深度學習21天實戰caffe學習筆記《7 :Caffe數據結構》
Caffe數據結構
一、基本概念

二、Blob:Caffe的基本存儲單元
- 四維數組,維度從低到高(width_,height_,channels_,num_);
- 用于存儲和交換數據;存儲數據或者權值(data)和權值增量(diff);
- 提供統一的存儲器接口,持有一批圖像或其他數據、權值、權值更新值;
- 進行網絡計算時,每層的輸入、輸出都需要通過Blob對象緩沖。
(1)基本用法
#include <vector>
#include <iostream>
//將Blob內部值保存到磁盤,或者從磁盤載入內存,可以分別通過ToProto()、FromProto()實現
#include <caffe/util/io.hpp> //存需要包含這個文件
#include <caffe/blob.hpp> #包含頭文件
using namespace caffe; #命名空間
using namespace std;
int main(void)
{
Blob<float> a; #創建Blob對象a
cout<<"Size :"<<a.shape_string()<<endl; #打印維度信息 Size :(0)
a.Reshape(1,2,3,4);
cout<<"Size :"<<a.shape_string()<<endl; #打印維度信息 Size:1 2 3 4 (24)
float *p = a.mutable_cpu_data(); #修改內部數值 mutable_cpu[gpu]_data[diff]
float *q = a.mutable_cpu_diff(); #修改內部數值 mutable_cpu[gpu]_data[diff]
for(int i = 0; i < a.count(); i ++)
{
p[i] = i; #將data初始化為1,2,3...
q[i] =a.count()-1-i ; #將diff初始化為23,22,21...
}
a.update(); #執行Update操作,將diff與data融合(這也是CNN權值更新步驟的追蹤實施者) # Update()實現 data=data-diff
BlobProto bp; #構造一個BlobProto對象
a.ToProto(&bp,true); #將a序列化,連通diff(默認不帶)
WriteProtoToBinaryFile(bp,"a.blob"); #寫入磁盤文件a.blob"
ReadProtoFromBinaryFileOrDie("a.blob",&bp2)
Blob<float> b; #新建一個Blob對象b
b.FromProto(bp2,true); #從序列化對象bp2總克隆b(連通形狀)
for(int u = 0; u < a.num(); u ++)
{
for(int v = 0; v < a.channels(); v ++)
{
for(int w = 0; w < a.height(); w ++)
{
for(int x = 0; x < a.width(); x ++)
{
cout<<"a["<<u<<"]["<< v << "][" << w << "][" << x << "] =" << a.data_at(u,v,w,x)<< endl;
#下標訪問 a[][][][]=-23、-21......21、23
}
}
}
}
cout<<"ASUM = " << a.asum_data()<< endl; #所有元素絕對值之和(L1-范數) ASUM = 288 cout<<"SUMSQ = " << a.sumsq_data()<< endl; # 平方和 (L2-范數)SUMSQ = 4600
return 0;
}(2)數據結構描述
1>、結構體的序列化/反序列化操作需要額外的編程思想,難以做到接口標準化;2>、結構體中包含變長數據時,需要更加細致的工作保證數據完整性。ProtoBuffer將變成最容易出現問題的地方加以隱藏,讓機器自動處理,提高了出的健壯性。
| 該結構描述了Blob的形狀信息 | message BlobShape { |
只包括若干int64類型值,分別表示Blob 每個維度的大小,packed表示這些值在內存 中緊密排布,沒有空洞 | repeated int64 dim = 1 [packed = true]; |
| } | |
| 該結構描述Blob在磁盤中序列化后的形態 | message BlobProto { |
| 可選,包括一個BlobShape對象 | optional BlobShape shape = 7; |
