Android開發:XML簡介及DOM、SAX、PULL解析對比
標簽: android解析方式
目錄

定義
XML(extensible Markup Language) ,是一種數據標記語言 & 傳輸格式
作用
- 對數據進行標記(結構化數據)
- 對數據進行存儲
- 對數據進行傳輸
與html的區別:html用于顯示信息;xml用于存儲&傳輸信息
XML特點
- 標簽可進行自定義 XML允許作者定義自己的標簽和文檔結構
- 自我描述性
XML文檔實例
<?xml version="1.0" encoding="ISO-8859-1"?> <!-- XML版本(1.0)和所使用編碼方法--> <note> <!-- 根元素 --> <to>George</to> <from>John</from> <heading>Reminder</heading> <body>Dont't forget the meeting!</body> <!-- 根元素下的4個子元素--> </note> <!-- 根元素的結尾 -->僅僅是一個純文本,有文本處理能力的軟件都可以處理xml
- 可拓展性
在不中斷解析、應用程序的情況下進行拓展。 - 可跨平臺數據傳輸
可在不兼容的系統之間進行交換數據,降低了復雜性 - 數據共享方便
XML以純文本進行存儲,獨立于軟件、硬件和應用程序的數據存儲方式,使得不同應用程序、軟件和硬件都能訪問xml的數據
語法
- 元素要關閉標簽
< p >this is a bitch <p> - 對大小寫敏感
< P >這是錯誤的<p> < p >這是正確的 <p> - 必須要有根元素(父元素)
<root> <kid> </kid> </root> - 屬性值必須加引號
<note date="16/08/08"> </note> - 實體引用
| 實體引用 | 符號 | 含義 |
|---|---|---|
| <; | < | 小于 |
| > ; | > | 大于 |
| &; | & | 和浩 |
| &apos; | ‘ | 單引號 |
| "; | " | 雙引號 |
元素不能使用&(實體的開始)和<(新元素的開始)
- 注釋
<!-- This is a comment -->
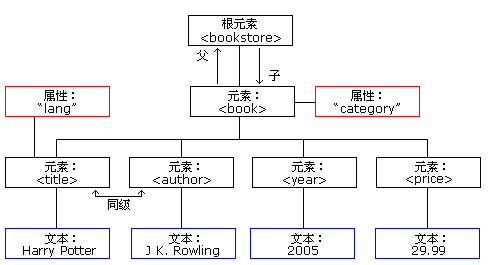
XML的元素、屬性和屬性值
文檔實例
<bookstore> <book category="CHILDREN"> <title lang="en"> Harry Potter </title> <author> JK.Rowling</author> </book> <book category="WEB"> <title lang="en"> woshiPM </title> <author>Carson_Ho</author> </book> </bookstore>其中,<bookstore>是根元素;<book>是子元素,也是元素類型之一;而<book>中含有屬性,即category,屬性值是CHILDREN;而元素<author>則擁有文本內容( JK.Rowling)
元素與屬性的差別
屬性即提供元素額外的信息,但不屬于數據組成部分的信息。范例一
<bookstore> <book category="CHILDREN"> <title lang="en"> Harry Potter </title> <author> JK.Rowling</author> </book>范例二
<bookstore> <book > <category>CHILDREN<category> <title lang="en"> Harry Potter </title> <author> JK.Rowling</author> </book>范例一和二提供的信息是完全相同的。
一般情況下,請使用元素,因為
- 屬性無法描述樹結構(元素可以)
- 屬性不容易拓展(元素可以)
使用屬性的情況:用于分配ID索引,用于標識XML元素。
實例
<bookstore> <book id = "501"> <category>CHILDREN<category> <title lang="en"> Harry Potter </title> <author> JK.Rowling</author> </book> <book id = "502"> <category>CHILDREN<category> <title lang="en"> Harry Potter </title> <author> JK.Rowling</author> </book> <bookstore>上述屬性(id)僅用于標識不同的便簽,并不是數據的組成部分
- XML元素命名規則
- 不能以數字或標點符號開頭
- 不能包含空格
- 不能以xml開頭
CDATA
