XML介紹及DOM解析&SAX解析——學習筆記
標簽: xml dom解析 JDOM SAX解析 DOM4J
目錄
一、XML簡介
(1)XML和HTML
XML 被設計用來傳輸和存儲數據。
HTML 被設計用來顯示數據。
(2)什么是XML
- XML 指可擴展標記語言(EXtensible Markup Language).
- XML 是一種很像HTML的標記語言
- XML 的設計宗旨是傳輸數據,而不是顯示數據。
- XML 標簽沒有被預定義。需要自行定義標簽
- XML 被設計未具有自我描述性
- XML 是W3C的推薦標準
二、XML元素VS節點
節點包括元素節點、屬性節點、文本節點;
元素一定是節點,但節點不一定是元素;

元素節點:student name sex age
屬性節點:id="001"
文本節點:張三
三、DOM方式解析XML原理
基于DOM(Document Object Model,文檔對象模型)解析方式,是把整個XML文檔加載到內存,轉換成DOM樹,因此應用程序可以隨機的訪問DOM樹的任何數據;
優點:靈活性強,速度快;
缺點:消耗資源比較多;
dom解析:

student2.xml
<?xml version="1.0" encoding="UTF-8"?>
<students>
<student>
<name id="001">張三</name>
<sex>男</sex>
<age>20</age>
</student>
<student>
<name id="002">李四</name>
<sex>女</sex>
<age>22</age>
</student>
</students>DOM2.java
package com.java1234.xml;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.NamedNodeMap;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
public class DOM2 {
public static void printNodeAttr(Node node) {
NamedNodeMap nameNodeMap = node.getAttributes();
for(int i=0;i<nameNodeMap.getLength();i++) {
Node attrNode = nameNodeMap.item(0);
System.out.println(attrNode.getNodeName()+":"+attrNode.getFirstChild().getNodeValue());
}
}
public static void main(String[] args) {
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
try {
DocumentBuilder builder = factory.newDocumentBuilder();
Document doc = builder.parse("src/student2.xml");
NodeList nodeList = doc.getElementsByTagName("students");
Element element = (Element)nodeList.item(0);
NodeList nodes = element.getElementsByTagName("student");
for(int i=0;i<nodes.getLength();i++) {
Element e = (Element)nodes.item(i);
System.out.println("姓名:"+e.getElementsByTagName("name").item(0).getFirstChild().getNodeValue());
printNodeAttr(e.getElementsByTagName("name").item(0));
System.out.println("性別:"+e.getElementsByTagName("sex").item(0).getFirstChild().getNodeValue());
System.out.println("年齡:"+e.getElementsByTagName("age").item(0).getFirstChild().getNodeValue());
System.out.println("==============");
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
四、SAX方式解析XML原理
SAX 的工作原理簡單地說就是對文檔進行順序掃描,當掃描到文檔(document)開始與結束、元素(element) 開始與結束、文檔(document)結束等地方時通知事件處理函數,由事件處理函數做相應動作,然后繼續同 樣的掃描,直至文檔結束。
優點:消耗資源比較少;適合大文件解析;
缺點:只能讀取不能修改;開發復雜;

student.xml
<?xml version="1.0" encoding="UTF-8"?>
<student>
<name id="001">張三</name>
<sex>男</sex>
<age>20</age>
</student>student.java
package com.java1234.model;
public class Student {
private String id;
private String name;
private String sex;
private int age;
//...get set方法這里省略了,代碼需加入
}
SAX02.java
package com.java1234.com;
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.helpers.DefaultHandler;
public class SAX02 extends DefaultHandler{
@Override
public void startDocument() throws SAXException {
System.out.println("<?xml version=\"1.0\" encoding=\"UTF-8\"?>");
}
@Override
public void endDocument() throws SAXException {
System.out.print("\n 掃描文檔結束");
}
@Override
public void startElement(String uri, String localName, String qName,
Attributes attributes) throws SAXException {
System.out.print("<");
System.out.print(qName);
if(attributes!=null){
for(int i=0;i<attributes.getLength();i++){
System.out.print(" "+attributes.getQName(i)+"=\""+attributes.getValue(i)+"\"");
}
}
System.out.print(">");
}
@Override
public void endElement(String uri, String localName, String qName)
throws SAXException {
System.out.print("</");
System.out.print(qName);
System.out.print(">");
}
@Override
public void characters(char[] ch, int start, int length)
throws SAXException {
System.out.print(new String(ch,start,length));
}
public static void main(String[] args) throws Exception{
SAXParserFactory factory=SAXParserFactory.newInstance();
SAXParser parser=factory.newSAXParser();
parser.parse("src/student.xml", new SAX02());
}
}
執行結果:

五、JDOM工具解析
JDOM 是一種使用 XML(標準通用標記語言下的一個子集) 的獨特 Java 工具包,用于快速開發 XML 應用 程序。
JDOM 官方網站:http://www.jdom.org/
準備jar包

解析文檔demo
package com.java1234.com;
import java.io.IOException;
import java.util.List;
import org.jdom2.Document;
import org.jdom2.Element;
import org.jdom2.JDOMException;
import org.jdom2.input.SAXBuilder;
public class JDOM02 {
public static void main(String[] args) throws JDOMException, IOException {
SAXBuilder builder = new SAXBuilder();
Document document = builder.build("src/students.xml");
Element students = document.getRootElement();
List<Element> studentList = students.getChildren("student");
for(int i=0;i<studentList.size();i++) {
Element student = (Element)studentList.get(i);
String id = student.getAttributeValue("id");
String name = student.getChildText("name");
String sex = student.getChildText("sex");
String age = student.getChildText("age");
System.out.println("學號:"+id+";姓名:"+name+";性別:"+sex+";年齡:"+age);
}
}
}生成文檔demo:
package com.java1234.com;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import org.jdom2.Attribute;
import org.jdom2.Document;
import org.jdom2.Element;
import org.jdom2.output.XMLOutputter;
public class JDOM01 {
public static void main(String[] args) {
Element student = new Element("student");
Attribute id = new Attribute("id","001");
Attribute aa = new Attribute("aa","xx");
student.setAttribute(id);
student.setAttribute(aa);
Element name = new Element("name");
name.setText("張三");
student.addContent("name");
Element sex = new Element("sex");
sex.setText("男");
student.addContent(sex);
Element age = new Element("age");
age.setText("20");
student.addContent(age);
Document document = new Document(student);
XMLOutputter out = new XMLOutputter();
out.setFormat(out.getFormat().setEncoding("UTF-8"));
try {
out.output(document, new FileOutputStream("src/student2.xml"));
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
六、DOM4J工具解析
dom4j 是一個 Java 的 XMLAPI,類似于 jdom,用來讀寫 XML 文件的。dom4j 是一個非常非常優秀的 JavaXML API,具有性能優異、功能強大和極端易用使用的特點,同時它也是一個開放源代碼的軟件,可以在 SourceForge 上找到它。在 IBMdeveloperWorks 上面可以找到一篇文章,對主流的 JavaXMLAPI 進行的性能、功能和易用性 的評測,dom4j 無論在哪個方面都是非常出色的。如今你可以看到越來越多的 Java 軟件都在使用 dom4j 來讀寫 XML,特別值得一提的是連 Sun 的 JAXM 也在用 dom4j。這是必須使用的 jar 包, Hibernate 用它來讀寫配置文 件。
DOM4J 官方網站:http://www.dom4j.org
準備jar包