| 包括若干護墊元素, 用于存儲增量信息,元素數目由shape或 (num,channels,height,width)確定 ,這些元素在內存總緊密排布 | repeated float data = 5 [packed = true]; |
包括若干護墊元素, 用于存儲增量信息,維度與data粗細一致 | repeated float diff = 6 [packed = true]; |
| 與data并列,知識類型為double | repeated double double_data = 8 [packed = true]; |
| 與diff并列,只是內心為double | repeated double double_diff = 9 [packed = true]; |
| 可選的維度信息,新版本caffe 推薦使用shape,而不再后面的值 | // 4D dimensions -- deprecated. Use "shape" instead. |
| optional int32 num = 1 [default = 0]; | |
| optional int32 channels = 2 [default = 0]; | |
| optional int32 height = 3 [default = 0]; | |
| optional int32 width = 4 [default = 0]; | |
| } |
(3)Blob煉成法
三、Layer:Caffe的基本計算單元
前向傳播:對輸入Blob進行某種處理(有權值和騙至西安的Layer會利用這些對輸入進行處理),得到輸出Blob反向傳播:對輸出Blob的diff進行某種處理,得到輸入Blob的diff(有權值和偏置項的Layer可能也會計算Blob、偏置項Blob的 diff)
(1)數據結構描述
(2)Layer煉成法
- Layer頭文件位于include/caffe/layer.hpp中;
- Layer源文件位于src/caffe/layer.cpp中(大部分函數并沒有實現 ,只有虛函數);
- Layer的相關函數的實現在派生類,具體代碼在src/caffe/layers/*.cpp ;Layer類是一個虛基類,不能直接創建對象。
四、Net:Caffe中網站的CNN模型,包含若干Layer實例
(1)基本用法
- 描述文件 *.prototxt (models/bvlc_reference_caffenet/deploy.prototxt );
- Net中既包括Layer對象,又包括Blob對象。Blob對象用于存放每個Layer輸入/輸出中間結果,Layer根據Net描述對指定的輸入Blob進行某些處理(卷積、下采樣、全連接、非線性變換、計算代價函數等),輸出結果放到指定的輸出Blob中。輸入Blob與輸出Blob可能為同一個。
- 所有的Layer和Blob對象都用名字區分,同名的Blob表示同一個Blob對象。同名的Layer表示同一個Layer對象,Blob和Layer同名不代表他們有任何直接關系。
(2)數據結構描述
(3)Net繪成法

五、機制和策略:能干什么?怎么干?
- Blob提供數據容器的機制;
- Layer通過不同的策略使用該數據容器,實現多元化的計算處理過程,同時又提供了深度學習各種基本算法(卷積、下采樣、損失函數計算等)的機制;
- Net則利用Layer這些機制,組合為更完整的深度學習模型,提供了更加豐富的學習策略。
智能推薦
深度學習Caffe實戰筆記(7)Caffe平臺下,如何調整卷積神經網絡結構
授人以魚不如授人以漁,紅鯉魚家有頭小綠驢叫驢屢屢。至于修改網絡結構多虧了課題組大師姐老龐,在小米實習回校修整,我問她怎么修改網絡,她說改網絡就是改協議,哎呀,一語驚醒夢中人啊!老龐師姐,你真美!雖然博主之前也想過修改網絡協議試一試,鑒于一直不懂網絡結構中的各個參數是干啥的,所以一直沒去實施,這次終于開始嘗試了。 caffe平臺實現卷積神經網絡實在方便的很啊,只需要一個協議文件定義一下網...
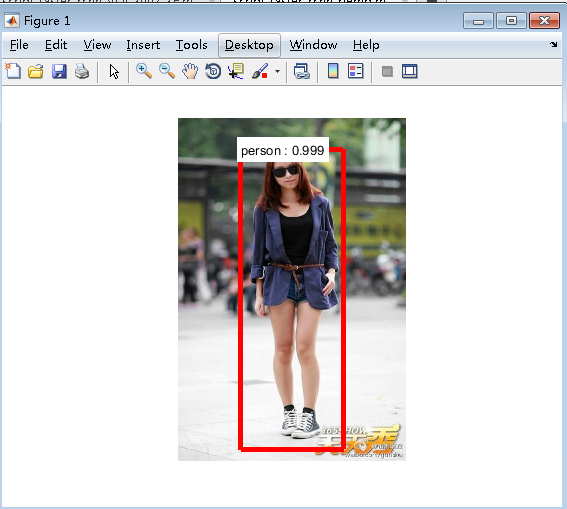
深度學習Caffe實戰筆記(21)Windows平臺 Faster-RCNN 訓練好的模型測試數據
前一篇博客介紹了如何利用Faster-RCNN訓練自己的數據集,訓練好會得到一個模型,這篇博客介紹如何利用訓練好的模型進行測試數據。 1、訓練好的模型存放位置 訓練好的模型存放在faster_rcnn-master\output\faster_rcnn_final\faster_rcnn_VOC2007_ZF,把script_faster_rcnn_demo.m文件拷貝到faster_rcnn-m...
