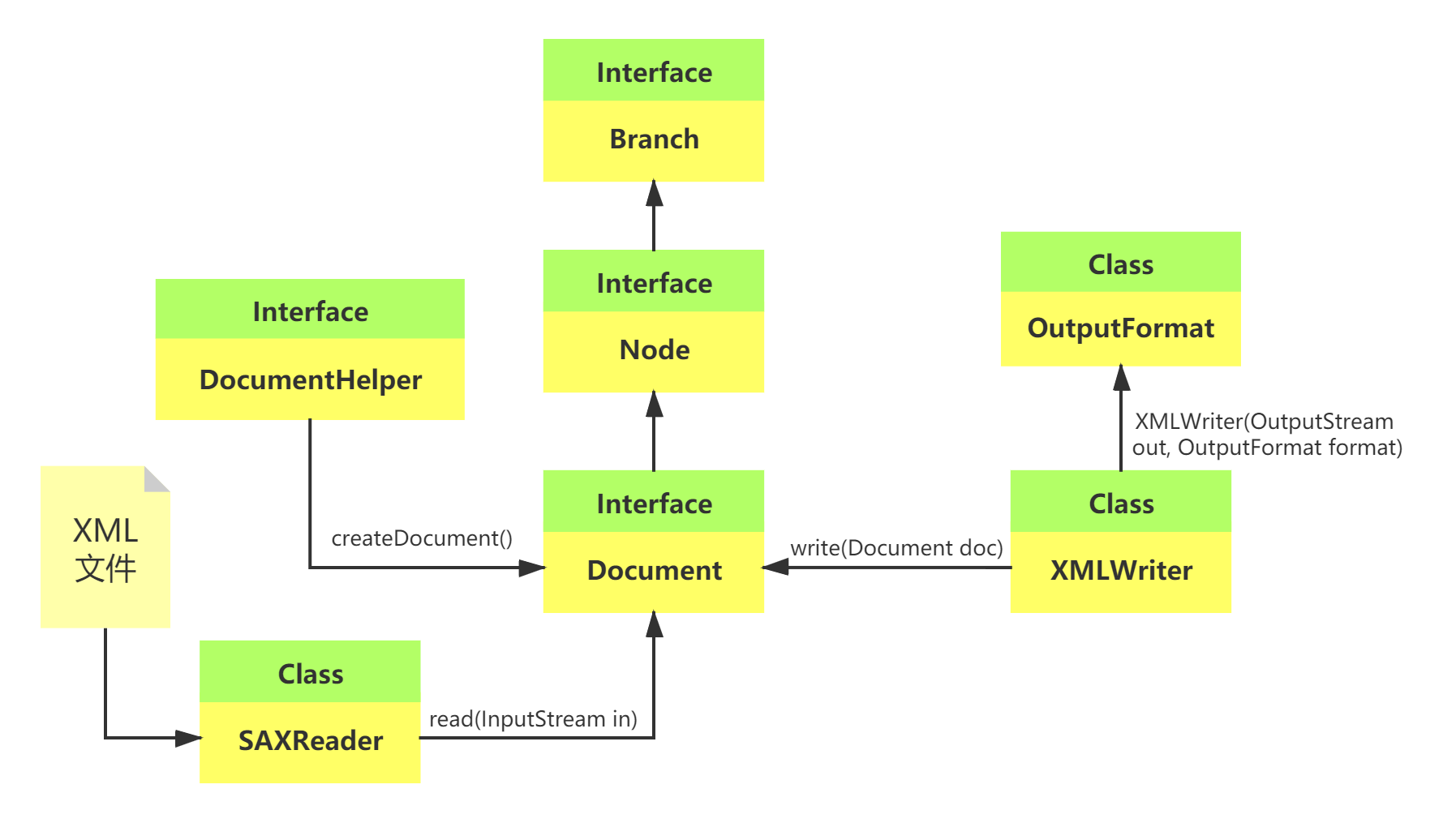
使用DOM4J解析XML
使用DOM4J解析XML DOM4J同時具備了DOM寫入和SAX讀取的操作,并做了存儲優化,使用DOM4J時要導入dom4j的開發包dom4j-x.x.x.jar。 DOM4J提供有自己的一堆實現類庫: DocumentHelper工具類:org.dom4j.DocumentHelper No 返回值 方法名 描述 1 Document createDocument() 創建新的文檔 2 Elem...

dom4j解析xml
一.什么是XML xml:extensive markup language 可擴展的標記語言。如下,就是xml 二.如何解析xml 這邊我使用dom4j解析 1.將dom4j和jaxen架包導進項目 第一步:找到這個標志,并且點擊 第二步: 第三步:選擇jar包 然后點擊apply再點確認jar包就導入完成。 2.建一個類和xml中內容對應 3.寫一個轉換的類 4.最后測試一下...

