google 機器學習速成課程 筆記1
標簽: 機器學習 tensorflow
學習谷歌的機器學習速成課程
- 標簽:標簽是我們要預測的事物,也就是y
- 特征:特征是輸入變量,也就是x,按照如下方式指定{x1,x2,x3….,xN},合適的特征應該是具體可量化的,for example,喜歡不是可觀察且可量化的指標,鞋的美觀程度也不是,但是鞋碼和用戶點擊鞋子描述的次數是一種具體可量化的指標。
- 樣本:指數據的特定實例,有標簽樣本和無標簽樣本
- 模型:模型定義了特征和標簽之間的聯系,分為訓練和推斷階段
分為回歸和分類兩大類問題。回歸模型可預測連續值,分類問題預測離散值。
回歸問題中的誤差:
- L2正則化 平方誤差 cost = D為樣本
- MSE均方誤差 ,每個樣本的平均平方損失 cost =
降低損失
- 梯度下降法
- 隨機梯度下降法 SGD 一次抽取一個樣本
- 小批量梯度下降法 小批量SGD大約10~1000
關于梯度下降,設函數f(x,y),則梯度=[x的偏導數,y的偏導數]。梯度指向函數增長速度最快的方向,負梯度指定函數下降速度最快的方向。梯度是偏導數的矢量,損失相對于單個權重的梯度就導數。
文章中的凸函數是橫坐標為w,縱坐標為cost,畫出該圖需要給定每一個w,計算其對應的cost,這種情況下是一個凸函數,梯度下降的目標就是尋求該函數的最小值,也就是損失函數收斂的地方。
梯度下降法沿著該函數負梯度的方向下降,該方向為函數下降最快的方向,理想情況下,梯度應該是慢慢減小,最后最低點的梯度為0,函數也趨于收斂,后面函數的下降應該是比前面下降的幅度要小,然后慢慢變為0
為一個超參數,代表學習率或者步長,是一個需要調參的值。
模型收斂:總體損失不在變化或者變化緩慢
tensorflow的抽象層次

使用tensorflow.estimator API構建一個線性分類器的例子
import tensorflow as tf
#set up a linear classifier
classifier = tf.estimator.LinearClassifier()
#train the model in train_data
classifier.train(input_fn = train_input_fn,steps = 2000)
#use it to predict
predictions = classifier.predict(input_fn = predict_input_fn)泛化 : 防止過擬合,過擬合是由于模型的復雜程度超出所需要的程度造成的
訓練集、驗證集、測試集
劃分訓練和測試集合一般采取2-8原則
ps:作業題目中我發現增大批次或者降低學習率都可以降低測試損失和訓練損失的差值
驗證集
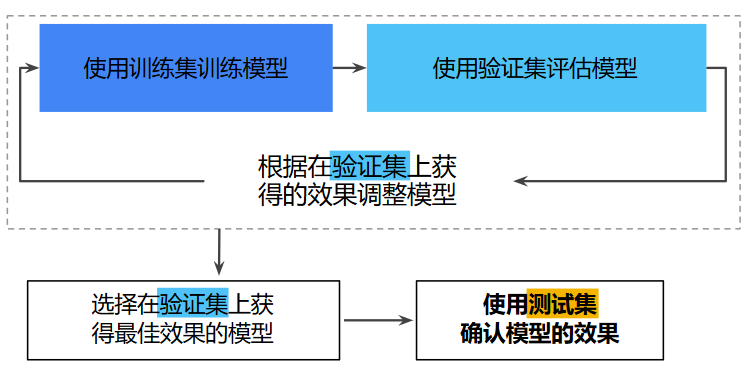
為什么需驗證集?
使用測試集和訓練集來推動模型開發迭代的流程:在每次迭代時,我們都會對訓練數據進行訓練并評估測試數據,并以基于測試數據的評估結果為指導來選擇和更改各種模型超參數,例如學習速率和特征。這樣做會導致我們不知不覺擬合測試集合。
加入驗證集后的工作流程:
智能推薦

機器學習速成課程 | 練習 | Google Development——編程練習:使用 TensorFlow 的起始步驟
使用 TensorFlow 的基本步驟 學習目標: 學習基本的 TensorFlow 概念 在 TensorFlow 中使用 LinearRegressor 類并基于單個輸入特征預測各城市街區的房屋價值中位數 使用均方根誤差 (RMSE) 評估模型預測的準確率 通過調整模型的超參數提高模型準確率 數據基于加利福尼亞州 1990 年的人口普查數據。 設置 在此第一個單元格中,我們...