《深度學習——實戰caffe》——caffe模型
一個完整的深度學習系統最核心的兩個方面是數據和模型。 深度學習模型通常由三部分參數組成: 可學習參數(Learnable Parameter),又稱可訓練參數、神經網絡權系數、權重,其數值由模型初始化參數、誤差反向傳播過程控制,一般不可人工干預。 結構參數(Archetecture Parameter),包括卷積層、全連接層、下采樣層數目、卷積核數目、卷積核大小等描述網絡結構參數,一旦設定好,...
深度學習Caffe實戰筆記(1)環境搭建
(1)環境搭建 從知道深度學習開始,就一直想學習使用caffe,礙于各種事情一直沒有如愿,這幾天終于找了個時間搞了一下,打算把學習的過程整理成筆記,包括環境搭建、跑車牌識別數據,跑mnist數據,用Alexnet跑自己的數據,用Siamese網絡跑mnist數據,用Siamese網絡跑自己的數據以及如何調整網絡結構等等。。。。后續我會慢慢更新,筆記的主要內容是如何使用caffe,主要側重于實戰,基...
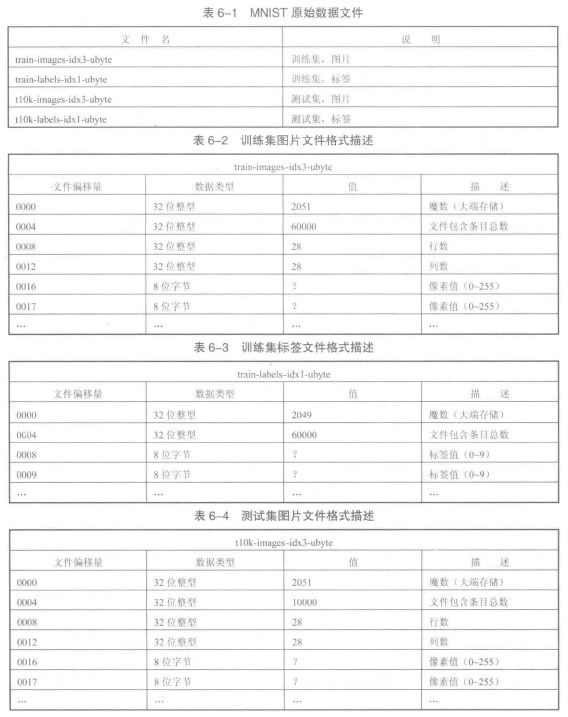
《21天實戰caffe》 讀書筆記(六)
第六天 運行手寫體數字識別例程 1、MNIST數據集 MNIST數據集包括60000個訓練集和10000個測試集,每張圖都已經進行尺寸歸一化、數字居中處理,固定尺寸為28像素*28像素。 MNIST數據集可以在Caffe源碼框架的data/mnist下用get_mnist.sh腳本下載。 MNIST原始數據為4個文件,數據格式描述見下圖。 下載到的原始數據集為二進制文件,需要轉換為LEVELDB或...
猜你喜歡

《深度學習——實戰caffe》——初識數據可視化
首先將caffe的根目錄作為當前目錄,然后加載caffe程序自帶的小貓圖片,并顯示。 圖片大小為360x480,三通道 打開examples/net_surgery/conv.prototxt文件,修改兩個地方 一是將input_shape由原來的是(1,1,100,100)修改為(1,3,100,100),即由單通道灰度圖變為三通道彩色圖。 二是將過濾器個數(num_output)由3修改為16...

深度學習caffe實戰筆記(4)Windows caffe平臺下跑cifar10
上一篇博客介紹了如何用alexnet跑自己的數據,能跑自己的數據按理說再跑cifar10應該沒問題了啊,但是想想還是要把cifar10的記錄下來,因為cifar10數據格式是屬于特殊的數據格式,需要用caffe環境把數據轉換文件編譯出來,這也是后面Siamese網絡所必須的一個步驟,說到Siamese網絡,,,,我要再哭5分鐘。好,五分鐘時間到,我們開始train。另外,如果是Ubuntu系統,跑...