不被解析器解析的文本數據,所有xml文檔都會被解析器解析(cdata區段除外)<![CDATA["傳輸的文本 "]]>PCDATA
被解析的字符數據
XML樹結構
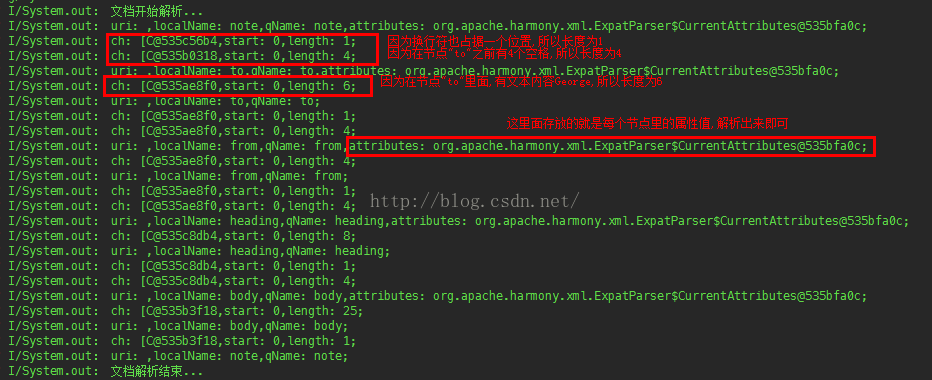
XML文檔中的元素會形成一種樹結構,從根部開始,然后拓展到每個樹葉(節點),下面將以實例說明XML的樹結構。
假設一個XML文件如下
<?xml version ="1.0" encoding="UTF-8"?> <簡歷> <基本資料> <求職意向> <自我評價> <其他信息> <聯系方式> <我的作品> </簡歷>其樹結構如下
 樹結構 .png
樹結構 .pngXML節點解釋
XML文件是由節點構成的。它的第一個節點為“根節點”。一個XML文件必須有且只能有一個根節點,其他節點都必須是它的子節點。
this 代表整個XML文件,它的根節點就是 this.firstChild 。 this.firstChild.childNodes 則返回由根節點的所有子節點組成的節點數組。
每個子節點又可以有自己的子節點。節點編號由0開始,根節點的第一個子節點為 this.firstChild.childNodes[0],它的子節點數組就是this.firstChild.childNodes[0].childNodes 。

根節點第一個子節點的第二個子節點 this.firstChild.childNodes[0].childNodes[1],它返回的是一個XML對象(Object) 。這里需要特別注意,節點標簽之間的數據本身也視為一個節點 this.firstChild.childNodes[0].childNodes[1].firstChild ,而不是一個值。

我們解析XML的最終目的當然就是獲得數據的值:this.firstChild.childNodes[0].childNodes[1].firstChild.nodeValue 。
請注意區分:節點名稱(<性別></性別>)和之間的文本內容(男)可以當作是節點,也可以當作是一個值
節點:
名稱:this.firstChild.childNodes[0].childNodes[1]
文本內容:this.firstChild.childNodes[0].childNodes[1].firstChild值:
名稱:this.firstChild.childNodes[0].childNodes[1].nodeValue
(節點名稱有時也是我們需要的數據)
文本內容:this.firstChild.childNodes[0].childNodes[1].nodeName
在了解完XML之后,是時候來學下如何進行XML的解析了
XML解析
解析XML,即從XML中提取有用的信息
解析方式
基于文檔驅動方式
- 主流方式:DOM方式
- 簡介:XML DOM(XML Document Object Model),XML文件對象模型,定義了訪問和操作xml文檔元素的方法和接口
- 工作原理: DOM是基于樹形結構的的節點的文檔驅動方法。使用DOM對XML文件進行操作時,首先解析器讀入整個XML文檔到內存中,然后解析全部文件,并將文件分為獨立的元素、屬性等,以樹結構的形式在內存中對XML文件進行表示,開發人員通過使用DOM API遍歷XML樹,根據需要修改文檔或檢索所需數據
DOM解析
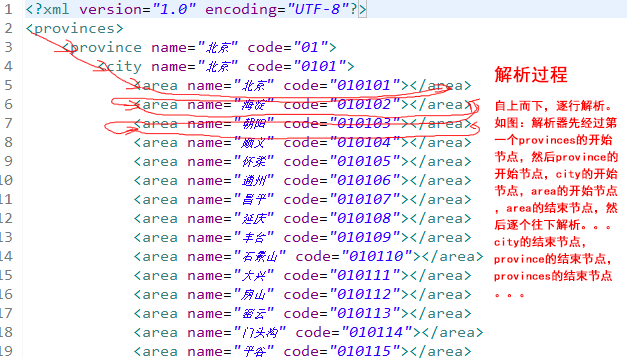
- 假設需要解析的XML文檔如下(subject.xml)
<?xml version ="1.0" encoding="UTF-8"?>` <code> <language id="1"> <name>Java</name> <usage>Android</usage> </language> <language id="2"> <name>Swift#</name> <usage>iOS</usage> </language> <language id="3"> <name>Html5</name> <usage>Web</usage> </language> </code> - 核心代碼