機器學習速成課程 | 練習 | Google Development——編程練習:(TensorFlow) Hello World
可使用 Colaboratory 平臺直接在瀏覽器中運行編程練習(無需設置!)。Colaboratory 支持大多數主流瀏覽器,并且在 Chrome 和 Firefox 的各個桌面版本上進行了最全面的測試。如果您想下載并離線運行這些練習,請參閱有關設置本地環境的說明。 注:想要訪問TensorFlow官網以及正常使用谷歌提供的Google colab平臺的,請自行搭好梯子(VP...

機器學習速成課程 | 練習 | Google Development——編程練習:合成特征和離群值
合成特征和離群值 學習目標: 創建一個合成特征,即另外兩個特征的比例 將此新特征用作線性回歸模型的輸入 通過識別和截取(移除)輸入數據中的離群值來提高模型的有效性 我們來回顧下之前的“使用 TensorFlow 的基本步驟”練習中的模型。 首先,我們將加利福尼亞州住房數據導入 Pandas DataFrame 中: 設置 接下來,我們將設置輸入...

機器學習速成課程 | 練習 | Google Development——編程練習:特征集
特征集 學習目標:創建一個包含極少特征但效果與更復雜的特征集一樣出色的集合 到目前為止,我們已經將所有特征添加到了模型中。具有較少特征的模型會使用較少的資源,并且更易于維護。我們來看看能否構建這樣一種模型:包含極少的住房特征,但效果與使用數據集中所有特征的模型一樣出色。 設置 和之前一樣,我們先加載并準備加利福尼亞州住房數據。 任務 1:構建良好的特征集 如果只使用 2...

機器學習速成課程 | 練習 | Google Development——編程練習:特征組合
特征組合 學習目標: 通過添加其他合成特征來改進線性回歸模型(這是前一個練習的延續) 使用輸入函數將 Pandas DataFrame 對象轉換為 Tensors,并在 fit() 和 predict() 中調用輸入函數 使用 FTRL 優化算法進行模型訓練 通過獨熱編碼、分箱和特征組合創建新的合成特征 設置 首先,我們來定義輸...
猜你喜歡

機器學習速成課程 | 練習 | Google Development——編程練習:邏輯回歸
邏輯回歸 學習目標: 將(在之前的練習中構建的)房屋價值中位數預測模型重新構建為二元分類模型 比較邏輯回歸與線性回歸解決二元分類問題的有效性 與在之前的練習中一樣,我們將使用加利福尼亞州住房數據集,但這次我們會預測某個城市街區的住房成本是否高昂,從而將其轉換成一個二元分類問題。此外,我們還會暫時恢復使用默認特征。 將問題構建為二元分類問題 數據集的目標是 median_house_val...

機器學習速成課程 | 練習 | Google Development——編程練習:提高神經網絡的性能
提高神經網絡性能 學習目標:通過將特征標準化并應用各種優化算法來提高神經網絡的性能 注意:本練習中介紹的優化方法并非專門針對神經網絡;這些方法可有效改進大多數類型的模型。 設置 首先,我們將加載數據。 訓練神經網絡 接下來,我們將訓練神經網絡。 線性縮放 將輸入標準化以使其位于 (-1, 1) 范圍內可能是一種良好的標準做法。這樣一來,SGD 在一個維度中采用很大步長(或者在另一維度中采用很小步長...

機器學習速成課程 | 練習 | Google Development——編程練習:神經網絡簡介
神經網絡簡介 學習目標: 使用 TensorFlow DNNRegressor 類定義神經網絡 (NN) 及其隱藏層 訓練神經網絡學習數據集中的非線性規律,并實現比線性回歸模型更好的效果 在之前的練習中,我們使用合成特征來幫助模型學習非線性規律。 一組重要的非線性關系是緯度和經度的關系,但也可能存在其他非線性關系。 現在我們從之前練習中的邏輯回歸任務回到標準的(線性)回歸任務。...