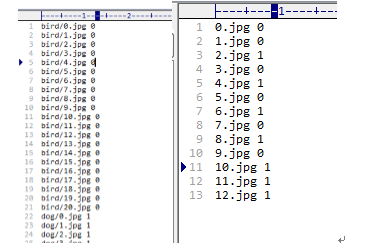
深度學習Caffe實戰筆記(2)用LeNet跑車牌識別數據
caffe實戰之“車牌識別” 上一篇博客寫了如何在cpu的情況下配置環境,配置好環境后編譯成功,就可以用caffe框架訓練卷積神經網絡了。今天介紹如何在caffe環境下,跑車牌識別的數據,利用的網絡是LeNet,這里只介紹具體caffe實戰步驟,網絡結構不做具體介紹。 1、準備數據 在caffe根目錄下的data文件夾下新建一個mine文件夾,在mine文件夾新建一個tra...
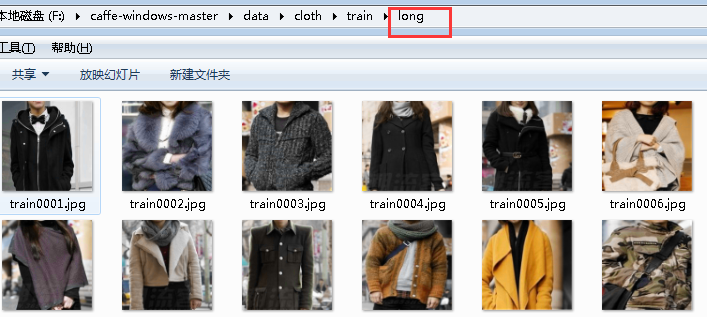
深度學習Caffe實戰筆記(3)用AlexNet跑自己的數據
上一篇博客介紹了如何在caffe框架平臺下,用LeNet網絡訓練車牌識別數據,今天介紹用AlexNet跑自己的數據,同樣基于windows平臺下,會比基于Ubuntu平臺下麻煩一些,特別是后面的Siamese網絡,說起Siamese網絡真是一把辛酸一把淚啊,先讓我哭一會,,,,,哭了5分鐘,算了,Siamese網絡的苦水等以后再倒吧,言歸正傳,開始train。 在caffe平臺下,實現用Alexn...
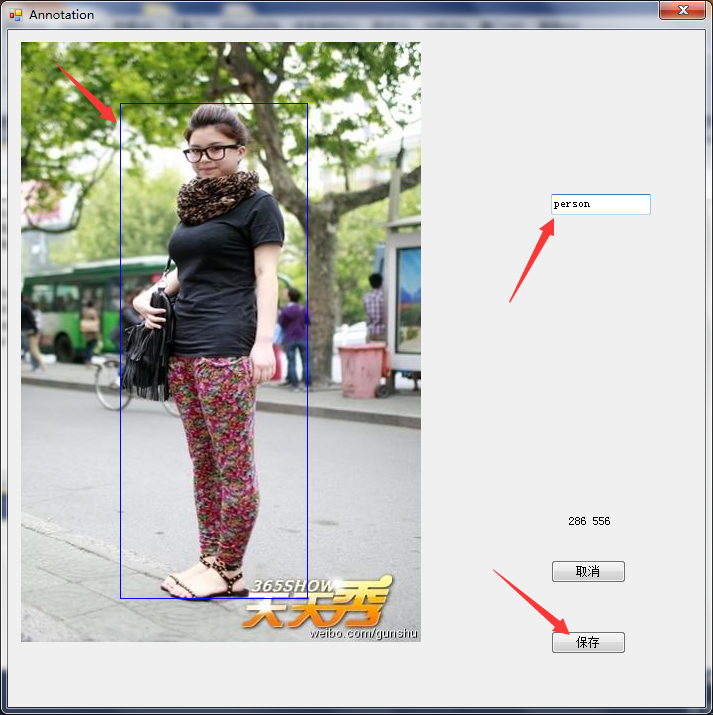
深度學習Caffe實戰筆記(19)Windows平臺 Faster-RCNN 制作自己的數據集
萬里長征第一步,就是要制作自己的數據集,過程還是比較繁瑣的,特別是標注的過程,這篇博客先介紹如果制作voc2007自己的數據集用于faster-rcnn訓練,下一篇博客介紹如何用faster-rcnn訓練自己的數據。 1、準備圖像 圖像要用.jpg或者jpeg格式的,如果是png或者其它格式,自己轉換一下就好,圖像名稱要用000001.jpg,只有和VOC2007數據集圖像名稱一致,才能最大限度的...