public static List<subject> getSubjectList(InputStream stream) { tv = (TextView)findViewById(R.id.tv); try { //打開xml文件到輸入流 InputStream stream = getAssets().open("subject.xml"); //得到 DocumentBuilderFactory 對象 DocumentBuilderFactory builderFactory = DocumentBuilderFactory.newInstance(); //得到DocumentBuilder對象 DocumentBuilder builder = builderFactory.newDocumentBuilder(); //建立Document存放整個xml的Document對象數據 Document document = builder.parse(stream); //得到 XML數據的"根節點" Element element = document.getDocumentElement(); //獲取根節點的所有language的節點 NodeList list = element.getElementsByTagName("language"); //遍歷所有節點 for (int i= 0;i<=list.getLength();i++){ //獲取lan的所有子元素 Element language = (Element) list.item(i); //獲取language的屬性(這里即為id)并顯示 tv.append(lan.getAttribute("id")+"\n"); //獲取language的子元素 name 并顯示 tv.append(sub.getElementsByTagName("name").item(0).getTextContent()+"\n"); //獲取language的子元素usage 并顯示 tv.append(sub.getElementsByTagName("usage").item(0).getTextContent()+"\n"); }
總結Dom解析的步驟
1、調用 DocumentBuilderFactory.newInstance() 方法得到 DOM 解析器工廠類實例。
2、調用解析器工廠實例類的 newDocumentBuilder() 方法得到 DOM 解析器對象
3、調用 DOM 解析器對象的 parse() 方法解析 XML 文檔得到代表整個文檔的 Document 對象。
基于事件驅動
- 主流方式:SAX、PULL方式
- 解析方式:可直接根據需要讀取所需的JSON數據,不需要像DOM方法把文檔先入到內存中
PULL解析
- 工作原理:PULL的解析方式與SAX解析類似,都是基于事件的模式。
PULL提供了開始元素和結束元素。當某個元素開始時,我們可以調用parser.nextText從XML文檔中提取所有字符數據,與SAX不同的是,在PULL解析過程中觸發相應的事件調用方法返回的是數字,且我們需要自己獲取產生的事件然后做相應的操作,而不像SAX那樣由處理器觸發一種事件的方法從而執行代碼。當解釋到一個文檔結束時,自動生成EndDocument事件。 核心代碼
public class MainActivity extends Activity { private EditText et; private Button myButton; @Override public void onCreate(Bundle savedInstanceState) { super.onCreate(savedInstanceState); setContentView(R.layout.activity_main); myButton = (Button) this.findViewById(R.id.btn01); et = (EditText) this.findViewById(R.id.edittext01); myButton.setOnClickListener(new OnClickListener() { //可變字符序列,比StringBuffer塊 StringBuilder sb = new StringBuilder(""); Resources res = getResources(); XmlResourceParser xrp = res.getXml(R.xml.subject); @Override public void onClick(View v) { int counter = 0; try { // 判斷是否到了文件的結尾 while (xrp.getEventType() != XmlPullParser.END_DOCUMENT) { //文件的內容的起始標簽開始,這里的起始標簽是subject.xml文件里面<subjects>標簽下面的第一個標簽 int eventType=xrp.getEventType(); switch (eventType) { case XmlPullParser.START_DOCUMENT: break; case XmlPullParser.START_TAG: String tagname = xrp.getName(); if (tagname.endsWith("language")) { counter++; sb.append("這是第" + counter + "種語言"+"\n"); //可以調用XmlPullParser的getAttributte()方法來獲取屬性的值 sb.append("語言id是:"+xrp.getAttributeValue(0)+"\n"); } else if(tagname.equals("name")){ //可以調用XmlPullParser的nextText()方法來獲取節點的值 sb.append("語言名稱是:"+xrp.nextText()+"\n"); } else if(tagname.equals("teacher")){ sb.append("用途是:"+xrp.nextText()+"\n"); } break; case XmlPullParser.END_TAG: break; case XmlPullParser.TEXT: break; } //解析下一個事件 xrp.next(); } //StringBuilder要調用toString()方法并顯示 et.setText(sb.toString()); } catch (XmlPullParserException e) { } catch (IOException e) { e.printStackTrace(); } } }); }
SAX解析
- 工作原理:基于事件驅動,在讀取XML文檔內容時,事件源順序地對文檔進行掃描,當掃描到文檔的開始與結束(Document)標簽、節點元素的開始與結束(Element)標簽時,直接調用對應的方法,并將狀態信息以參數的形式傳遞到方法中,然后我們可以依據狀態信息來執行相關的自定義操作。
同樣是采用事件驅動進行解析,但相比pull解析方法,采用SAX方式進行XML解析可能會較為復雜,這里就不作實例展示,有興趣的童鞋們可以自己去嘗試下,畢竟實踐出真知!
DOM、SAX、PULL三類方式對比
DOM方式
- 原理:基于文檔驅動,是先把dom全部文件讀入到內存中,構建一個主流內存的樹結構,然后使用DOM的API遍歷所有數據,調用API檢索想要的數據和操作數據。
所以,DOM方式的優缺點是: - 特點:
優點:整個文檔樹存在內存中,可對XML文檔進行操作:刪除、修改等等;可多次訪問已解析的文檔;由于在內存中以樹形結構存放,因此檢索和更新效率會更高。;
缺點:解析 XML 文件時會將整個 XML 文件的內容解析成樹型結構存放在內存中并創建新對象,比較消耗時間和內存; - 使用情境
對于像手機這樣的移動設備來講,內存是非常有限的,在XML文檔比較小、需要對解析文檔進行一定的操作且一旦解析了文檔需要多次訪問這些數據的情況下可以考慮使用DOM方式,因為其檢索和解析效率較高
SAX方式
- 原理:基于事件驅動,在讀取XML文檔內容時,事件源順序地對文檔進行掃描,當掃描到文檔的開始與結束(Document)標簽、節點元素的開始與結束(Element)標簽時,直接調用對應的方法,并將狀態信息以參數的形式傳遞到方法中,然后我們可以依據狀態信息來執行相關的自定義操作。
- 特點:
優點:解析效率高、占存少、靈活性高
缺點:解析方法復雜(API接口復雜),代碼量大;可拓展性差:無法對 XML 樹內容結構進行任何修改 - 使用情境
適用于需要處理大型 XML 文檔、性能要求較高、不需要對解析文檔進行修改且不需要對解析文檔多次訪問的場合
PULL方式
- 原理:PULL的解析方式與SAX解析類似,都是基于事件的模式。
PULL提供了開始元素和結束元素。當某個元素開始時,我們可以調用parser.nextText從XML文檔中提取所有字符數據,與SAX不同的是,在PULL解析過程中觸發相應的事件調用方法返回的是數字,且我們需要自己獲取產生的事件然后做相應的操作,而不像SAX那樣由處理器觸發一種事件的方法從而執行代碼。當解釋到一個文檔結束時,自動生成EndDocument事件。 特點:
優點:SAX的優點PULL都有,而且解析方法比SAX更加簡單
缺點:可拓展性差:無法對 XML 樹內容結構進行任何修改使用情境
適用于需要處理大型 XML 文檔、性能要求較高、不需要對解析文檔進行修改且不需要對解析文檔多次訪問的場合
同樣的使用情景,在SAX和PULL解析方法中,更加推薦PULL方法
來源:簡書
著作權歸作者所有。商業轉載請聯系作者獲得授權,非商業轉載請注明出處。
智能推薦
利用Dom,Sax,Pull三種方式解析xml文件
最近找工作,看到許多公司的要求里都寫了要會xml解析,所以就把之前的xml解析知識又重新回顧了一下,寫個小例子. 解析xml文件常用的幾種方式也就dom,sax,pull了,并且面試官經常問到的也是這三種解析方式之間的優缺點以及使用情況,先說一下這三種方式的優缺點和使用情況吧: 其實dom,sax,pull之間的優缺點網上有很多,講的搞不好比我的還要深入和貼切,不過還是要說一下,畢竟自己以后還是要...