生成文檔demo
package com.java1234.com;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.UnsupportedEncodingException;
import org.dom4j.Document;
import org.dom4j.DocumentHelper;
import org.dom4j.Element;
import org.dom4j.io.OutputFormat;
import org.dom4j.io.XMLWriter;
public class DOM4J01 {
public static void main(String[] args) {
Document document = DocumentHelper.createDocument();
Element studentElement=document.addElement("student");
studentElement.addAttribute("id", "001");
studentElement.addAttribute("aa", "xx");
Element name=studentElement.addElement("name");
name.setText("張三");
Element sex=studentElement.addElement("sex");
sex.setText("男");
Element age=studentElement.addElement("age");
age.setText("20");
OutputFormat format=OutputFormat.createPrettyPrint();
format.setEncoding("UTF-8");
try {
XMLWriter writer=new XMLWriter(new FileOutputStream("src/student3.xml"),format);
writer.write(document);
writer.close();
} catch (UnsupportedEncodingException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
解析文檔demo
package com.java1234.xml;
import java.util.Iterator;
import org.dom4j.Document;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
public class DOM4J02 {
public static void main(String[] args) throws Exception{
SAXReader saxReader=new SAXReader();
Document document=saxReader.read("src/students.xml");
Element rootElement=document.getRootElement();