機器學習速成課程 | 練習 | Google Development——編程練習:稀疏數據和嵌套簡介
稀疏數據和嵌入簡介 學習目標: 將影評字符串數據轉換為稀疏特征矢量 使用稀疏特征矢量實現情感分析線性模型 通過將數據投射到二維空間的嵌入來實現情感分析 DNN 模型 將嵌入可視化,以便查看模型學到的詞語之間的關系 在此練習中,我們將探討稀疏數據,并使用影評文本數據(來自 ACL 2011 IMDB 數據集)進行嵌入。這些數據已被處理成 tf.Example 格式。 設...
Udacity深度學習(google)筆記(1)——notmnist
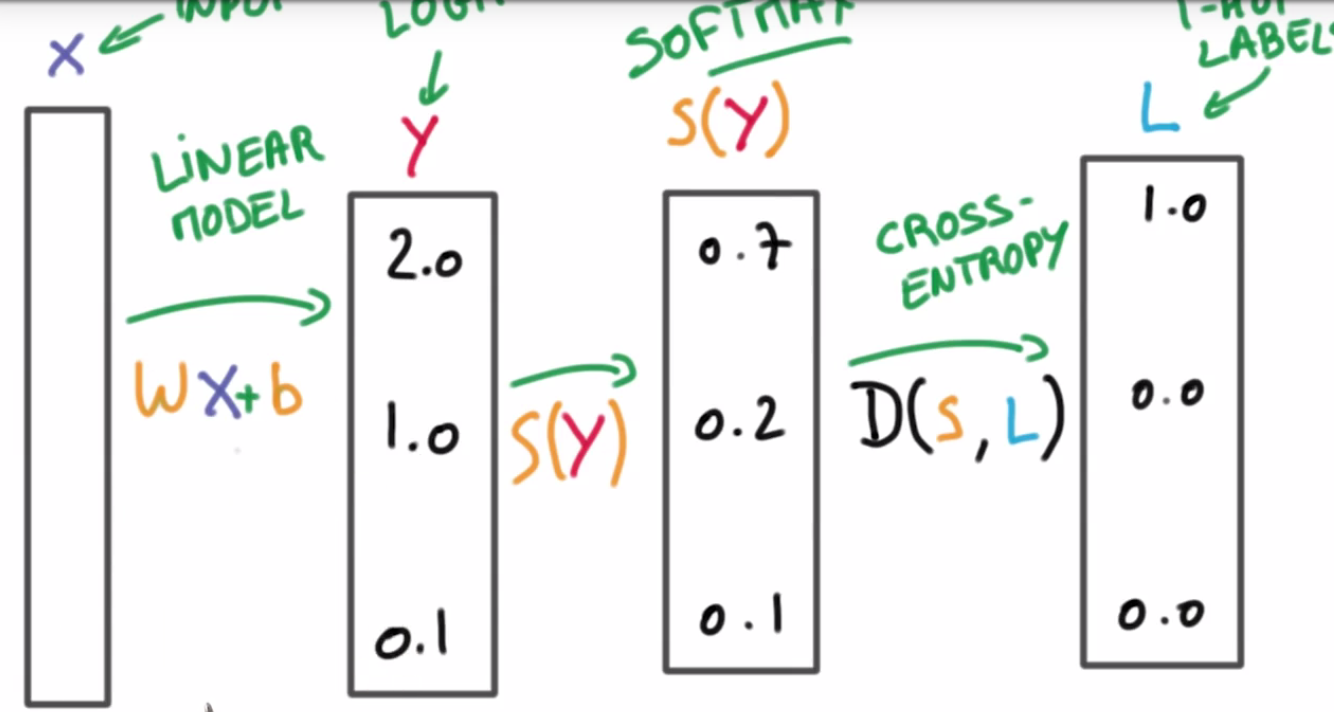
Softmax函數是將k維實數向量映射成k維(0,1)之間的實數向量(求指數后再除以指數的總和)。如果將原來的實數向量都乘以10倍,則會使得映射后的向量取值更為“極端”,即此時的學習器特別自信! One-Hot 編碼 交叉熵:不對稱 Multinomial Logistic Regression: 最小化交叉熵:梯度下降 python 3.6 中range取代了xrange...