java -xml約束與解析簡介
標簽: java學習
1.xml的約束的種類:一般有dtd以及xsd,dtd對于元素的格式并無法規定,如格式而xsd對于
要會讀懂名稱空間,看懂前綴即可。
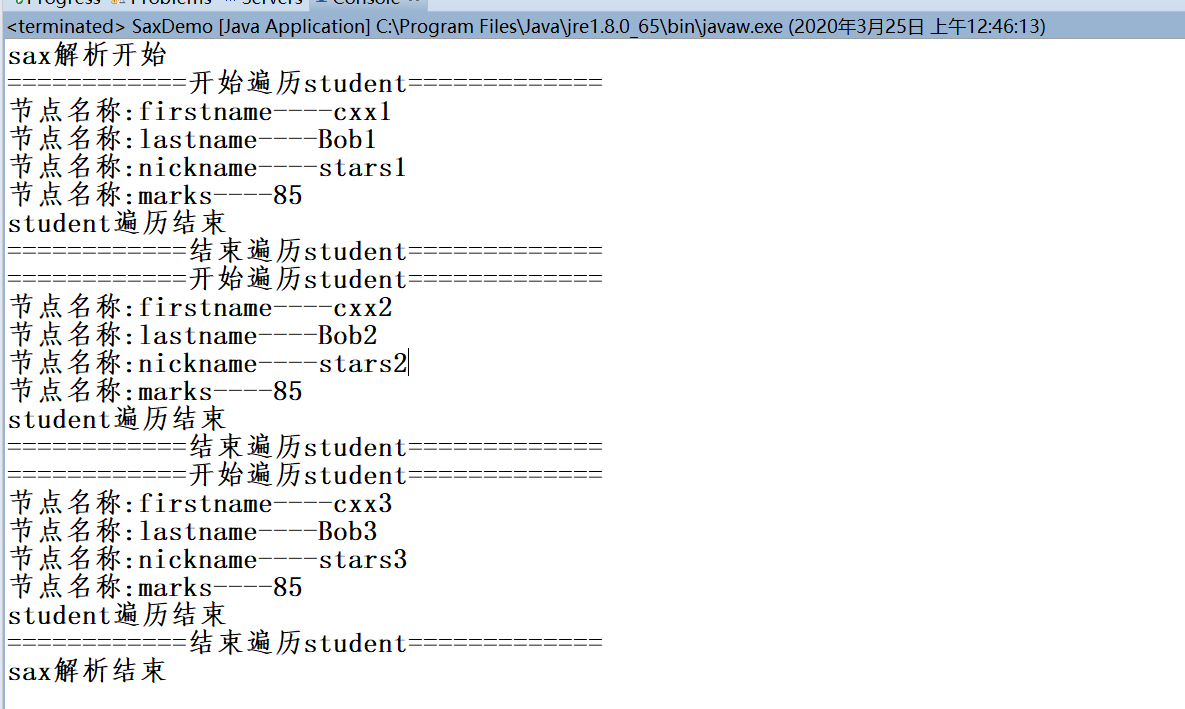
2.xml解析的方式:有dom以及sax,sax是逐行讀取,然后會釋放內存資源,所以不適合CRUD,通常用于移動端或者小型設備,優點是占內存少。dom即是前面javaScript的dom技術,把一顆dom樹讀取進內存,
缺點內存占用大,優點crud方便,多用于服務器。
2.1dom的實現,常見xml的解析器:分別有jaxp,dom4j(最好用),jsoup以及pull(移動端,sax方式)
這里我們使用的是jsoup:
步驟如下:導入jar包,獲取doc對象,獲取ele對象,讀取數據即可。
小例子:
public class JsoupDemo {
public static void main(String[] args) throws IOException {
String path = Jsoup.class.getClassLoader().getResource("student.xml").getPath();
Document document = Jsoup.parse(new File(path), "utf-8");
Elements name = document.getElementsByTag("name");
System.out.println(name.size());
}
}
小結:
Jsoup.parse的參數可以有URL+超時時間,文件+格式,或者直接一整串xml內容,即不用外部xml文件。
其中URL+超時時間 即是爬蟲中常用的方式,利用jsoup爬取解析xml/html。
Jsoup的文檔要會看,里面定義了一些接口方便操作獲取html里面的元素,注意各個對象的繼承關系,這個關系在Html DOM下面好像沒有這種特別明顯的關系
在jsoup下卻十分分明,理解起來,document每次都往上獲取內容元素,即每個元素都會有Node。
java.lang.Object
org.jsoup.nodes.Node
org.jsoup.nodes.Element
org.jsoup.nodes.Document(類繼承關系)
智能推薦
Java解析xml方法
我在模擬tomcat的過程中需要解析xml,所以在此總結下常用的sax/dom,Dom4j,jsoup等。 其實sax/dom使用有點復雜,建議使用DOM4j等技術。 這里sax和dom還有Dom4j借鑒于:https://blog.csdn.net/m0_37499059/article/details/80505567 先看xml demo.xml SAX 運行結果 DOM 運行結果 Dom4...