Iterator iter=rootElement.elementIterator();
while(iter.hasNext()){
Element studentElement=(Element)iter.next();
System.out.println("學號:"+studentElement.attributeValue("id"));
System.out.println("姓名:"+studentElement.elementText("name"));
System.out.println("性別:"+studentElement.elementText("sex"));
System.out.println("年齡:"+studentElement.elementText("age"));
System.out.println("=========");
}
}
}
智能推薦
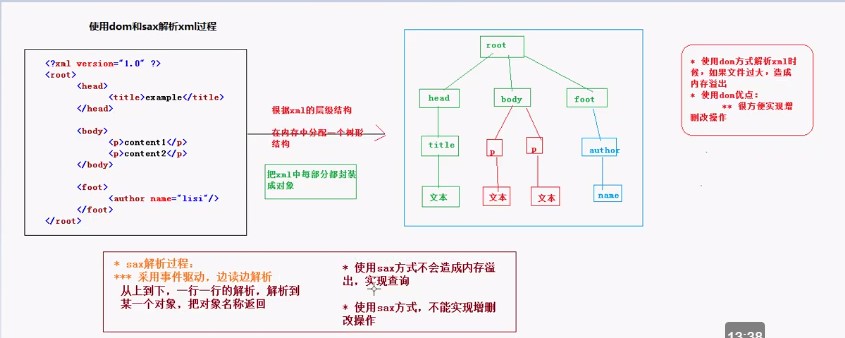
XML(三):xml的解析技術:dom和sax
1. 解析過程圖及優缺點 2.針對dom和sax的解析器 3.JAXP 使用 1)javax.xml.parsers包下有四個類: DocumentBuilder和DocumentBuilderFactory、 SaxParser和SaxParserFactory 2)步驟:...
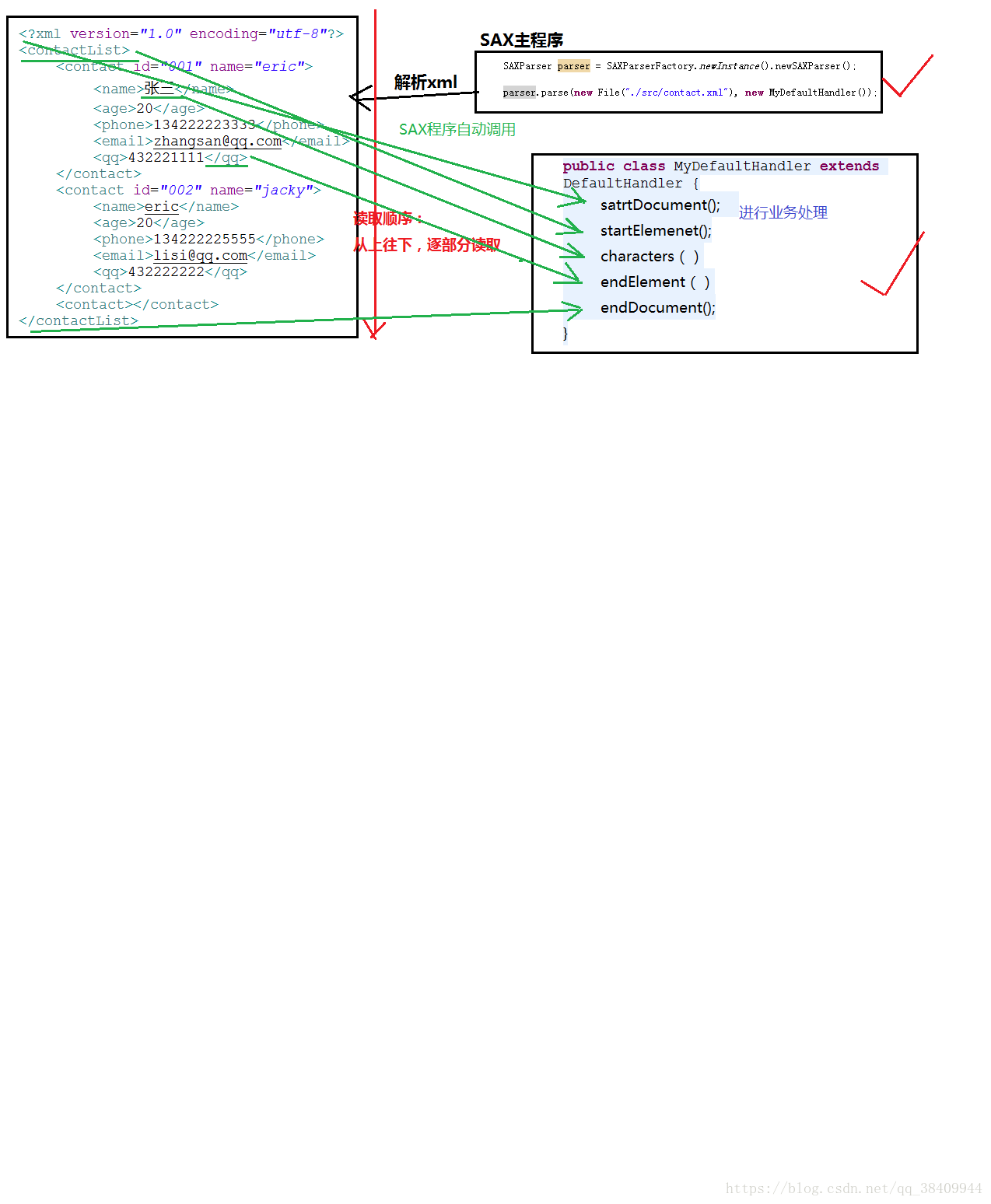
XML的SAX解析以及DOM解析和SAX解析區別
前言: XML解析工具 老樣子,三個問題: SAX是什么? 也是用來解析XML的 SAX解析工具- 內置在jdk中。org.xml.sax.* SAX運用場景? SAX解析原理: 加載一點,讀取一點,處理一點。對內存要求比較低。 SAX解析工具核心: 核心的API: 參數一: File:表示 讀取的xml文件。 參數二: DefaultHandler: SAX事件處理程序。使用DefaultHan...
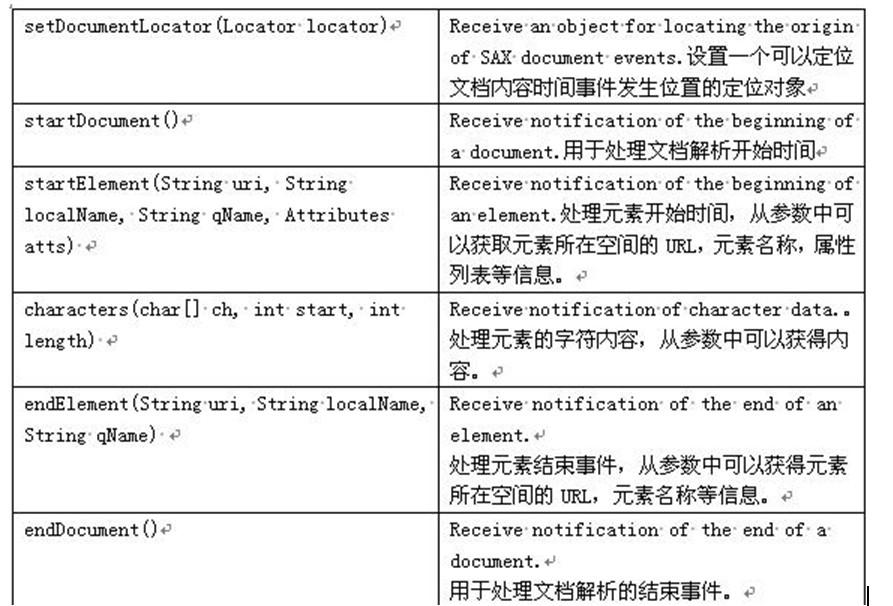
android SAX解析XML
SAX(Simple APIfor XML)解析器是一種基于事件的解析器,事件驅動的流式解析方式是,從文件的開始順序解析到文檔的結束,不可暫停或倒退。它的核心是事件處理模式,主要是圍繞著事件源以及事件處理器來工作的。當事件源產生事件后,調用事件處理器相應的處理方法,一個事件就可以得到處理。在事件源調用事件處理器中特定方法的時候,還要傳遞給事件處理器相應事件的狀態信息,這樣事件處理器才能夠根據提供的...
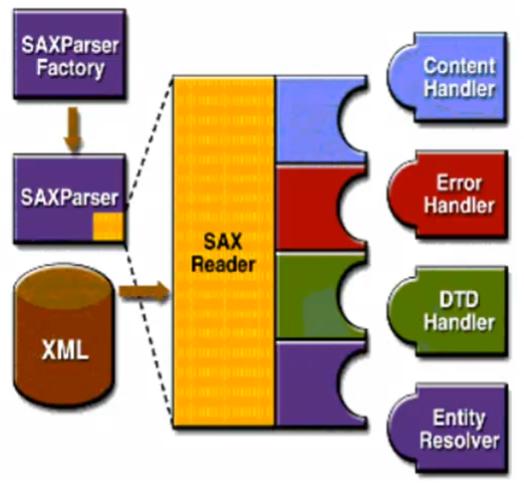
android SAX解析XML
SAX(Simple API for XML)是一個解析速度快并且占用內存少的xml解析器,非常適合用于Android等移動設備。 SAX解析XML文件采用的是事件驅動,順序讀取XML文件,邊加載邊解析。也就是說,它并不需要解析完整個文檔,在按內容順序解析文檔的過程中,SAX會判斷當前讀到的字符是否合法XML語法中的某部分,如果符合就會觸發事件。(如:當遇到像文件開頭,文檔結束,或者標簽開頭與標簽...