android使用sax解析xml
隨著技術的發展,現在的web已經和以前不同了。web已經逐漸像移動的方向傾斜,作為程序員的確應該拓展一下自己的知識層面。學習各方面的知識,今天就接著前幾天的弄一下android的xml解析,這次就使用sax的方式解析xml.下面就一步一步的來做吧。 1.編寫一個簡單的xml 2.編寫pojo類 3.寫一個解析xml的類 4.進行單元測試 最后來看一下運行效果圖,這里最好弄個filter,控制臺就沒...
XML的DOM和SAX解析方式
昨天抽取并解析了一大批從微信鉤子收取到的小程序消息,它們都是用很復雜的XML表示的。平常不是很接觸XML,本文就隨便說說XML的兩種解析方式。 DOM解析方式 DOM即文檔對象模型(document object model)。根據W3C的描述,DOM是一套用于HTML和XML文檔的標準接口,它定義了文檔的邏輯結構,以及訪問或操作文檔的方式。 DOM Parser會將文檔解析為包含元素、屬性和文本...

XML解析___使用Dom or使用Sax
xml解析方式分為兩種,dom和sax dom:(Document Object Model,即對文檔對象模型)是W3C組織推薦的處理XML的一種方式 Sax:(Simple API for XML)不是官方標準,但它是xml社區事實上的標準,幾乎所有的xml解析器都支持它。 XML解析開發包 Jaxp、Jdom、dom4J 使用DOM解析XML介紹 DOM...
XML學習筆記(一)之DOM及SAX方式解析XML原理
1.XML XML 指可擴展標記語言(eXtensible Markup Language)。XML 被設計用來傳輸和存儲數據。 (1)XML 文檔形成了一種樹結構,它從"根部"開始,然后擴展到"枝葉"。 示例: &nb...
猜你喜歡
Android開發之使用PULL解析和生成XML
Android開發之使用PULL解析和生成XML 請尊重他人的勞動成果,轉載請注明出處:Android開發之使用PULL解析和生成XML 一、使用PULL解析XML 1.PULL簡介 我曾在《淺談XMl解析的幾種方式》一文中介紹了使用DOM方式,SAX方式,Jdom方式,以及dom4j的方式來解析XML。除了可以使用以上方式來解析XML文件外,也可以使用android系統內置的Pull解析器來解析...

XML解析器:DOM、SAX、DOM4J
※ XML學習 W3CSchool.chm文件 W3CSchool.chm.zip ※ XML解析器 JAXP介紹(Java API for XMLProcessing) JAXP 是J2SE的一部分,它由javax.xml、org.w3c.dom 、org.xml.sax 包及其子包組成. 在 javax.xml.parsers 包中,定義了幾個工廠類,程序員調用這些工廠類,可以得到對xml文檔...
XML文檔解析技術之SAX解析與DOM解析
一、SAX解析 SAX解析xml的方式是一種快速解析xml文檔的手段,優點是效率高,適用于解析量不大的xml文檔。 使用案例: 使用sax的方式將如下的xml文檔的用戶信息解析出來。 ...


freemarker + ItextRender 根據模板生成PDF文件
1. 制作模板 2. 獲取模板,并將所獲取的數據加載生成html文件 2. 生成PDF文件 其中由兩個地方需要注意,都是關于獲取文件路徑的問題,由于項目部署的時候是打包成jar包形式,所以在開發過程中時直接安照傳統的獲取方法沒有一點文件,但是當打包后部署,總是出錯。于是參考網上文章,先將文件讀出來到項目的臨時目錄下,然后再按正常方式加載該臨時文件; 還有一個問題至今沒有解決,就是關于生成PDF文件...