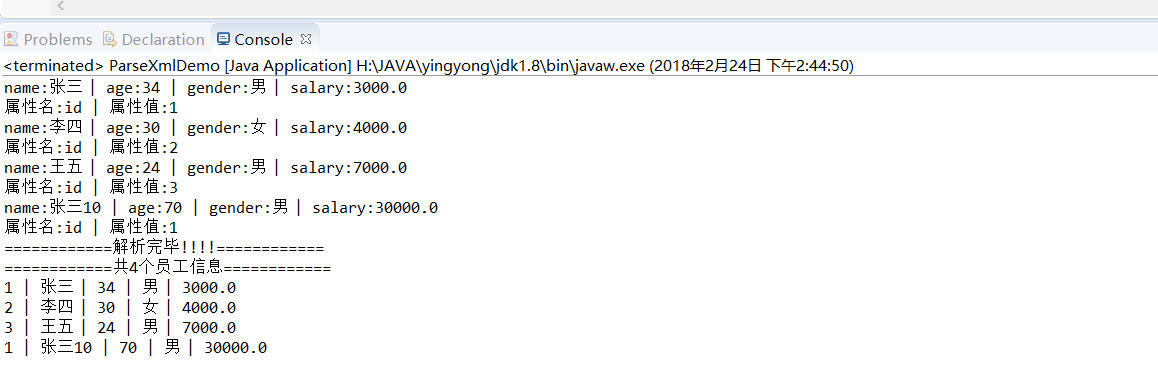

java解析xml文件
JDK API中提供了3種方式解析XML,分別為DOM、SAX、XPath。 目錄: DOM XPath:Mybaties中采用XPath方式解析XML文件的配置信息。 SAX 一.DOM studentx.xml XMLParser.java 三.XPath方式 users.xml...