XML的SAX解析
SAX是一個順序執行,事件驅動的解析方法(事件驅動,簡單地說就是你點什么按鈕(即產生什么事件)) SAX的工作原理; DOM解析博客地址連接:DOM解析 SAX與DOM解析的優點;SAX解析適合較大的XML文件解析,DOM可以增加節點 SAX解析的主要方法; JAVA...
猜你喜歡
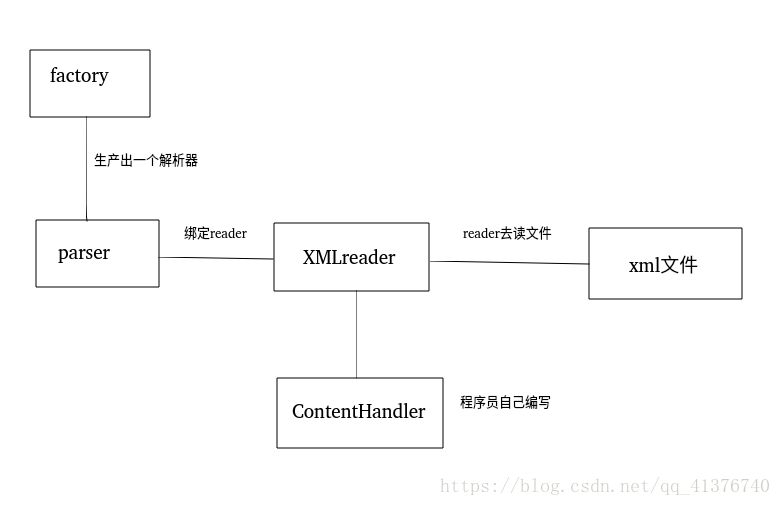
SAX-解析XML
基于SAX的xml解析 sax通常用來進行查找,就是搜索使用,大概流程如下 解析器工廠 解析器 XMLReader 處理器ContentHandler,這部分需要程序員自己寫 進行遍歷和指定位置查找 小結 SAX的優勢在于,找多少就加載多少,不會一下子擠滿內存,但是缺點是比較麻煩- -,處理部分 得程序員自己手寫,其實也還好.做個筆記把...


SAX解析XML
sax解析xml文檔是邊讀邊解的,解析時是按照提前設置好的事件處理方式來執行的。如果你在解析時,想回到前面的節點再次進行解析,對不起做不到。sax的解析方式就決定了它只能做讀的操作,不能做修改、添加、刪除的操作。 sun公司將sax解析的事件分為ContentHandler(內容事件),ErrorHandler(錯誤事件),DTDHandler(DTD約束事件),EntityResolver(實體...


freemarker + ItextRender 根據模板生成PDF文件
1. 制作模板 2. 獲取模板,并將所獲取的數據加載生成html文件 2. 生成PDF文件 其中由兩個地方需要注意,都是關于獲取文件路徑的問題,由于項目部署的時候是打包成jar包形式,所以在開發過程中時直接安照傳統的獲取方法沒有一點文件,但是當打包后部署,總是出錯。于是參考網上文章,先將文件讀出來到項目的臨時目錄下,然后再按正常方式加載該臨時文件; 還有一個問題至今沒有解決,就是關于生成PDF文件...