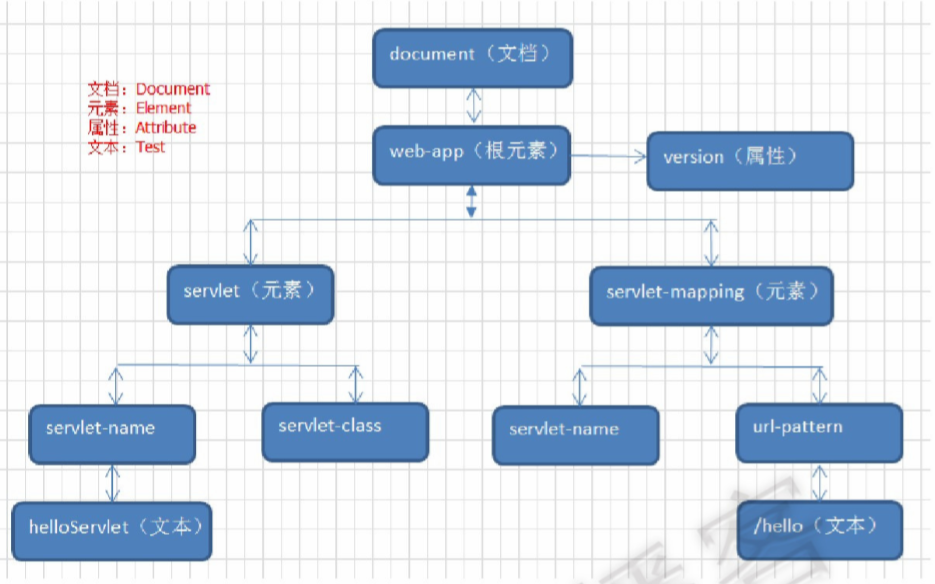
Java解析XML
XML解析方式 (1)DOM解析:解析器把**整個**XML文件加載到內存,并生成一個Document對象。 優點:元素與元素之前保持依賴管理,可以對其進行CRUD操作。 缺點:當XML文件過大時,可能會出現內存溢出問題。 (2)SAX解析:一種速度更快、更有效的方法。它逐行掃描文檔,一邊掃描一邊解析。基于事件驅動進行具體解析,每執行一行,都將觸發對應的事件。 優點:處理速度很快,可以處理大文件。...
猜你喜歡
java解析xml
結構 需要的jar依賴 commons-lang3-3.1.jar dom4j-1.6.1.jar jar 依賴下載,也可以maven,中央倉庫找找吧 https://download.csdn.net/download/qq_41463655/11133055 test.xml java 運行結果...
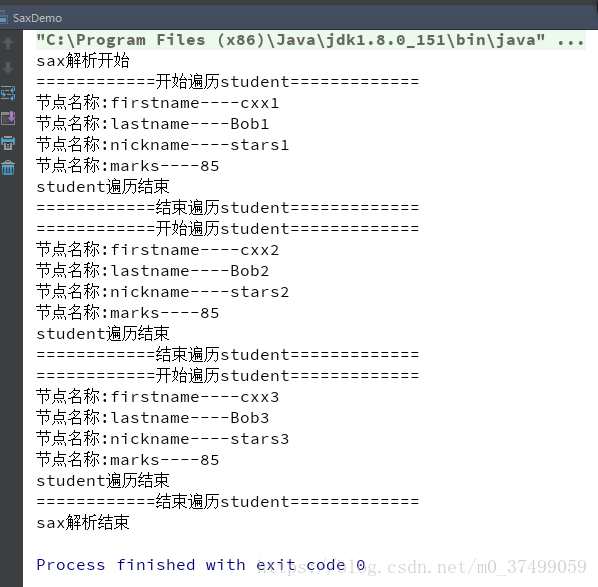
Java解析XML
<?xml version="1.0" encoding="utf-8" ?> cxx1 Bob1 stars1 85 cxx2 Bob2 stars2 85 cxx3 Bob3 stars3 85 package com.cxx.xml; import org.w3c.dom.*; import javax.xml.parsers.Docume...
【java】解析XML
談到解析xml,大部分人都會推薦您使用dom4j,這里給出官方地址:https://dom4j.github.io/ 筆者下載的是dom4j-2.1.1,注意java的版本要求至少為java 8. 現在介紹一下需求: 有下面的代碼,下面的代碼主要的問題在于參數都被硬編碼到了java代碼里面,每次都需要修改java代碼才能修改參數,筆者想用xml的方式保存這些參數信息,代替這種硬編碼的方...


freemarker + ItextRender 根據模板生成PDF文件
1. 制作模板 2. 獲取模板,并將所獲取的數據加載生成html文件 2. 生成PDF文件 其中由兩個地方需要注意,都是關于獲取文件路徑的問題,由于項目部署的時候是打包成jar包形式,所以在開發過程中時直接安照傳統的獲取方法沒有一點文件,但是當打包后部署,總是出錯。于是參考網上文章,先將文件讀出來到項目的臨時目錄下,然后再按正常方式加載該臨時文件; 還有一個問題至今沒有解決,就是關于生成PDF文件...